一网打尽面试题
个人项目深入,难点和亮点
怎样实现组建库、怎样维护组建库,有什么难点?怎么设计?二次定制遇到哪些问题?
cli 工具?核心实现需要什么库?有哪些实践和应用?
webpack 优化,模块联邦?和 vite、snowpack 的区别?webpack5 有什么升级?延伸 UMD/CMD/AMD/COMMONJS/ESMODULE 区别?再延伸出 babel 编译 AST?loader 和 plugin?treeshaking?
前端微服务 qiankun,原理?沙箱隔离?有哪些弊端?怎么解决?公有组件怎么共享?模块间怎么通信?其他微前端方案?
nestjs 相关问题,延伸出 node 相关问题,如 express、koa 等。再延伸 protobuff、grpc 服务等问题?为什么使用 GraphQL?和 restful 的区别?
flutter 简单原理、蓝牙问题、表盘问题怎么优化的?一些 flutter 面试问题、getx 是什么?原理?MQTT 相关问题?
electron 相关问题,主进程和渲染进程,怎样解决视频卡顿问题?ffpmeg 做了什么?跨平台打包遇到什么问题?怎么解决的?
监控系统,设计?上报哪些数据?数据怎样防止丢失?前端怎么控制 button 权限?
jwt 鉴权,token,session 问题
umi 框架相关的问题?
vue 相关问题,vuex 原理?vue2 和 3 的区别?vite 原理?
vue-router 和 react-router 这种路由怎么实现?
项目中有没有什么有挑战性的东西?怎么解决的?
Nextjs 框架怎么使用?相关面试题?
PM2 守护进程了解多少?docker 原理?一些关键字的左右?ngnix 怎样配置代理?
JavaScript
什么是闭包,有什么用?
就是有权访问另外一个函数作用域中变量的函数。作用就是实现变量的私有化。
应用场景:比如实现了一个防抖函数,就用到了闭包。
事件循环机制(和 Node 的区别)
浏览器中:
- 首先将执行栈最开始的所有同步代码(宏任务)执行完成;
- 检查是否有微任务,如有则执行所有微任务;
- 取出任务队列中事件对应的回调函数(宏任务)进入执行栈并执行完成;
- 再检查是否有微任务,如有则执行所有的微任务;
- 主线程不断重复上面的 3、4 步。
宏任务包括:整体的代码逻辑、setTimemout/setInterval/IO 操作/UI 渲染
微任务包括:Promise.then/async/await/MutationObserver 等
伪代码:
while (true) {
宏任务队列.shift();
微任务队列全部任务();
}
而 Node 中的事件循环分为一下:
incoming data(输入数据阶段)--->poll(轮训阶段)---->check(检查阶段)----->close callbacks(关闭事件回调阶段)----->timer(定时器检测阶段)-------->pending callbacks(I.O 事件回调阶段)------->idle、prepare(闲置阶段)---->poll.....
- 定时器检测阶段(timers):本阶段执行 timers 的回调,即 setTimeout、setInterval 里面的回调函数
- I / O 事件回调阶段(I / O callbacks):执行延迟到下一个循环迭代的 I / O 回调,即上一轮循环中未被执行的一些 I / O 回调
- 闲置阶段(idle,prepare):仅供内部使用
- 轮询阶段(poll):检索新的 I / O 事件;执行与 I / O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些计时器和 setImmediate 调度之外),其余情况 node 将在适当的时候在此阻塞
- 检查阶段(check):setImmediate 回调函数将在此阶段执行
- 关闭
while (true) {
loop.forEach((阶段) => {
阶段任务队列全部任务();
nextTick任务队列全部任务();
microTask任务队列全部任务();
});
loop = loop.next;
}
process.nextTick 是独立于事件循环的任务队列
在每一个事件循环阶段完成后会去检查 nextTick 队列,如果里面有任务,会让这部分任务优先于微任务执行。
setImmediate(() => {
console.log("timeout1");
Promise.resolve().then(() => console.log("promise resolve"));
process.nextTick(() => console.log("next tick1"));
});
setImmediate(() => {
console.log("timeout2");
process.nextTick(() => console.log("next tick2"));
});
setImmediate(() => console.log("timeout3"));
setImmediate(() => console.log("timeout4"));
在 node11 之前,因为每一个事件循环阶段完成后都会去检查 nextTick 队列,如果里面有任务,会让这部分任务优先于微任务执行,因此上述代码是先进入 check 阶段,执行所有 setImmediate,完成之后执行 nextTick 队列,最后执行微任务队列,因此输出为:
// timeout1 -> timeout2 -> timeout3 -> timeout4 -> next tick1 -> next tick2 -> promise resolve
在 node11 之后,process.nextTick 被视为是微任务的一种,因此上述代码是先进入 check 阶段,执行一个 setImmediate 宏任务,然后执行其微任务队列,在执行下一个宏任务及其微任务队列,因此输出为:
// timeout1 -> next tick1 -> promise resolve -> timeout2 -> next tick2 -> timeout3 -> timepout4
如果是 node11 版本一旦执行一个阶段里的一个宏任务(setTimeout、setInterval、setImmediate)就会立刻执行对应的微任务队列
node 和 浏览器事件循环的主要区别
两者主要的区别在于浏览器中的微任务是在每个相应的宏任务中执行的,而 nodejs 中的微任务则是在不同阶段之间执行的。
原型和原型链
原型存在的主要目的是为了共享可复用的公共状态和逻辑。对于一个函数,如果使用 new 操作符来调用,就会被当做构造函数,然后返回的对象就是实例。
实例中会有一个__proto__的字段,他指向的是生成的它的原型。也就是构造函数的 prototype。这个 prototype 只在函数上有,里面存放的就是可以共享给实例的属性和方法。而 prototype 有个字段交 constructor,指向的是这个构造函数。而 protoytype 本身就是一个对象,所有也是有隐式原型__proto__的,这个指向生成这个原型对象的原型对象。因此,这个链会一直网上找,形成原形链。

事件委托
主要就是利用了浏览器中的事件执行机制,当某一元素触发一个事件时,会从这个元素逐级向外层检测是否存在与这个事件同样的监听,如果有,就会触发执行这个监听。也就是事件冒泡。
利用事件委托,可以给有大量子节点的元素绑定事件委托,子节点的事件都冒泡的父元素上,这样就也可以较少很多事件绑定。
例如在 react 的合成事件中,就是在根元素上通过事件委托拿到了所有事件的监听,再去形成自己的合成事件的。
浏览器事件机制(事件捕获、事件冒泡)
事件捕获是当点击元素是,事件触发的顺序是从最外层元素一层一层向内寻找到目标元素上。
事件冒泡是当点击元素时,事件从元素一层一层向外触发寻找到最外层监听该事件的元素上。
JS 实现继承的几种方式?
一:原型链继承
function Parent() {
this.name = "zhangsan";
this.children = ["A", "B"];
}
Parent.prototype.getChildren = function () {
//共享的方法挂在了prototype上
console.log(this.children);
};
function Child() {}
Child.prototype = new Parent(); //这里是直接把Parent实例给了Child的prototype,所以拿不到Child(params)的params,无法传参数
var child1 = new Child(); //这里无法传参数,因为Child函数里面没办法给Parent函数
child1.children.push("child1");
console.log(child1.getChildren()); // Array ["A", "B", "child1"]
var child2 = new Child();
child2.children.push("child2");
console.log(child2.getChildren()); // Array ["A", "B", "child1", "child2"]
问题:1. 所有实例共享原型上的方法和属性,所有每个实例都可以修改,实例之间会互相影响。2、在创建子类型的实例时,不能传递参数
二、借用构造函数(constructor stealing)
思想:在子类构造函数中调用父类构造函数。因为毕竟函数就是在特定上下文中执行代码的简单对象,所以可以使用 apply()和 call()方法以新创建的对象为上下文执行构造函数。
function Parent(age) {
this.names = ["lucy", "dom"];
this.age = age;
this.getName = function () {
//注意:这里的方法跟原型不同,是挂在了构造函数this上
return this.name;
};
this.getAge = function () {
return this.age;
};
}
function Child(age) {
Parent.call(this, age);
}
var child1 = new Child(18);
child1.names.push("child1");
console.log(child1.names); // [ 'lucy', 'dom', 'child1' ]
var child2 = new Child(20);
child2.names.push("child2");
console.log(child2.names); // [ 'lucy', 'dom', 'child2' ]
优点:1.子实例属性属于自己(this),不会被其他实例影响 2. 可以给 Child 传参数了,因为 Child 里面使用了 call 方法,可以接受参数
缺点:所有的方法都在构造函数中生命里,也就是每个实例都需要创建这些方法,函数复用成了笑话。
三、组合继承
就是把原型链和借用构造函数连中方式结合在了一起,使用原型链实现对原型属性和方法的继承,通过借用构造函数实现对实例属性的继承。
function Parent(name, age) {
this.name = name;
this.age = age;
this.colors = ["red", "green"];
console.log("parent");
}
Parent.prototype.getColors = function () {
console.log(this.colors);
};
function Child(name, age, grade) {
Parent.call(this, name, age); // 创建子类实例时会执行一次
this.grade = grade;
}
Child.prototype = new Parent(); // 指定子类原型会执行一次
Child.prototype.constructor = Child; // 校正构造函数
Child.prototype.getName = function () {
console.log(this.name);
};
var c = new Child("alice", 10, 4);
console.log(c.getName()) > "parent" > "parent" > "alice";
优点:原型链上实现函数复用,构造函数实现每个实例有自己的属性。
缺点:创建子类时,会调用 2 次父类的构造函数。如上面,Child 自己把 Parent 挂到原型上是需要调用一次,而 Child 被实例化时通过 call 又调用了一次 Parent。
四、原型式继承
借助原型可以基于已有的对象创建新对象,同时还不必因此创建自定义类型。
在 object()函数内部,先创建了一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回这个临时类型的一个新实例。本质上 object()就是完成了一次浅复制操作
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
var person = {
name: "alice",
friends: ["leyla", "court", "van"],
};
var p1 = object(person);
p1.name = "p1";
p1.friends.push("p1");
var p2 = object(person);
p2.name = "p2";
p2.friends.push("p2");
console.log(p1.name);
console.log(person.friends) > Array[("leyla", "court", "van", "p1", "p2")];
ECMAScript5 通过新增 Object.create()方法规范化了原型式继承,这个方法接收两个参数:一个用作新对象原型的对象和为新对象定义属性的对象
var person = {
name: "alice",
friends: ["leyla", "court", "van"],
};
var p1 = Object.create(person);
p1.name = "p1";
p1.friends.push("p1");
var p2 = Object.create(person);
p2.name = "p2";
p2.friends.push("p2");
console.log(p1.name);
console.log(person.friends) > Array[("leyla", "court", "van", "p1", "p2")];
五、寄生式继承
寄生式继承是与原型式继承紧密相关的一种思路,即创建一个仅用于封装继承函数过程的函数,该函数在内部以某种方式来增强对象,最后返回对象。
function object(obj) {
function F(){};
F.prototype = obj;
return new F();
}
function createAnother(original) {
var clone = object(original); // 创建新对象
clone.sayHi = function(){
console.log('hello, world'); // 增强对象,添加属性或方法
}
return clone; // 返回新对象
}
var person = {
name: 'alice',
friends: ['Sherly', 'Taissy', 'Vant']
}
var p1 = createAnother(person);
p1.sayHi();
> "hello, world"
缺点:添加函数还是要每个实例都添加一次,没办法复用,类似于构造函数
六、寄生组合式继承
组合继承是 JavaScript 最常用的继承模式,其最大的问题是不管在什么情况下都会调用两次超类构造函数:一次是在创建子类原型时,一次是在子类型构造函数内部。子类型最终会包含超类的全部实例属性。 所谓寄生组合式继承,即通过构造函数来继承属性,通过原型链继承方法,背后的基本思路是:不必为了指定子类的原型而调用超类的构造函数,我们所需要的无非就是超类原型的一个副本而已。寄生组合继承的基本模式如下所示:
function Parent(name, age){
this.name = name;
this.age = age;
console.log('parent')
}
Parent.prototype.getName = function(){
return this.name;
}
function Child(name, age, grade){
Parent.call(this, name, age);
this.grade = grade;
}
// 寄生组合的方式
// 复制父类的原型对象
function create(original) {
function F(){};
F.prototype = original;
return new F();
}
// 创建父类的原型副本,改变子类的原型,同时纠正构造函数
function inherit(subClass, superClass) {
var parent = create(superClass.prototype);
parent.constructor = subClass;
subClass.prototype = parent;
}
inherit(Child, Parent);
var child = new Child('lucy', 12, 5);
> "parent"
寄生组合继承的高效率在于它只调用了一次超类构造函数,同时还能够保持原型链不变,能够正常使用 instanceof 和 isPrototypeOf() 寄生组合继承被普遍认为是引用类型最理想的继承方式
| 继承方式 | 优点 | 缺陷 |
|---|---|---|
| 原型链继承 | 能够实现函数复用 | 1.引用类型的属性被所有实例共享;2.创建子类时不能向超类传参 |
| 借用构造函数 | 1. 避免了引用类型的属性被所有实例共享; 2. 可以在子类中向超类传参 | 方法都在构造函数中定义了,每次创建实例都会创建一遍方法,无法实现函数复用 |
| 组合继承 | 融合了原型链继承和构造函数的优点,是 Javascript 中最常用的继承模式 | 创建子类会调用两次超类的构造函数 |
| 原型式继承 | 在没有必要兴师动众地创建构造函数,而只是想让一个对象与另一个对象保持类似的情况下,原型式继承完全可以胜任 | 引用类型的属性会被所有实例共享 |
| 寄生式继承 | 可以增强对象 | 使用寄生式继承来为对象添加函数,会由于不能做到函数复用造成效率降低,这一点与构造函数模式类似;同时存在引用类型的属性被所有实例共享的缺陷 |
| 寄生组合继承 | 复制了超类原型的副本,而不必调用超类构造函数;既能够实现函数复用,又能避免引用类型实例被子类共享,同时创建子类只需要调用一次超类构造函数 | - |
在 ES5 中怎样实现继承,ES6 怎样继承?super 有什么作用
es5 继承方式如上面 6 种
ES6 提供了 Class 关键字来实现类的定义,Class 可以通过 extends 关键字实现继承,让子类继承父类的属性和方法。
在 constructor 中必须调用 super 方法,因为子类没有自己的 this 对象,而是继承父类的 this 对象,然后对其进行加工,而 super 就代表了父类的构造函数。super 虽然代表了父类 A 的构造函数,但是返回的是子类 B 的实例,即 super 内部的 this 指的是 B,因此 super() 在这里相当于 A.prototype.constructor.call(this, props)
class A {}
class B extends A {
constructor() {
super(); // ES6 要求,子类的构造函数必须执行一次 super 函数,否则会报错。
}
}
高阶函数(High-Order-Function)
高阶函数可以把其他函数作为参数输入或者作为其返回值输出。
如果一个函数符合下面 2 个 规范中任何一个,那该函数就是高阶函数
1、若a函数,接收的参数是一个函数,那么a就可以称之为高阶函数
2、若a函数,调用的返回值依然是一个函数,那么a就可以称之为高阶函数。
原生的方法有很多都是高阶函数,例如 Array.prototype.map 方法,他接收一回调函数,从回调函数中获取返回值,再使用这些值创建一个新的数组并返回。
函数柯里化
柯里化是把接收多个参数的函数变成接收单一参数的函数,剩下的参数再通过返回的函数来进行接收。 简单理解就是把函数拆的更细,返回的函数依赖第一个参数进行计算,可以缩小适用范围,创建一个针对性更强的函数。
const formatMoney = (step) => (money) => {
let str = (money / step).toFixed(2); // 两位小数
const index = str.indexOf(".");
if (index > 3) {
const start = str.substring(0, index).replace(/\B(?=(?:\d{3})+$)/g, ","); // 增加千分位符号
return start + str.substring(index);
}
return str;
};
const pennyMoney = formatMoney(100); // 单位是分
pennyMoney(1000000); // 10,000.00
pennyMoney(123456); // 1,234.56
const dimeMoney = formatMoney(10); // 单位是角
dimeMoney(1000000); // 100,000.00
dimeMoney(123456); // 12,345.60
formatMoney(1)(1000000); // 1,000,000; // 元
同步和异步,async 和 await 原理
async/await的用处就是:用同步方式,执行异步操作,怎么说呢?举个例子
const getData = () =>
new Promise((resolve) => setTimeout(() => resolve("test-normal"), 1000));
async function test() {
const data = await getData();
console.log("test-data: ", data);
const data2 = await getData();
console.log("test-data2: ", data2);
return "success";
}
// 这样的一个函数 应该再1秒后打印data 再过一秒打印data2 最后打印success
test().then((res) => console.log(res));
//test-data: test-normal
//test-data2: test-normal
//success
const getData1 = () =>
new Promise((resolve) => setTimeout(() => resolve("testG-data"), 1000));
// 第一步:await编译为yield
// 第二步:函数变为generator
function* testG() {
const data1 = yield getData1();
console.log("testG-data1: ", data1);
const data2 = yield getData1();
console.log("testG-data2: ", data2);
return "success";
}
// 核心函数,用来替代async操作符
function asyncGenerator(genFunc) {
//返回一个新的函数,类似于async test(){}返回的包裹函数
return function () {
//获取迭代器,相当于testG()执行后返回的迭代器
const gen = genFunc.apply(this, arguments);
//返回一个promise,我们知道上面例子中async test()执行后 返回的就是1个promise
// 因为外部是用.then的方式 或者await的方式去使用这个函数的返回值的
return new Promise((resolve, reject) => {
// 内部定义一个step函数 用来一步一步的跨过yield的阻碍
// arg参数则是用来把promise resolve出来的值交给下一个yield
function step(arg) {
let genResult;
// 这个方法需要包裹在try catch中
// 如果报错了 就把promise给reject掉 外部通过.catch可以获取到错误
try {
//我们发现,每次调用next,都是执行yield后面的函数
//下一次再调用next时,才是把上一次的返回值赋值,然后执行下一次的yield后面的函数
genResult = gen.next(arg);
} catch (error) {
return reject(error);
}
const { value, done } = genResult; //这个value当还没有结束时,就是1个promise,如果结束了,就是最后return的值
if (done) {
// 如果已经完成了 就直接resolve这个promise
// 这个done是在最后一次调用next后才会为true
// 以本文的例子来说 此时的结果是 { done: true, value: 'success' }
// 这个value也就是generator函数最后的返回值
return resolve(value);
} else {
//递归调用
// 除了最后结束的时候外,每次调用gen.next()
// 其实是返回 { value: Promise, done: false } 的结构,
// 这里要注意的是Promise.resolve可以接受一个promise为参数
// 并且这个promise参数被resolve的时候,这个then才会被调用
// 这个value对应的是yield后面的promise
return Promise.resolve(value).then((val) => step(val));
}
}
step();
});
};
}
const asyncTest = asyncGenerator(testG);
asyncTest().then((res) => console.log(res));
//testG-data1: testG-data
//testG-data2: testG-data
//success
隐式类型转换
数学运算符中的类型转换
因为 JS 并没有类型声明,所以任意两个变量或字面量,都可以做加减乘除。
- 减、乘、除
⭐️ 我们在对各种非Number类型运用数学运算符(- \* /)时,会先将非Number类型转换为Number类型。
1 - true; // 0, 首先把 true 转换为数字 1, 然后执行 1 - 1
1 - null; // 1, 首先把 null 转换为数字 0, 然后执行 1 - 0
1 * undefined; // NaN, undefined 转换为数字是 NaN
2 * ["5"]; // 10, ['5']首先会变成 '5', 然后再变成数字 5
上面例子中的 ['5']的转换,涉及到拆箱操作,将来有机会再出一篇文章说明。
- 加法的特殊性
⭐️ 为什么加法要区别对待?因为 JS 里 +还可以用来拼接字符串。谨记以下 3 条:
- 当一侧为
String类型,被识别为字符串拼接,并会优先将另一侧转换为字符串类型。 - 当一侧为
Number类型,另一侧为原始类型,则将原始类型转换为Number类型。 - 当一侧为
Number类型,另一侧为引用类型,将引用类型和Number类型转换成字符串后拼接。
⭐️ 以上 3 点,优先级从高到低,即 3+'abc' 会应用规则 1,而 3+true会应用规则 2。
123 + "123"; // 123123 (规则1)
123 + null; // 123 (规则2)
123 + true; // 124 (规则2)
123 + {}; // 123[object Object] (规则3)
逻辑语句中的类型转换
当我们使用 if while for 语句时,我们期望表达式是一个Boolean,所以一定伴随着隐式类型转换。而这里面又分为两种情况:
1.单个变量
⭐️ 如果只有单个变量,会先将变量转换为 Boolean 值。
我们可以参考附录的转换表来判断各种类型转变为Boolean后的值。
不过这里有个小技巧:
只有 null undefined '' NaN 0 false 这几个是 false,其他的情况都是 true,比如 {} , []。
2.使用 == 比较中的 5 条规则
虽然我们可以严格使用 ===,不过了解==的习性还是很有必要的。
⭐️ 根据 == 两侧的数据类型,我们总结出 5 条规则:
- 规则 1:
NaN和其他任何类型比较永远返回false(包括和他自己)。
NaN == NaN; // false
- 规则 2:Boolean 和其他任何类型比较,Boolean 首先被转换为 Number 类型。
true == 1; // true
true == "2"; // false, 先把 true 变成 1,而不是把 '2' 变成 true
true == ["1"]; // true, 先把 true 变成 1, ['1']拆箱成 '1', 再参考规则3
true == ["2"]; // false, 同上
undefined == false; // false ,首先 false 变成 0,然后参考规则4
null == false; // false,同上
- 规则 3:
String和Number比较,先将String转换为Number类型。
123 == "123"; // true, '123' 会先变成 123
"" == 0; // true, '' 会首先变成 0
规则 4:null == undefined比较结果是true,除此之外,null、undefined和其他任何结果的比较值都为false。
null == undefined; // true
null == ""; // false
null == 0; // false
null == false; // false
undefined == ""; // false
undefined == 0; // false
undefined == false; // false
规则 5:原始类型和引用类型做比较时,引用类型会依照ToPrimitive规则转换为原始类型。
⭐️
ToPrimitive规则,是引用类型向原始类型转变的规则,它遵循先valueOf后toString的模式期望得到一个原始类型。
如果还是没法得到一个原始类型,就会抛出 TypeError。
"[object Object]" == {};
// true, 对象和字符串比较,对象通过 toString 得到一个基本类型值
"1,2,3" == [1, 2, 3];
// true, 同上 [1, 2, 3]通过 toString 得到一个基本类型值
这个表老实用了,在执行上面提到的转换规则时,可以参考这个对照表。
js 存储方式
原始类型:栈内存中
引用类型:堆内存中
new 执行的过程
1、创建一个原型对象
2、将函数的__proto__指向原型对象
3、调用函数,改变 this
4、根据函数返回结果,如果是引用类型,返回这个引用类型,否则返回这个对象
function myNew() {
let Con = Array.prototype.shift.call(arguments);
let obj = {};
obj.__proto__ = Con.prototype;
let res = Con.apply(obj, [...arguments]);
return typeof res === "object" && res !== null ? res : obj;
}
function person(name, age) {
this.name = name;
this.age = age;
}
let p = myNew(person, "布兰", 12);
console.log(p); // { name: '布兰', age: 12 }
this 指向
this 指向最后调用函数的那个对象,也就是说代表函数执行的主体,谁把函数执行的,这就是执行主体。
1、全局作用域下 this 指向 windows
2、函数里面的 this,要看执行主体前面有没有.,有的话就是前面的主体,没有的话,this 指向的就是 window
3、自执行函数的 this 是 windows 或者 undefinded
4、回调函数里面的 this 一般是 windows
5、箭头函数没有 this,使用 this 的话一般往上一级作用域查找,一直到最后的 windows
6、构造函数的 this 是当前的实例
7、实例原型上的公有方法里的 this 也是当前的实例
8、给元素的绑定事件行为,this 就是当前被绑定的元素本身。
作用域(全局作用域、函数作用域和块级作用域)和作用域链,什么是 GC/AO/VO?[[scope]]
执行栈(Execution Context Stack)
全局对象(GO Global Context)
活动对象(Activation Object)
变量对象(Variable Object)
全局上下文(GC global execution context)
执行上下文(EC execution context)
函数调用栈(Callee Stack)
执行上下文栈(ESC execution context stack)
垃圾回收(GC Garbage Collection)
词法环境(LexicalEnvironment)
变量环境(VariableEnvironment)
变量记录(Environment record)
JS 通过执行上下文栈(ECS)来管理和执行上下文。首先遇到全局代码,先往 ECS 推入一个全局执行上下文(GC),只有当整个应用清除以后,ECS 才会清空。也就是说 ECS 最底部永远有个 GC。当遇到函数是,就会创建一个执行上下文,并且压入 ECS。当函数执行完成后,函数的 EC 就会从栈中弹出。
每个执行上下文(EC)包含三个重要属性:VO 变量对象、[[Scope]]作用域链、this。VO 用来存储上下文中的函数声明、形参和变量。
如下代码:
function foo(a) {
var b = 2;
function c() {}
var d = function () {};
b = 3;
}
foo(1);
当进入上下文后,AO 为:
AO = {
arguments: {
0:1,
length:1
},
a:1,
b:undefined,
c: reference to function(){},
d:undefined
}
代码执行过程中会依次为变量赋值,因此执行完之后为:
AO = {
arguments: {
0:1,
length:1
},
a:1,
b:2,
c: reference to function(){},
d: reference to function(){},
}
作用域链:
在上面的静态作用域和动态作用域里面讲到,当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
函数作用域在函数定义的时候就决定了,因为函数内部包含一个[[scope]]属性,当函数创建时就保存了所有父变量对象到其中。
如:
function foo() {
function bar() {
...
}
}
// 函数创建时,各自的[[scope]]
foo.[[scope]]= [
globalContext.VO
]
bar.[[scope]] = [
fooContext.VO,
globalContext.VO
]
当函数调用时,进入函数上下文,创建 VO/AO 后就会将活动对象添加到作用域最前面,也就是把自己函数上的 AO 加上父级的 VO 合到一起:Scope = [AO].concat([[Scope]])
如下例子:
var scope = "global scope";
function checkscope(){
var scope2 = 'local scope';
return scope2;
}
checkscope();
//0. 初始化全局上下文栈
ECStack = [
globalContext
]
//1.checkscope函数创建
checkscope.[[scope]] = [globalContext.VO]
//2、执行checkscope函数,创建上下文栈并压入全局上下文栈
ECStack = [
checkscopeContext,
globalContext,
]
//3.checkscope并没有立即执行代码,而是准备上下文
checkscopeContext = {
Scope: checkscope.[[scope]]
}
//4.创建函数的AO活动对象
checkscopeContext= {
AO:{
arguments: {
length:0
},
scope2:undefined
},
Scope: checkscope.[[scope]],
}
//5. 把AO压入到作用域链中
checkscopeContext= {
AO:{
arguments: {
length:0
},
scope2:undefined
},
Scope: [AO,[[Scope]]],
}
//6. 随着代码执行,给AO中的属性赋值
checkscopeContext= {
AO:{
arguments: {
length:0
},
scope2:"local scoped"
},
Scope: [AO,[[Scope]]],
}
//7. 最后返回值为scope2,从AO上找到了scope2的值,返回函数执行,并且把函数上下文从执行栈中弹出
ECStack = [
globalContext,
]
js 数组在栈内存和堆内存存储方式
数组是引用类型,他的引用地址存储在栈内存中,数据存储在堆内存中,栈内存中存储的是堆内存的地址

V8 引擎原理

V8 是一个由 Google 开发的开源 JavaScript 引擎,目前用在 Chrome 浏览器和 Node.js 中,其核心功能是执行易于人类理解的 JavaScript 代码。

简单理解,V8 就是'寄生兽',因为寄生在不同的宿主下,因此会出现略有区分的实现,例如 node 和浏览器的 eventloop 不同的情况。

解释执行:需要先将输入的源代码通过解析器编译成中间代码,之后直接使用解释器解释执行中间代码,然后直接输出结果。
代码 → 解析器转码中间代码AST → 解释器 -> 执行
编译执行:先将源代码转换为中间代码,然后我们的编译器再将中间代码编译成机器代码。
代码 → 解析器转码中间代码AST → 编译器 → 二进制机器码 -> 执行
即时编译(Just-in-time compilation):长话短说,先走解释执行,在解释器对代码进行监控,对重复执行频率高的代码打上 tag,成为可优化的热点代码,之后流向编译执行的模式,对可优化的代码进行一个编译转成二进制机器码并存储,之后就地复用二进制码减少解释器和机器的压力再执行。
代码 → 解析器转码中间代码 AST → 解释器 → 执行
↓ ↑ 反编译
监控热力代码 → 编译器 → 二进制机器码 → 执行
V8 JIT 最为核心的因素!
上图中的中间代码 AST 即为字节码。
为什么要用字节码呢?
是编译过程中做了一个空间(编译执行)和时间(解释执行)上的权衡的中间代码(既要快,又要小)。
怎么做的呢?
- 字节码允许被解释器直接执行。
- 热力代码被优化,从字节码编译成二进制代码执行(字节码与二进制码的执行过程接近,所以编译能提效)。
- 因为移动端兴起,所以采用了比二进制占用空间小的字节码,这样可以被浏览器缓存(内存),被机器缓存(硬盘)。
- 字节码被解释器编译的速度更快增加了启动速度,同时直接执行只不过执行速度比机器代码慢。
- 不同 cpu 处理器因平台不同所以机器代码不同,字节码与机器代码执行流程接近因此降低了编译器将字节码转换机器代码的时间。
垃圾回收机制
垃圾回收的实现简单分为以下三个步骤:
第一步:可访问性
从 GC Roots 对象出发,遍历 GC Root 中的所有对象:
- 可访问对象:通过 GC Root 遍历到的对象,我们就认为该对象是可访问的(reachable),那么必须保证这些对象应该在内存中保留。
- 不可访问对象:通过 GC Roots 没有遍历到的对象,则是不可访问的(unreachable),并会对其坐上标记,那么这些不可访问的对象就可能被回收。
浏览器环境中,GC Root 有很多,通常包括了以下几种 (但是不止于这几种):全局的 window 对象(位于每个 iframe 中);文档 DOM 树,由可以通过遍历文档到达的所有原生 DOM 节点组成;存放在栈上变量。
第二步:回收不可访问对象所占据的内存
- 其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。
第三步:内存整理
- 频繁回收对象后,内存中就会存在大量不连续空间,称为内存碎片。当出现了大量的内存碎片之后,如果需要分配较大的连续内存时,就会出现内存不足的情况,所以最后一步需要整理这些内存碎片。但这步不是必须的,比如接下来我们要介绍的副垃圾回收器就不会产生内存碎片。
以上就是大致的垃圾回收的流程。目前 V8 采用了两个垃圾回收器,主垃圾回收器和副垃圾回收器,下面我们再具体来看看两个回收器是怎么回收垃圾的。
副垃圾回收器和主垃圾回收器
- 在 V8 中,会把堆分为新生代(新生代通常只支持 1 ~ 8M 的容量)和老生代(容量大)两个区域,新生代中存放的是生存时间短的对象,老生代中存放生存时间久的对象。
副垃圾回收器
负责新生代的垃圾回收,大多数小的对象都会被分配到新生代,垃圾回收比较频繁。
新生代中的垃圾数据用 Scavenge 算法来处理。分为两个区域:对象区域 ,空闲区域。如下图所示:
垃圾回收过程:
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
1.垃圾标记和清理:首先要对对象区域中的垃圾做标记;标记完成之后,就进入垃圾清理阶段,如下图:
图中可以看到,副垃圾回收器会把这些我们仍然在用的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,在复制过程,相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
2.角色翻转:完成复制后,进行角色翻转。把原来的对象区变成空闲区,把原来的空闲区变成对象区,如下图:
主垃圾回收器
- 负责老生代中的垃圾回收,大多数占用空间大、存活时间长的对象都会被分配到老生代里。
- 老生代中的垃圾数据用——标记 - 清除算法进行垃圾回收,因为老生代中的对象通常比较大,复制大对象非常耗时,会导致回收执行效率不高,所以采用标记清除法。
- 垃圾回收过程:
- 1.标记:标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
- 2.清除:它和副垃圾回收器的垃圾清除过程完全不同,主垃圾回收器会直接将标记为垃圾的数据清理掉,如下图:
- 3.整理:从上图可以看到,清除后会产生大量不连续的内存碎片,过多的碎片会导致大对象无法分配到足够的连续内存,于是需要引进另一种算法——标记 - 整理,整理过程如下图:
优化垃圾回收器
- 由于 JavaScript 是运行在主线程之上的,在垃圾回收时会阻塞 JavaScript 脚本的执行,会造成页面卡顿等问题,使得用户体验不佳。
- 为了解决上述问题,V8 团队推出了并行、并发和增量等垃圾回收技术,这些技术主要是从两方面来解决垃圾回收效率问题的:
- 1.将一个完整的垃圾回收的任务拆分成多个小的任务,解决单个垃圾回收时间长的问题。
- 2.将标记对象、移动对象等任务转移到后台线程进行,减少主阻塞线程的时间。
接下来我们一起来看下具体这几种技术时怎么优化的。
并行回收
- 如果只有一个主线程进行垃圾回收,会造成停顿时间过长。所以 V8 团队推出主线程在执行垃圾回收的任务时,引入多个辅助线程来并行处理,这样就会加速垃圾回收的执行速度,如下图:
- 副垃圾回收器所采用的就是并行策略,它在执行垃圾回收的过程中,启动了多个线程来负责新生代中的垃圾清理操作,这些线程同时将对象空间中的数据移动到空闲区域。由于数据的地址发生了改变,所以还需要同步更新引用这些对象的指针
增量回收
- 并行回收虽然能增加垃圾回收效率,但是还是一种阻塞的方式进行垃圾回收,试想下引老生代中存在一个很大的对象,还是会造成一个长时间暂停。
- 增量回收采用将标记工作把垃圾回收工作分解为更小的块,每次只进行小部分垃圾回收,减少主线程阻塞时间,如下图:
并发回收
- 虽然增量回收已经能大大降低我们主线程阻塞的时间,但是所有的标记和清除还是在主线程上。那有没有办法可以在不阻塞主线程情况下执行呢?也由此 V8 推出了并发回收。
- 并发回收,是指主线程在执行 JavaScript 的过程中,辅助线程能够在后台完成执行垃圾回收的操作,如下图:
在实际的应用中,这三种回收机制通常是融合在一起用的。
函数调用方法
普通函数直接调用,作为对象的属性方法调用,call/apply 调用,new 调用
事件中 e.target 和 e.currentTarget 区别
e.target:触发事件的元素e.currentTarget:绑定事件的元素
箭头函数和普通函数的区别
1、箭头函数没有 caller、callee、arguments
2、声明方式不同,普通函数需要 function 关键字,箭头函数不用
3、this 指向不同,普通函数指向函数运行时所在的对象。而箭头函数指向的是定义是上层作用域中的 this。也就是说,箭头函数 this 固定为上层作用域 this,而普通函数可能是会改变的。
// ES6
function foo() {
setTimeout(() => {
console.log("id:", this.id);
}, 100);
}
// ES5
function foo() {
var _this = this;
setTimeout(function () {
console.log("id:", _this.id);
}, 100);
}
4、箭头函数 this 永远不会改变,即使使用 call、apply、bind 也不会改变
5、箭头函数没有 prototype,也不能当成构造函数
6、不能使用 yield,所以不能用作 generator 函数
async、await、generator、promise 这三者的关联和区别
都是用来实现异步的解决方案
async 和 await 是 generator 的语法糖,通过使用 generator+promise 实现
generator 和 promise 都是 es6 提供的异步解决方案
set 和 map 区别,weakset 和 weakmap
set:集合中元素唯一且无序、元素可以是任何类型。包含 size、add、delete、has、clear、keys、values、enryies、foreach 等方法
weakset:与 set 类似,也是不重复的值集合,但是里面的元素只能是对象、所有对象都是弱引用 WeakSet 中的对象都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中。也因此,weakset 没有遍历方法。
map:键值对集合,与对象相比,key 可以是任意类型。包含 size、set、get、has、delete、clear、keys、entries、foreach 等
var a = new Map() undefined a.set(123,"aaa")
a.keys().next() // 123 遍历器
a.values().next()// 'aaa' 遍历器
a.entries().next().value // [123, 'aaa']
weakmap:只接受对象作为键名。键值也是若引用
ES6、ES7、ES8、ES9、ES10 新特性一览
ES6(2015):
- 类 class
- 模块化 module
- 箭头函数
- 函数参数默认值
function foo(height = 50, color = 'red') { *// ...* } - 模板字符串``
- 解构赋值
var [first, , , last] = ["one", "two", "three", "four"]; - 延展操作符
... - 对象属性简写
{ name, age, city } - Promise
- Let 与 Const
- Generator
- Proxy 和 Reflect
ES7(2016):
- Array.includes
- a ** b 运算符,相当于 Math.pow(a, b)
ES8(2017):
- async/await
- Object.values()
- Object.entries()
- String padding:
padStart()和padEnd(),填充字符串达到当前长度 - 函数参数列表结尾允许逗号
- Object.getOwnPropertyDescriptors()
ShareArrayBuffer和Atomics对象,用于从共享内存位置读取和写入
/**
*
* @param {*} length 所创建的数组缓冲区的大小,以字节(byte)为单位。
* @returns {SharedArrayBuffer} 一个大小指定的新 SharedArrayBuffer 对象。其内容被初始化为 0。
*/
new SharedArrayBuffer(length)
// Atomics 对象提供了一组静态方法用来对 SharedArrayBuffer 对象进行原子操作。
Atomics.add()
Atomics.and()
......
ES9(2018):
- 异步迭代,
await可以和for...of循环一起使用,以串行的方式运行异步操作
async function process(array) {
for await (let i of array) {
doSomething(i);
}
}
Promise.finally()
Rest/Spread 属性
正则表达式命名捕获组(Regular Expression Named Capture Groups)
正则表达式反向断言(lookbehind)
正则表达式 dotAll 模式
ES10(2019):
行分隔符(U + 2028)和段分隔符(U + 2029)符号现在允许在字符串文字中,与 JSON 匹配
更加友好的 JSON.stringify
新增了 Array 的
flat()方法和flatMap()方法新增了 String 的
trimStart()方法和trimEnd()方法Object.fromEntries()
Symbol.prototype.description
String.prototype.matchAllFunction.prototype.toString()现在返回精确字符,包括空格和注释简化
try {} catch {},修改catch绑定新的基本数据类型
BigIntglobalThis
import()
Legacy RegEx
私有的实例方法和访问器
primose.then 和 catch 区别,all 和 race 区别
如果在 then 的第一个函数里抛出了异常,后面的 catch 能捕获到,而 then 的第二个函数捕获不到:then 的第二个参数本来就是用来处理上一层状态为失败的
第二种写法要好于第一种写法,理由是第二种写法可以捕获前面 then 方法执行中的错误,也更接近同步的写法(try/catch)。因此,建议总是使用 catch 方法,而不使用 then 方法的第二个参数。
promise.all 是所有 promise 成功后才会调用 resolve,但是有 1 个报错就会 reject
promise.allSettled 是所有 promise 都完成才会最终返回,也就是说无论成功失败都要完成才最后调用
promise.race 是只要有 1 个 resolve 或者 1 个 reject,立马结束并相应的 resolve 和 reject
promise.any 和 race 方法是类似的,any 方法会等到一个 resolve 状态,才会决定新 Promise 的状态,如果所有的 Promise 都是 reject 的,那么会报一个 AggregateError 的错误。
什么是 webworker
Web Worker 是一种浏览器提供的 JavaScript API,它允许在后台线程中运行脚本,而不会阻塞主线程。这意味着,即使脚本执行了很长时间,Web 应用程序的 UI 仍然可以保持响应。
Web Worker 有两种类型:Dedicated Worker 和 Shared Worker。Dedicated Worker 是指与一个页面绑定的 Worker,它仅能由该页面的脚本使用。而 Shared Worker 则可以被多个页面共享使用,这使得多个页面可以同时访问同一个后台线程。
Web Worker 的用法非常简单,只需要调用 Worker() 构造函数即可创建一个 Worker 对象。例如,以下代码创建了一个 Dedicated Worker:
// 创建 Dedicated Worker
const myWorker = new Worker("worker.js");
在上面的代码中,我们将 Worker() 构造函数传递给要执行的脚本的 URL。此时,浏览器会创建一个新的后台线程,加载该 URL 指定的脚本,并在该线程中执行。
然后,我们可以在主线程中使用 postMessage() 方法向后台线程发送消息:
// 向 Dedicated Worker 发送消息
myWorker.postMessage("Hello World!");
在后台线程中,我们可以通过监听 message 事件来接收消息:
// 监听消息
self.addEventListener("message", function (e) {
console.log("收到消息:" + e.data);
});
在上面的代码中,我们使用 addEventListener() 方法来监听 message 事件,并在事件处理程序中打印收到的消息。
什么是 serviceworker,怎样实现缓存
ServiceWorker 是一种特化的 Worker,专门来处理跟网页有关的资源(assets),在浏览器和真正的服务端之间扮演一个代理(Proxy)的角色。ServiceWorker 同时引入了缓存(Cache),可以用来存储一个网络响应。
一般来说,ServiceWorker 处理的就是页面与缓存、服务器之间的关系。
ServiceWorker 的出现是为了解决下面的两个问题:
离线请求(提供类似于 App 的用户体验,类 App 的生命周期)
性能优化
由于 ServiceWorker 是一种特化型 Worker,它专门处理资源相关的逻辑,简单来说就是做一些缓存(但不止与此),下面先介绍一下 ServiceWorker 做缓存用到的一个底层 API:Cache
Cache 提供一个Request -> Response的持久缓存,除非显式删除,存储在 Cache 里面的数据不会主动过期,同时也不会主动去更新,需要手动维护其更新。
一个域之内可以存在多个 Cache,可以通过一个名字来标识对应的 Cache:
可以通过 CacheStorage 来获取对应 Cache 对象,有同源策略
// caches extends CacheStorage,是 window / self 上面的一个全局变量
// 下面是通过一个 cacheName 来获取对应的缓存对象
const cache = await caches.open("hello-cache-v1");
然后可以通过 Cache.put 方法将缓存设置进去
const request = new Request("/samples/service-worker/basic/", {
method: "GET",
});
const response = await fetch(request);
const cache = await caches.open("hello-cache-v1");
cache.put(request, response);
结果如下:
下一次获取的时候可以:
const request = new Request("/samples/service-worker/basic/", {
method: "GET",
});
const cache = await caches.open("hello-cache-v1");
const matchResponse = await cache.match(request); // 此处可以获取上次存储的 Response
// 如果是带上路由 query 参数的形式
const request2 = new Request("/samples/service-worker/basic/?a=1", {
method: "GET",
});
const matchResponse = await cache.match(request2, { ignoreSearch: false }); // 如果ignoreSearch=false(默认) 的情况下,此时匹配不上
上述即为 Cache 最基础的用法,另外 Cache 还提供了一些更加简便的方法,比如直接写入 url 即可自动请求缓存的 Cache.addAll 方法等
hashmap 和 object 的区别
key 不相同:在 Object 中, key 必须是简单数据类型(整数,字符串或者是 symbol),而在 Map 中则可以是 JavaScript 支持的所有数据类型,也就是说可以用一个 Object 来当做一个 Map 元素的 key。
元素顺序:Map 元素的顺序遵循插入的顺序,而 Object 的则没有这一特性。
继承:Map 继承自 Object 对象。
class 的理解
class 是 ES6 的新特性,可以用来定义一个类,实际上,class 只是一种语法糖,它是构造函数的另一种写法。(什么是语法糖?是一种为避免编码出错和提高效率编码而生的语法层面的优雅解决方案,简单说就是,一种便携写法。)
class Person {}
typeof Person; // "function"
Person.prototype.constructor === Person; // true
数组的方法,filter、every、flat 的作用
at() 方法接收一个整数值并返回该索引对应的元素,允许正数和负数。负整数从数组中的最后一个元素开始倒数。
concat() 方法用于合并两个或多个数组。此方法不会更改现有数组,而是返回一个新数组。
copyWithin() 方法浅复制数组的一部分到同一数组中的另一个位置,并返回它,不会改变原数组的长度。
const array1 = ['a', 'b', 'c', 'd', 'e'];
// Copy to index 0 the element at index 3
console.log(array1.copyWithin(0, 3, 4));
// Expected output: Array ["d", "b", "c", "d", "e"]
//copyWithin(target, start, end)
target
0 为基底的索引,复制序列到该位置。如果是负数,target 将从末尾开始计算。如果 target 大于等于 arr.length,将不会发生拷贝。如果 target 在 start 之后,复制的序列将被修改以符合 arr.length。
start
0 为基底的索引,开始复制元素的起始位置。如果是负数,start 将从末尾开始计算。如果 start 被忽略,copyWithin 将会从 0 开始复制。
end
0 为基底的索引,开始复制元素的结束位置。copyWithin 将会拷贝到该位置,但不包括 end 这个位置的元素。如果是负数, end 将从末尾开始计算。如果 end 被忽略,copyWithin 方法将会一直复制至数组结尾(默认为 arr.length)。
entries() 方法返回一个新的数组迭代器对象,该对象包含数组中每个索引的键/值对。
const array1 = ["a", "b", "c"];
const iterator1 = array1.entries();
console.log(iterator1.next().value);
// Expected output: Array [0, "a"]
console.log(iterator1.next().value);
// Expected output: Array [1, "b"]
every() 方法测试一个数组内的所有元素是否都能通过某个指定函数的测试。它返回一个布尔值。
fill() 方法用一个固定值填充一个数组中从起始索引到终止索引内的全部元素。不包括终止索引。
filter() 方法创建给定数组一部分的浅拷贝,其包含通过所提供函数实现的测试的所有元素。
find() 方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined。
findIndex()方法返回数组中满足提供的测试函数的第一个元素的索引。若没有找到对应元素则返回 -1。
findLast() 方法返回数组中满足提供的测试函数条件的最后一个元素的值。如果没有找到对应元素,则返回 undefined。
findLastIndex() 方法返回数组中满足提供的测试函数条件的最后一个元素的索引。若没有找到对应元素,则返回 -1。
flat() 方法会按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
// flat(depth),depth 可选 指定要提取嵌套数组的结构深度,默认值为 1。
flatMap() 方法首先使用映射函数映射每个元素,然后将结果压缩成一个新数组。它与 map 连着深度值为 1 的 flat 几乎相同,但 flatMap 通常在合并成一种方法的效率稍微高一些。
forEach() 方法对数组的每个元素执行一次给定的函数。
Array.from() 方法对一个类似数组或可迭代对象创建一个新的,浅拷贝的数组实例。
includes() 方法用来判断一个数组是否包含一个指定的值,根据情况,如果包含则返回 true,否则返回 false。
indexOf() 方法返回在数组中可以找到给定元素的第一个索引,如果不存在,则返回 -1。
Array.isArray() 用于确定传递的值是否是一个 Array。
join() 方法将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串,用逗号或指定的分隔符字符串分隔。如果数组只有一个元素,那么将返回该元素而不使用分隔符。
keys() 方法返回一个包含数组中每个索引键的 Array Iterator 对象。
lastIndexOf() 方法返回指定元素(也即有效的 JavaScript 值或变量)在数组中的最后一个的索引,如果不存在则返回 -1。从数组的后面向前查找,从 fromIndex 处开始。
map() 方法创建一个新数组,这个新数组由原数组中的每个元素都调用一次提供的函数后的返回值组成。
Array.of() 方法通过可变数量的参数创建一个新的 Array 实例,而不考虑参数的数量或类型。
pop() 方法从数组中删除最后一个元素,并返回该元素的值。此方法会更改数组的长度。
push() 方法将一个或多个元素添加到数组的末尾,并返回该数组的新长度。
reduce() 方法对数组中的每个元素按序执行一个由您提供的 reducer 函数,每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值。第一次执行回调函数时,不存在“上一次的计算结果”。如果需要回调函数从数组索引为 0 的元素开始执行,则需要传递初始值。否则,数组索引为 0 的元素将被作为初始值 initialValue,迭代器将从第二个元素开始执行(索引为 1 而不是 0)。
reduceRight() 方法接受一个函数作为累加器(accumulator)和数组的每个值(从右到左)将其减少为单个值。
reverse() 方法将数组中元素的位置颠倒,并返回该数组。数组的第一个元素会变成最后一个,数组的最后一个元素变成第一个。该方法会改变原数组。
shift() 方法从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。
slice() 方法返回一个新的数组对象,这一对象是一个由 begin 和 end 决定的原数组的浅拷贝(包括 begin,不包括end)。原始数组不会被改变。
some() 方法测试数组中是不是至少有 1 个元素通过了被提供的函数测试。它返回的是一个 Boolean 类型的值。
sort() 方法用原地算法对数组的元素进行排序,并返回数组。默认排序顺序是在将元素转换为字符串,然后比较它们的 UTF-16 代码单元值序列时构建的.由于它取决于具体实现,因此无法保证排序的时间和空间复杂性。
splice() 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
toLocaleString() 返回一个字符串表示数组中的元素。数组中的元素将使用各自的 toLocaleString 方法转成字符串,这些字符串将使用一个特定语言环境的字符串(例如一个逗号 ",")隔开。
toString() 方法返回一个字符串,表示指定的数组及其元素。
unshift() 方法将一个或多个元素添加到数组的开头,并返回该数组的新长度。
values() 方法返回一个新的 Array Iterator 对象,该对象包含数组每个索引的值。
jquery 实现链式调用的原理
通过 return this 这样的方式,就实现了链式调用,因为每次 return 的都是 jquery 本身,所以可以调用 jquery 自身的方法。
function myjquery(selector){
if(typeof selector=="string"){
var eles=document.querySelectorAll(selector);
for(var i=0;i<eles.length;i++){
this[i]=eles[i];
}
this.length=eles.length;
}else if(typeof selector=="object" && selector.nodeType==1){
this[0]=selector;
this.length=1;
}
}
myjquery.prototype={
this.onclick=function(){
callback.call(obj)
}
return this
}
介绍一下宏任务和微任务,微任务的优先级
事件循环由宏任务和在执行宏任务期间产生的所有微任务组成。完成当下的宏任务后,会立刻执行所有在此期间入队的微任务。
这种设计是为了给紧急任务一个插队的机会,否则新入队的任务永远被放在队尾。区分了微任务和宏任务后,本轮循环中的微任务实际上就是在插队,这样微任务中所做的状态修改,在下一轮事件循环中也能得到同步。
常见的宏任务有:script(整体代码)/setTimout/setInterval/setImmediate(node 独有)/requestAnimationFrame(浏览器独有)/IO/UI render(浏览器独有)
常见的微任务有:process.nextTick(node 独有)/Promise.then()/Object.observe/MutationObserver
为什么 JS 要被设计为单线程?
JS 被设计为单线程的主要原因是为了避免多线程编程所带来的复杂性。如果 JS 是多线程的,那么在处理并发问题时,需要考虑锁、同步等一系列复杂的问题,这会增加代码的复杂度和开发难度。
此外,JS 最初是为了解决网页交互的问题而诞生的,而网页交互的需求大部分是基于用户事件的,比如点击按钮、输入文本等。这些操作的响应速度要求很高,如果在响应事件的同时还要处理其他任务,可能会导致网页卡顿、响应变慢等用户体验不佳的问题。
因此,为了避免多线程所带来的复杂性和降低开发难度,并且满足网页交互的高响应速度需求,JS 被设计为单线程。虽然单线程有局限性,但是可以通过异步编程、事件循环机制等技术手段来实现高效的并发处理。
什么是 MutationObserver?
MutationObserver 给开发者们提供了一种能在某个范围内的 DOM 树发生变化时作出适当反应的能力。该 API 设计用来替换掉在 DOM 3 事件规范中引入的 Mutation 事件。
- 监视 DOM 变动的接口
当监视的 DOM 发生变动时 MutationObserver 将收到通知并触发事先设定好的回调函数。
- 类似于事件,但是异步触发
添加监视时,MutationObserver 上的 observer 函数与 addEventListener 有相似之处,但不同于后者的同步触发,MutationObserver 是异步触发,此举是为了避免 DOM 频繁变动导致回调函数被频繁调用,造成浏览器卡顿。
方法:
阻止 MutationObserver 实例继续接收的通知,直到再次调用其 observe() 方法,该观察者对象包含的回调函数都不会再被调用。
配置 MutationObserver 在 DOM 更改匹配给定选项时,通过其回调函数开始接收通知。
从 MutationObserver 的通知队列中删除所有待处理的通知,并将它们返回到 MutationRecord 对象的新 Array 中。
示例:
// 选择需要观察变动的节点
const targetNode = document.getElementById("some-id");
// 观察器的配置(需要观察什么变动)
const config = { attributes: true, childList: true, subtree: true };
// 当观察到变动时执行的回调函数
const callback = function (mutationsList, observer) {
// Use traditional 'for loops' for IE 11
for (let mutation of mutationsList) {
if (mutation.type === "childList") {
console.log("A child node has been added or removed.");
} else if (mutation.type === "attributes") {
console.log("The " + mutation.attributeName + " attribute was modified.");
}
}
};
// 创建一个观察器实例并传入回调函数
const observer = new MutationObserver(callback);
// 以上述配置开始观察目标节点
observer.observe(targetNode, config);
// 之后,可停止观察
observer.disconnect();
什么是 setImmediate?
非标准: 该特性是非标准的,请尽量不要在生产环境中使用它!
该方法用来把一些需要长时间运行的操作放在一个回调函数里,在浏览器完成后面的其他语句后,就立刻执行这个回调函数。
备注: 该方法可能不会被批准成为标准,目前只有最新版本的 Internet Explorer 和 Node.js 0.10+ 实现了该方法。它遇到了 Gecko(Firefox) 和Webkit (Google/Apple) 的阻力。
var immediateID = setImmediate(func, [param1, param2, ...]);
var immediateID = setImmediate(func);
immediateID是这次 setImmediate 方法设置的唯一 ID,可以作为window.clearImmediate的参数。func是将要执行的回调函数
所有参数都会直接传给你的函数。
什么是 requestIdleCallback?
window.requestIdleCallback() 方法插入一个函数,这个函数将在浏览器空闲时期被调用。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。
你可以在空闲回调函数中调用 requestIdleCallback(),以便在下一次通过事件循环之前调度另一个回调。
备注: 强烈建议使用timeout选项进行必要的工作,否则可能会在触发回调之前经过几秒钟。
requestIdleCallback(callback);
requestIdleCallback(callback, options);
callback: 一个在事件循环空闲时即将被调用的函数的引用。函数会接收到一个名为 IdleDeadline 的参数,这个参数可以获取当前空闲时间以及回调是否在超时时间前已经执行的状态。
IdleDeadline.didTimeout(en-US) 只读一个 Boolean 类型当它的值为 true 的时候说明 callback 正在被执行 (并且上一次执行回调函数执行的时候由于时间超时回调函数得不到执行),因为在执行 requestIdleCallback 回调的时候指定了超时时间并且时间已经超时。
返回一个时间
DOMHighResTimeStamp, 并且是浮点类型的数值,它用来表示当前闲置周期的预估剩余毫秒数。如果 idle period 已经结束,则它的值是 0。你的回调函数 (传给 requestIdleCallback 的函数) 可以重复的访问这个属性用来判断当前线程的闲置时间是否可以在结束前执行更多的任务。
options 可选
包括可选的配置参数。具有如下属性:
timeout:如果指定了 timeout,并且有一个正值,而回调在 timeout 毫秒过后还没有被调用,那么回调任务将放入事件循环中排队,即使这样做有可能对性能产生负面影响。
setTimeout、setImmediate、nextTick 区别
https://juejin.cn/post/6844904100195205133
什么是 MessageChannel?
Channel Messaging API 的 MessageChannel 接口允许我们创建一个新的消息通道,并通过它的两个 MessagePort 属性发送数据。
返回 channel 的 port1。
返回 channel 的 port2。
返回一个带有两个 MessagePort 属性的 MessageChannel 新对象。
在以下代码块中,您可以看到使用 MessageChannel 构造函数实例化了一个 channel 对象。当 iframe 加载完毕,我们使用 MessagePort.postMessage 方法把一条消息和 MessageChannel.port2 传递给 iframe。handleMessage 处理程序将会从 iframe 中(使用 MessagePort.onmessage 监听事件)接收到信息,将数据其放入 innerHTML 中。
var channel = new MessageChannel();
var para = document.querySelector("p");
var ifr = document.querySelector("iframe");
var otherWindow = ifr.contentWindow;
ifr.addEventListener("load", iframeLoaded, false);
function iframeLoaded() {
otherWindow.postMessage("Hello from the main page!", "*", [channel.port2]);
}
channel.port1.onmessage = handleMessage;
function handleMessage(e) {
para.innerHTML = e.data;
}
HTML
src 和 href 区别
src 的特性
- 引用外部资源
比如script元素、img元素、iframe元素、video元素
- 会替换元素本身的内容
比如下面这两段代码,会打印出 2,而不是打印 1
// test.js
console.log(2)
<script src="./test.js">
console.log(1)
</script>
原因就是test.js的代码嵌入到了当前script元素中,导致原本的内容被替换。
- 会暂停其他资源的下载
当浏览器解析到使用 src 的元素时,会暂停其他资源资源的下载,直到 src 引用资源加载、编译、执行完毕。这也是为什么 script 元素推荐放在 html 结构的底部
href 的特性
- 表示超链接
比如a标签、link标签,表示外部资源与该页面的联系
- 不会替换元素本身的内容
比如下面这段代码,点击 a 标签跳转到另外一个页面,但图片内容没有被替换
<a href="www.baidu.com">
<img src="xxx" />
</a>
- 不会暂停其他资源的下载
像 CSS 那样影响页面观感的可以放在 html 结构的头部优先加载
核心思想上的区别
- src 代表的是网站的一部分,没有会对网站的使用造成影响。当浏览器解析到该元素时,会暂停其他资源的下载和处理,知道将该资源加载、编译、执⾏完毕,所以⼀般 js 脚本会放在底部而不是头部。
- href 代表网站的附属资源,没有不会对网站的核心逻辑和结构造成影响,当浏览器识别到它他指向的文件时,就会并行下载资源,不会停⽌对当前⽂档的处理。
为什么引用 CSS 使用 href?
- 正如 href 代表的含义一样,CSS 属于网站的附属资源,不影响网站核心逻辑和结构
- 也可以简单归结为历史遗留问题
defer 和 async 的区别
script
浏览器在解析 HTML 的时候,如果遇到一个没有任何属性的 script 标签,就会暂停解析,先发送网络请求获取该 JS 脚本的代码内容,然后让 JS 引擎执行该代码,当代码执行完毕后恢复解析。整个过程如下图所示:
可以看到,script 阻塞了浏览器对 HTML 的解析,如果获取 JS 脚本的网络请求迟迟得不到响应,或者 JS 脚本执行时间过长,都会导致白屏,用户看不到页面内容。
async script
async 表示异步,例如七牛的源码中就有大量的 async 出现:
当浏览器遇到带有 async 属性的 script 时,请求该脚本的网络请求是异步的,不会阻塞浏览器解析 HTML,一旦网络请求回来之后,如果此时 HTML 还没有解析完,浏览器会暂停解析,先让 JS 引擎执行代码,执行完毕后再进行解析,图示如下:
当然,如果在 JS 脚本请求回来之前,HTML 已经解析完毕了,那就啥事没有,立即执行 JS 代码,如下图所示:
所以 async 是不可控的,因为执行时间不确定,你如果在异步 JS 脚本中获取某个 DOM 元素,有可能获取到也有可能获取不到。而且如果存在多个 async 的时候,它们之间的执行顺序也不确定,完全依赖于网络传输结果,谁先到执行谁。
defer script
defer 表示延迟,例如掘金的源码中就有大量的 defer 出现:
当浏览器遇到带有 defer 属性的 script 时,获取该脚本的网络请求也是异步的,不会阻塞浏览器解析 HTML,一旦网络请求回来之后,如果此时 HTML 还没有解析完,浏览器不会暂停解析并执行 JS 代码,而是等待 HTML 解析完毕再执行 JS 代码,图示如下:
如果存在多个 defer script 标签,浏览器(IE9 及以下除外)会保证它们按照在 HTML 中出现的顺序执行,不会破坏 JS 脚本之间的依赖关系。
最后,根据上面的分析,不同类型 script 的执行顺序及其是否阻塞解析 HTML 总结如下:
| script 标签 | JS 执行顺序 | 是否阻塞解析 HTML |
|---|---|---|
<script> | 在 HTML 中的顺序 | 阻塞 |
<script async> | 网络请求返回顺序 | 可能阻塞,也可能不阻塞 |
<script defer> | 在 HTML 中的顺序 | 不阻塞 |
requestAnimationFrame 和 requesIdleCallback
requestIdleCallback:将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间 timeout,则有可能为了在超时前执行函数而打乱执行顺序。
requestAnimationFrame:告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行
hash 和 history 路由区别
hash:
- url 中带一个 # 号
- 可以改变 URL,但不会触发页面重新加载(hash 的改变会记录在 window.hisotry 中)因此并不算是一次 HTTP 请求,所以这种模式不利于 SEO 优化
- 只能修改 # 后面的部分,因此只能跳转与当前 URL 同文档的 URL
- 只能通过字符串改变 URL
- 通过 window.onhashchange 监听 hash 的改变,借此实现无刷新跳转的功能。
- 每改变一次 hash ( window.location.hash),都会在浏览器的访问历史中增加一个记录。
- 路径中从 # 开始,后面的所有路径都叫做路由的
哈希值并且哈希值它不会作为路径的一部分随着 http 请求,发给服务器
history:
- 新的 URL 可以是与当前 URL 同源的任意 URL,也可以与当前 URL 一样,但是这样会把重复的一次操作记录到栈中。
- 通过参数 stateObject 可以添加任意类型的数据到记录中。
- 可额外设置 title 属性供后续使用。
- 通过 pushState、replaceState 实现无刷新跳转的功能。
- 路径直接拼接在端口号后面,后面的路径也会随着 http 请求发给服务器,因此前端的 URL 必须和向发送请求后端 URL 保持一致,否则会报 404 错误。
- 由于 History API 的缘故,低版本浏览器有兼容行问题。
- 监听 popstate 改变
DOM 和 BOM
DOM(document object model):文档对象模型,提供操作页面元素的方法和属性
BOM(browser object model);浏览器对象模型,提供一些属性和方法可以操作浏览器
DOM 和 BOM 的区别
DOM 区域的:
5 区(就是 document。由 web 开发人员呕心沥血写出来的一个文件夹,里面有 index.html,CSS 和 JS 的,部署在服务器上,我们可以通过浏览器的地址栏输入 URL 然后回车将这个 document 加载到本地,浏览,右键查看源代码等。)
BOM 区域的:
1 区(浏览器的标签页,地址栏,搜索栏,书签栏,窗口放大还原关闭按钮,菜单栏等等)
2 区(滚动条 scroll bar)
3 区(浏览器的右键菜单)
4 区(document 加载时的状态栏,显示 http 状态码等)
onload 和 DOMContentLoaded 的区别
1、当 onload 事件触发时,页面上所有的 DOM,样式表,脚本,图片,flash 都已经加载完成了。
2、当 DOMContentLoaded 事件触发时,仅当 DOM 加载完成,不包括样式表,图片,flash,iframe 子框架。
拖拽相关的 api
HTML 拖放(Drag and Drop)接口使应用程序能够在浏览器中使用拖放功能。例如,用户可使用鼠标选择可拖拽(draggable)元素,将元素拖拽到可放置(droppable)元素,并释放鼠标按钮以放置这些元素。拖拽操作期间,会有一个可拖拽元素的半透明快照跟随着鼠标指针。
| 事件 | On 型事件处理程序 | 触发时刻 |
|---|---|---|
drag | ondrag | 当拖拽元素或选中的文本时触发。 |
dragend | ondragend (en-US) | 当拖拽操作结束时触发 (比如松开鼠标按键或敲“Esc”键). (见结束拖拽 (en-US)) |
dragenter | ondragenter (en-US) | 当拖拽元素或选中的文本到一个可释放目标时触发(见 指定释放目标 (en-US))。 |
dragleave | ondragleave | 当拖拽元素或选中的文本离开一个可释放目标时触发。 |
dragover | ondragover (en-US) | 当元素或选中的文本被拖到一个可释放目标上时触发(每 100 毫秒触发一次)。 |
dragstart | ondragstart (en-US) | 当用户开始拖拽一个元素或选中的文本时触发(见开始拖拽操作 (en-US))。 |
drop | ondrop | 当元素或选中的文本在可释放目标上被释放时触发(见执行释放 (en-US))。 |
注意:当从操作系统向浏览器中拖拽文件时,不会触发 dragstart 和dragend 事件。
HTML 的拖拽接口有 DragEvent, DataTransfer, DataTransferItem 和DataTransferItemList。
DragEvent 接口有一个构造函数和一个 dataTransfer 属性,dataTransfer 属性是一个 DataTransfer 对象。
DataTransfer 对象包含了拖拽事件的状态,例如拖拽事件的类型(如拷贝 copy 或者移动 move),拖拽的数据(一个或者多个项)和每个拖拽项的类型(MIME 类型)。 DataTransfer 对象也有向拖拽数据中添加或删除项目的方法。
给应用程序添加 HTML 拖放功能,DragEvent 和 DataTransfer 接口应该是唯二需要的接口(Firefox 给 DataTransfer 添加了一些 Gecko 专有的扩展功能,但这些扩展只在 Firefox 上可用)。
每个 DataTransfer 都包含一个 items 属性,这个属性是 DataTransferItem 对象的 list。一个 DataTransferItem 代表一个拖拽项目,每个项目都有一个 kind 属性(string 或 file)和一个表示数据项目 MIME 类型的 type 属性。DataTransferItem 对象也有获取拖拽项目数据的方法。
DataTransferItemList 对象是 DataTransferItem 对象的列表。这个列表对象包含以下方法:向列表中添加拖拽项,从列表中移除拖拽项和清空列表中所有的拖拽项。
DataTransfer 和 DataTransferItem 接口的一个主要的不同是前者使用同步的 getData() 方法去得到拖拽项的数据,而后者使用异步的 getAsString() 方法得到拖拽项的数据。
注意:DragEvent 和 DataTransfer 接口是所有桌面浏览器都支持的。但是, DataTransferItem 和DataTransferItemList 接口并不被所有浏览器支持。请移步 互操作性 了解更多关于拖拽行为的信息。
CSS
flex 模型,有哪些属性
采用 Flex 布局的元素,称为 Flex 容器(flex container),简称"容器"。它的所有子元素自动成为容器成员,称为 Flex 项目(flex item),简称"项目"。
容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
回答时候简而言之:弹性布局由父级容器、子容器构成,通过设置主轴和交叉轴来控制子元素的排序方式。
6 个属性设置在容器上:
flex-direction : row | row-reverse | column | column-reverse; flex-direction 是决定主轴的方向,它有四个值对应四个方向,row 是默认值,使主轴是水平的,而且是自西向东的,而 row-reverse 刚好相反,它设定的主轴是自东向西,column 是从北到南,column-reverse 是从南到北
flex-wrap: nowrap | wrap | wrap-reverse; 该属性称"轴线"。nowrap 是默认值,不换行,wrap 换行第一行在上面,wrap-reverse 换行,第一行在下面
flex-flow: flex-direction和flex-wrap的简写形式,默认值为row nowrap。
justify-content: flex-start | flex-end | center | space-between | space-around; 该属性定义了子元素在主轴上的对齐方式。
- flex-start 是左对齐
- flex-end 右对齐
- space-between 是两端对齐,项目之间的间隔都相等
- space-around 每个项目两边的距离是相等的,所以项目之间的距离是项目和边框距离的两倍。
align-items: flex-start | flex-end | center | baseline | stretch; 定义项目在交叉轴上如何对齐。
- flex-start 是交叉轴的起点对齐
- flex-end 交叉轴的终点对齐
- center 交叉轴中点对齐
- baseline 项目的第一行文字的基线对齐
- stretch 如果项目未设置高度,或者设置的为 auto,将填满整个容器的高度
align-content: flex-start | flex-end | center | space-between | space-around | stretch; 属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
- flex-start 与交叉轴的起点对齐
- flex-end 与交叉轴的终点对齐
- center 与交叉轴的中点对齐
- space-btween 与交叉轴的两端对齐,轴线之间的间隔平均分配
- space-around 每根轴线两边的间隔都是相等的,所以轴线之间的间隔是轴线和边框的间隔的两倍
- stretch 轴线占满整个交叉轴
6 个属性设置在子级元素或者容器上。
弹性布局子元素、子容器、项目说的是一个概念子容器
orderflex-growflex-shrinkflex-basisflexalign-self
order 定义项目排列顺序 数值越小,排列越靠前 默认为零
flex-gorw 定义项目的放大比例,默认值为 0,即就算存在剩余空间也不放大,如果所有项目数值为 1 的话就是所有项目等分剩余空间,如果有一个项目的 flex-grow 属性为 2,其余项目都为 1 时,则前者占据的剩余空间是后者的两倍。
flex-shrink 定义了项目的缩小比例,默认值为 1,即如果空间不足的话,所有项目等比例缩小,如果有一个项目的 flex-shrink 的属性为 0,其他项目的为 1,则空间不足时,前者不缩小,后者等比例缩小。
flex-basis 属性定义了,在分配多余空间之前,项目占据的主轴空间(main size),浏览器根据这个属性计算出主轴是否有剩余空间,它的默认值为 auto 即项目本身的大小,它可以设为跟 width 或 height 属性一样的值(比如 350px),则项目将占据固定空间。
flex 属性是 flex-grow,flex-shrink 和 flex-basis 的简写,默认值为 0 1 auto,该属性有两个快捷值 auto(1 1 auto)和 none(0 0 auto)
align-self 属性的话,它允许单个项目与其他项目不一样的对齐方式,可覆盖 align-items 的属性,默认值为 auto,表示继承父元素的属性,如果没有父元素,则等同于 stretch,该属性可能取 6 个值,除了 auto,其他都与 align-items 属性完全一致。
BFC 以及怎样触发,哪些属性可以构成 BFC
BFC(Block Formatting Context)格式化上下文,决定了元素如何对其内容进行定位,以及与其它元素的关系和相互作用,当涉及到可视化布局时,Block Formatting Context提供了一个环境,HTML在这个环境中按照一定的规则进行布局。
- 内部的 Box 会在垂直方向,一个接一个地放置。
- Box 垂直方向的距离由 margin 决定。属于同一个 BFC 的两个相邻 Box 的 margin 会发生重叠。
- 每个元素的 margin box 的左边, 与包含块 border box 的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
- BFC 的区域不会与 float box 重叠。
- BFC 就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
- 计算 BFC 的高度时,浮动元素也参与计算
触发 BFC:
- 根元素或其它包含它的元素
- 浮动
float: left/right/inherit - 绝对定位元素
position: absolute/fixed - 行内块
display: inline-block - 表格单元格
display: table-cell - 表格标题
display: table-caption - 溢出元素
overflow: hidden/scroll/auto/inherit - 弹性盒子
display: flex/inline-flex
BFC 来解决上下的margin 塌陷的问题:把其中一个 box 设置成 bfc,就不在同一个 BOX 里面了
BFC 解决高度塌陷问题:当设置为 float 是,外层容器没有办法撑起来高度了
BFC 清楚浮动问题:浮动元素会脱离文档流,覆盖旁边的内容,将后面这个元素形成 BFC,可以清除浮动造成的影响。
BFC/IFC/GFC/FFC
BFC 全称:Block Formatting Context, 名为 块级格式化上下文
IFC 全称:Inline Formatting Context,名为行级格式化上下文
触发:块级元素中仅包含内联级别元素。
形成条件非常简单,需要注意的是当IFC中有块级元素插入时,会产生两个匿名块将父元素分割开来,产生两个IFC。
场景:
元素水平居中
当一个块要在环境中水平居中时,设置其为inline-block则会在外层产生IFC,通过text-align则可以使其水平居中。
多行文本水平垂直居中
创建一个IFC,然后设置其vertical-align:middle,其他行内元素则可以在此父元素下垂直居中。
GFC全称:Grids Formatting Contexts,名为网格格式上下文
触发:当为一个元素设置display值为grid或者inline-grid的时候,此元素将会获得一个独立的渲染区域。
FFC全称:Flex Formatting Contexts,名为弹性格式上下文
触发:当 display 的值为 flex 或 inline-flex 时,将生成弹性容器(Flex Containers), 一个弹性容器为其内容建立了一个新的弹性格式化上下文环境(FFC)
positon 有哪些属性?static 是什么表现?static 在文档流吗?
允许您从正常的文档流布局中取出元素,并使它们具有不同的行为,例如放在另一个元素的上面,或者始终保持在浏览器视窗内的同一位置。
static:静态定位是每个元素获取的默认值——它只是意味着“将元素放入它在文档布局流中的正常位置 ——这里没有什么特别的。relative:与静态定位非常相似,占据在正常的文档流中,除了你仍然可以修改它的最终位置,包括让它与页面上的其他元素重叠。- 如果不设置 top,right,bottom,left,则基本与 static 表现一致
- 设置了 top,right,bottom,left 后,会使元素做对应的偏移
absolute:绝对定位的元素不再存在于正常文档布局流中。相反,它坐在它自己的层独立于一切。- 绝对定位设置位置偏移之后,是相对于其父级元素
- 如果父级元素为 static ,则会相对于其父级的父级元素,如果没有找到非 static 值的父级元素,则最终会相对于 html
- 相对父级元素是非 static 意味着,父级是 relative、absolute、fixed、sticky 均可
- 最佳实践是用一个 relative 的父级包裹
fixed:固定定位,与 absolute 的唯一区别是,固定定位固定元素则是相对于浏览器视口本身sticky:粘性定位,它基本上是相对位置和固定位置的混合体,它允许被定位的元素表现得像相对定位一样,直到它滚动到某个阈值点(例如,从视口顶部起 10 像素)为止,此后它就变得固定了。- 是相对于视口位置
- 如果这个元素的父级是 body ,则达到其阈值点后,会一直固定在设置的位置
- 如果这个元素的父级是其他元素,则达到其阈值点后,会固定在设置的位置,但是当其父级元素已不在视口中时,则当前元素也会消失在视口中
伪类和伪元素
伪元素在CSS3之前就已经存在,只是没有伪元素的说法,都是归纳为伪类,所有很多人分不清楚伪类和伪元素。比如常用的:before和:after,它们是伪类还是伪元素?其实在CSS3之前被称为伪类,直到CSS3才正式区分出来叫伪元素
那如何区分伪元素和伪类,记住两点:
1. 伪类表示被选择元素的某种状态,例如:hover
2. 伪元素表示的是被选择元素的某个部分,这个部分看起来像一个独立的元素,但是是"假元素",只存在于 css 中,所以叫"伪"的元素,例如:before和:after
核心区别在于,是否创造了“新的元素”
伪元素:
伪类:
样式优先级
!important > 内联样式 > id选择器 > 类选择器 = 伪类选择器 > 元素选择器 > 通配选择器 > 继承
| 选择器 | 优先级(千位,百位,十位,个位) |
|---|---|
| 内联样式 | (1,0,0,0) |
| id 选择器 | (0,1,0,0) |
| 类和伪类选择器 | (0,0,1,0) |
| 元素选择器 | (0,0,0,1) |
| 通配选择器* | (0,0,0,0) |
怎样实现动画?animation、transition、transform、translate 区别
| 属性 | 含义 |
|---|---|
| animation(动画) | 用于设置动画属性,他是一个简写的属性,包含 6 个属性 |
| transition(过渡) | 用于设置元素的样式过度,和 animation 有着类似的效果,但细节上有很大的不同 |
| transform(变形) | 用于元素进行旋转、缩放、移动或倾斜,和设置样式的动画并没有什么关系,就相当于 color 一样用来设置元素的“外表” |
| translate(移动) | translate 只是 transform 的一个属性值,即移动。 |
animation
在官方的介绍上介绍这个属性是 transition 属性的扩展,弥补了 transition 的很多不足,我理解为 animation 是由多个 transition 的效果叠加,并且可操作性更强,能够做出复杂酷炫的效果(前提是你爱折腾),我们以一个例子来介绍 animation 的威力:
<!DOCTYPE html>
<html lang="en">
<head>
<title>animation</title>
<style>
.box {
height: 100px;
width: 100px;
border: 15px solid black;
animation: changebox 1s ease-in-out 1s infinite alternate running
forwards;
}
.box:hover {
animation-play-state: paused;
}
@keyframes changebox {
10% {
background: red;
}
50% {
width: 80px;
}
70% {
border: 15px solid yellow;
}
100% {
width: 180px;
height: 180px;
}
}
</style>
</head>
<body>
<div class="box"></div>
</body>
</html>
语法:animation: name duration timing-function delay iteration-count direction play-state fill-mode;
| 值 | 描述 |
|---|---|
| name | 用来调用@keyframes 定义好的动画,与@keyframes 定义的动画名称一致 |
| duration | 指定元素播放动画所持续的时间 |
| timing-function | 规定速度效果的速度曲线,是针对每一个小动画所在时间范围的变换速率 |
| delay | 定义在浏览器开始执行动画之前等待的时间,指整个 animation 执行之前等待的时间 |
| iteration-count | 定义动画的播放次数,可选具体次数或者无限(infinite) |
| direction | 设置动画播放方向:normal(按时间轴顺序),reverse(时间轴反方向运行),alternate(轮流,即来回往复进行),alternate-reverse(动画先反运行再正方向运行,并持续交替运行) |
| play-state | 控制元素动画的播放状态,通过此来控制动画的暂停和继续,两个值:running(继续),paused(暂停) |
| fill-mode | 控制动画结束后,元素的样式,有四个值:none(回到动画没开始时的状态),forwards(动画结束后动画停留在结束状态),backwords(动画回到第一帧的状态),both(根据 animation-direction 轮流应用 forwards 和 backwards 规则),注意与 iteration-count 不要冲突(动画执行无限次) |
transition
什么叫过渡?字面意思上来讲,就是元素从这个属性(color)的某个值(red)过渡到这个属性(color)的另外一个值(green),这是一个状态的转变,需要一种条件来触发这种转变,比如我们平时用到的:hoever、:focus、:checked、媒体查询或者 JavaScript。
<!DOCTYPE html>
<html lang="en">
<head>
<title>transition</title>
<style>
#box {
height: 100px;
width: 100px;
background: green;
transition: transform 1s ease-in 1s;
}
#box:hover {
transform: rotate(180deg) scale(0.5, 0.5);
}
</style>
</head>
<body>
<div id="box"></div>
</body>
</html>
我们来分析这一整个过程,首先 transition 给元素设置的过渡属性是 transform,当鼠标移入元素时,元素的 transform 发生变化,那么这个时候就触发了 transition,产生了动画,当鼠标移出时,transform 又发生变化,这个时候还是会触发 transition,产生动画,所以 transition 产生动画的条件是 transition 设置的 property 发生变化,这种动画的特点是需要“一个驱动力去触发”,有着以下几个不足:
- 需要事件触发,所以没法在网页加载时自动发生
- 是一次性的,不能重复发生,除非一再触发
- 只能定义开始状态和结束状态,不能定义中间状态,也就是说只有两个状态
- 一条 transition 规则,只能定义一个属性的变化,不能涉及多个属性。
语法:transition: property duration timing-function delay;
| 值 | 描述 |
|---|---|
| transition-property | 规定设置过渡效果的 CSS 属性的名称 |
| transition-duration | 规定完成过渡效果需要多少秒或毫秒 |
| transition-timing-function | 规定速度效果的速度曲线 |
| transition-delay | 定义过渡效果何时开始 |
transform
transform: none|transform-functions;
| none | 定义不进行转换。 |
|---|---|
| matrix(n,n,n,n,n,n) | 定义 2D 转换,使用六个值的矩阵。 |
| matrix3d(n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n) | 定义 3D 转换,使用 16 个值的 4x4 矩阵。 |
| translate(x,y) | 定义 2D 转换。 |
| translate3d(x,y,z) | 定义 3D 转换。 |
| translateX(x) | 定义转换,只是用 X 轴的值。 |
| translateY(y) | 定义转换,只是用 Y 轴的值。 |
| translateZ(z) | 定义 3D 转换,只是用 Z 轴的值。 |
| scale(x[,y]?) | 定义 2D 缩放转换。 |
| scale3d(x,y,z) | 定义 3D 缩放转换。 |
| scaleX(x) | 通过设置 X 轴的值来定义缩放转换。 |
| scaleY(y) | 通过设置 Y 轴的值来定义缩放转换。 |
| scaleZ(z) | 通过设置 Z 轴的值来定义 3D 缩放转换。 |
| rotate(angle) | 定义 2D 旋转,在参数中规定角度。 |
| rotate3d(x,y,z,angle) | 定义 3D 旋转。 |
| rotateX(angle) | 定义沿着 X 轴的 3D 旋转。 |
| rotateY(angle) | 定义沿着 Y 轴的 3D 旋转。 |
| rotateZ(angle) | 定义沿着 Z 轴的 3D 旋转。 |
| skew(x-angle,y-angle) | 定义沿着 X 和 Y 轴的 2D 倾斜转换。 |
| skewX(angle) | 定义沿着 X 轴的 2D 倾斜转换。 |
| skewY(angle) | 定义沿着 Y 轴的 2D 倾斜转换。 |
| perspective(n) | 为 3D 转换元素定义透视视图。 |
如何画一条 0.5px 的边框
什么是像素?
像素是屏幕显示最小的单位,在一个 1080p 的屏幕上,它的像素数量是 1920 1080,即横边有 1920 个像素,而竖边为 1080 个。一个像素就是一个单位色块,是由 rgba 四个通道混合而成。对于一个 1200 万像素的相机镜头来说,它有 1200 万个感光单元,它能输出的最大图片分辨率大约为 3000 4000。
怎么在高清屏上画一条 0.5px 的边呢?0.5px 相当于高清屏物理像素的 1px。这样的目的是在高清屏上看起来会更细一点,效果会更好一点,例如更细的分隔线。
1.直接写 0.5px,不兼容。 2.transform 的 scale。 3.linear-gradient,渐变。 4.SVG。 5.box-shadow。 6.meta 中的 viewport。
CSS 垂直居中的方案
1、absolute + 负 margin
/* 定位代码 */
.wp {
position: relative;
}
.box {
position: absolute;
top: 50%;
left: 50%;
margin-left: -50px;
margin-top: -50px;
}
//缺点是需要知道子元素的宽高
2、absolute + margin auto
.wp {
position: relative;
}
.box {
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
margin: auto;
}
//缺点是需要知道子元素的宽高
3、absolute + calc
/* 此处引用上面的公共代码 */
/* 此处引用上面的公共代码 */
/* 定位代码 */
.wp {
position: relative;
}
.box {
position: absolute;
top: calc(50% - 50px);
left: calc(50% - 50px);
}
//缺点是需要知道子元素的宽高
4、absolute + transform
/* 此处引用上面的公共代码 */
/* 此处引用上面的公共代码 */
/* 定位代码 */
.wp {
position: relative;
}
.box {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
5、lineheight
/* 此处引用上面的公共代码 */
/* 此处引用上面的公共代码 */
/* 定位代码 */
.wp {
line-height: 300px;
text-align: center;
font-size: 0px;
}
.box {
font-size: 16px;
display: inline-block;
vertical-align: middle;
line-height: initial;
text-align: left; /* 修正文字 */
}
6、writing-mode:单来说 writing-mode 可以改变文字的显示方向,比如可以通过 writing-mode 让文字的显示变为垂直方向
<div class="div1">水平方向</div>
<div class="div2">垂直方向</div>
.div2 {
writing-mode: vertical-lr;
}
水平方向
垂
直
方
向
更神奇的是所有水平方向上的css属性,都会变为垂直方向上的属性,比如text-align,通过writing-mode和text-align就可以做到水平和垂直方向的居中了,只不过要稍微麻烦一点
<div class="wp">
<div class="wp-inner">
<div class="box">123123</div>
</div>
</div>
.wp {
writing-mode: vertical-lr;
text-align: center;
}
.wp-inner {
writing-mode: horizontal-tb;
display: inline-block;
text-align: center;
width: 100%;
}
.box {
display: inline-block;
margin: auto;
text-align: left;
}
7、table:tabel 单元格中的内容天然就是垂直居中的,只要添加一个水平居中属性就好了
.wp {
text-align: center;
}
.box {
display: inline-block;
}
8、css-table:css 新增的 table 属性,可以让我们把普通元素,变为 table 元素的现实效果,通过这个特性也可以实现水平垂直居中
.wp {
display: table-cell;
text-align: center;
vertical-align: middle;
}
.box {
display: inline-block;
}
9、flex
.wp {
display: flex;
justify-content: center;
align-items: center;
}
10、grid
.wp {
display: grid;
}
.box {
align-self: center;
justify-self: center;
}
响应式布局方案
- 媒体查询
- 百分比布局
- rem 布局
- vw/vh/wmin/vmax 视图窗口
- flex
- grid
如何提高动画的渲染性能
- 硬件加速 transform: translateZ(0); backface-visibility: hidden;
- requestAnimationFrame
- 16ms 目标
- 渲染层
怎样实现三列布局
1、float
2、position absolute。 left=0
3、flex
4、gird
visibility、display、opacity 的区别
display: none;
- DOM 结构:浏览器不会渲染 display 属性为 none 的元素,不占据空间;
- 事件监听:无法进行 DOM 事件监听;
- 性能:动态改变此属性时会引起重排,性能较差;
- 继承:不会被子元素继承,毕竟子类也不会被渲染;
- transition:transition 不支持 display。
visibility: hidden;
- DOM 结构:元素被隐藏,但是会被渲染不会消失,占据空间;
- 事件监听:无法进行 DOM 事件监听;
- 性 能:动态改变此属性时会引起重绘,性能较高;
- 继 承:会被子元素继承,子元素可以通过设置 visibility: visible; 来取消隐藏;
- transition:visibility 会立即显示,隐藏时会延时
opacity: 0;
- DOM 结构:透明度为 100%,元素隐藏,占据空间;
- 事件监听:可以进行 DOM 事件监听;
- 性 能:提升为合成层,不会触发重绘,性能较高;
- 继 承:会被子元素继承,且,子元素并不能通过 opacity: 1 来取消隐藏;
- transition:opacity 可以延时显示和隐藏
TypeScript
ts 和 js 区别,ts 有什么用,有什么优势和劣势
Typescript 是一个强类型的 JavaScript 超集,支持 ES6 语法,支持面向对象编程的概念,如类、接口、继承、泛型等。Typescript 并不直接在浏览器上运行,需要编译器编译成纯 Javascript 来运行。增加了静态类型,可以在开发人员编写脚本时检测错误,使得代码质量更好,更健壮。
Typescript 是 JavaScript 的超集,可以被编译成 JavaScript 代码。用 JavaScript 编写的代码,在 TypeScript 中依然有效。Typescript 是纯面向对象的编程语言,包含类和接口的概念。 程序员可以用它来编写面向对象的服务端或客户端程序,并将它们编译成 JavaScript 代码。
优势:
- 杜绝手误导致的变量名写错;
- 类型可以一定程度上充当文档;
- IDE 自动填充,自动联想;
说说 TypeScript 中命名空间与模块的理解和区别
命名空间:命名空间一个最明确的目的就是解决重名问题
命名空间定义了标识符的可见范围,一个标识符可在多个名字空间中定义,它在不同名字空间中的含义是互不相干的
这样,在一个新的名字空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其他名字空间中
模块:TypeScript 与 ECMAScript 2015 一样,任何包含顶级 import 或者 export 的文件都被当成一个模块
相反地,如果一个文件不带有顶级的import或者export声明,那么它的内容被视为全局可见的
它们之间的区别:
- 命名空间是位于全局命名空间下的一个普通的带有名字的 JavaScript 对象,使用起来十分容易。但就像其它的全局命名空间污染一样,它很难去识别组件之间的依赖关系,尤其是在大型的应用中
- 像命名空间一样,模块可以包含代码和声明。 不同的是模块可以声明它的依赖
- 在正常的 TS 项目开发过程中并不建议用命名空间,但通常在通过 d.ts 文件标记 js 库类型的时候使用命名空间,主要作用是给编译器编写代码的时候参考使用
TypeScript 支持的访问修饰符有哪些?
TypeScript 支持访问修饰符 public,private 和 protected,它们决定了类成员的可访问性。
- 公共(public),类的所有成员,其子类以及该类的实例都可以访问。
- 受保护(protected),该类及其子类的所有成员都可以访问它们。 但是该类的实例无法访问。
- 私有(private),只有类的成员可以访问它们。
readonly: 关键字将属性设置为只读的。 只读属性必须在声明时或构造函数里被初始化。
如果未指定访问修饰符,则它是隐式公共的,因为它符合 JavaScript 的便利性。
TypeScript 中的 Declare 关键字有什么作用?
我们知道所有的 JavaScript 库/框架都没有 TypeScript 声明文件,但是我们希望在 TypeScript 文件中使用它们时不会出现编译错误。为此,我们使用 declare 关键字。在我们希望定义可能存在于其他地方的变量的环境声明和方法中,可以使用 declare 关键字。
例如,假设我们有一个名为 myLibrary 的库,它没有 TypeScript 声明文件,在全局命名空间中有一个名为 myLibrary 的命名空间。如果我们想在 TypeScript 代码中使用这个库,我们可以使用以下代码:
declare let myLibrary;
TypeScript 运行时将把 myLibrary 变量赋值为任意类型(any)。这是一个问题,我们不会得到智能感知在设计时,但我们将能够使用库在我们的代码。
declare 是用来定义全局变量、全局函数、全局命名空间、js modules、class 等
declare global 为全局对象 window 增加新的属性
declare global {
interface Window {
csrf: string;
}
}
解释一下 TypeScript 中的枚举
枚举是 TypeScipt 数据类型,它允许我们定义一组命名常量。 使用枚举去创建一组不同的案例变得更加容易。 它是相关值的集合,可以是数字值或字符串值。
enum Gender {
Male,
Female,
Other,
}
console.log(Gender.Male); // Output: 0
//We can also access an enum value by it's number value.
console.log(Gender[1]); // Output: Female
TypeScript 中什么是装饰器?
装饰器是一种特殊类型的声明,它能过被附加到类声明,方法,属性或者参数上,可以修改类的行为
通俗的来说就是一个方法,可以注入到类,方法,属性参数上来扩展类,属性,方法,参数的功能
装饰器的分类: 类装饰器、属性装饰器、方法装饰器、参数装饰器
TypeScript 中 never 和 void 的区别?
- void 表示没有任何类型(可以被赋值为 null 和 undefined)。
- never 表示一个不包含值的类型,即表示永远不存在的值。
- 拥有 void 返回值类型的函数能正常运行。拥有 never 返回值类型的函数无法正常返回,无法终止,或会抛出异常。
TypeScript 中的类型断言是什么?
类型断言(as)可以用来手动指定一个值具体的类型,即允许变量从一种类型更改为另一种类型。
当你比 TS 更了解某个值的类型,并且需要指定更具体的类型时,我们可以使用类型断言。
在特定的环境中,我们会比 TS 知道这个值具体是什么类型,不需要 TS 去判断,简单的理解就是,类型断言会告诉编译器,你不用给我进行检查,相信我,他就是这个类型
共有两种方式:
- 尖括号
- as:推荐
//尖括号
let num: any = "小杜杜";
let res1: number = (<string>num).length; // React中会 error
// as 语法
let str: any = "Domesy";
let res: number = (str as string).length;
但需要注意的是:尖括号语法在React中会报错,原因是与JSX语法会产生冲突,所以只能使用as 语法
TS 中 any 和 unknown 有什么区别?
unknown 和 any 的主要区别是 unknown 类型会更加严格:在对 unknown 类型的值执行大多数操作之前,我们必须进行某种形式的检查。而在对 any 类型的值执行操作之前,我们不必进行任何检查。
let foo: any = 123;
console.log(foo.msg); // 符合TS的语法
let a_value1: unknown = foo; // OK
let a_value2: any = foo; // OK
let a_value3: string = foo; // OK
let bar: unknown = 222; // OK
console.log(bar.msg); // Error
let k_value1: unknown = bar; // OK
let K_value2: any = bar; // OK
let K_value3: string = bar; // Error
因为 bar 是一个未知类型(任何类型的数据都可以赋给 unknown 类型),所以不能确定是否有 msg 属性。不能通过 TS 语法检测;而 unknown 类型的值也不能将值赋给 any 和 unknown 之外的类型变量
总结: any 和 unknown 都是顶级类型,但是 unknown 更加严格,不像 any 那样不做类型检查,反而 unknown 因为未知性质,不允许访问属性,不允许赋值给其他有明确类型的变量。
TS 中什么是方法重载?
方法重载是指在一个类中定义多个同名的方法,但要求每个方法具有不同的参数的类型或参数的个数。 基本上,它在派生类或子类中重新定义了基类方法。
方法覆盖规则:
- 该方法必须与父类中的名称相同。
- 它必须具有与父类相同的参数。
- 必须存在 IS-A 关系或继承。
重写和重载
- 重写:子类重写继承自父类中的方法
- 重载:指为同一个函数提供多个类型定义,与上述函数的重载类似
怎样编译 ts,编译原理
interface 和 type 区别
相同点:
- 都可以描述 '对象' 或者 '函数'
- 都允许拓展(extends)
不同点:
- type 可以声明基本类型,联合类型,元组
- type 可以使用 typeof 获取实例的类型进行赋值
- 多个相同的 interface 声明可以自动合并
使用 interface 描述‘数据结构’,使用 type 描述‘类型关系’
同名的 interface 会自动合并,同名的 interface 和 class 会自动聚合。
类型别名和接口非常相似,可以说在大多数情况下,type与interface是等价的
但在一些特定的场景差距还是比较大的,接下来逐个来看看
基础数据类型
type和interface都可以定义 对象 和 函数type可以定义其他数据类型,如字符串、数字、元祖、联合类型等,而interface不行
type A = string; // 基本类型
type B = string | number; // 联合类型
type C = [number, string]; // 元祖
const dom = document.createElement("div"); // dom元素
type D = typeof dom;
扩展
interface 可以扩展 type,type 也可以扩展为 interface,但两者实现扩展的方式不同。
interface是通过extends来实现type是通过&来实现
// interface 扩展 interface
interface A {
a: string;
}
interface B extends A {
b: number;
}
const obj: B = { a: `小杜杜`, b: 7 };
// type 扩展 type
type C = { a: string };
type D = C & { b: number };
const obj1: D = { a: `小杜杜`, b: 7 };
// interface 扩展为 Type
type E = { a: string };
interface F extends E {
b: number;
}
const obj2: F = { a: `小杜杜`, b: 7 };
// type 扩展为 interface
interface G {
a: string;
}
type H = G & { b: number };
const obj3: H = { a: `小杜杜`, b: 7 };
重复定义
interface 可以多次被定义,并且会进行合并,但type不行
interface A {
a: string;
}
interface A {
b: number;
}
const obj: A = { a: `小杜杜`, b: 7 };
type B = { a: string };
type B = { b: number }; // error
TS 中的泛型是什么?
泛型:Generics,是指在定义函数、接口或类的时候,不预先指定具体的类型,而在使用的时候再指定类型的一种特性
也就是说,泛型是允许同一个函数接受不同类型参数的一种模版,与any相比,使用泛型来创建可服用的组件要更好,因为泛型会保留参数类型(PS:泛型是整个 TS 的重点,也是难点,请多多注意~)
TypeScript Generics 是提供创建可重用组件的方法的工具。 它能够创建可以使用多种数据类型而不是单一数据类型的组件。 而且,它在不影响性能或生产率的情况下提供了类型安全性。 泛型允许我们创建泛型类,泛型函数,泛型方法和泛型接口。
在泛型中,类型参数写在左括号(<)和右括号(>)之间,这使它成为强类型集合。 它使用一种特殊的类型变量来表示类型
function identity<T>(arg: T): T {
return arg;
}
let output1 = identity<string>("CoderBin");
let output2 = identity<number>(117);
console.log(output1);
console.log(output2);
解释如何使用 TypeScript mixin
- 有时候,我们会认为声明一个同时继承两个或多个类的类是一个好的想法。
- 为了避免多继承实现中潜在的危险,我们可以使用 mixin 特性。
- 首先是两个基类
class Mammal {
breathe(): string {
return "I'm alive!";
}
}
class WingedAnimal {
fly(): string {
return "I can fly!";
}
}
- 下面是子类,使用
implements替代extends,因此继承自的类仍需要实现,这里只是占坑
class Bat implements Mammal, WingedAnimal {
breathe: () => string;
fly: () => string;
}
使用以下函数,将基类的方法实现/复制到子类中
function applyMixins(derivedCtor: any, baseCtors: any[]) {
baseCtors.forEach((baseCtor) => {
// 即是将“父类”原型对象中的属性,复制到子类的原型对象中
Object.getOwnPropertyNames(baseCtor.prototype).forEach((name) => {
if (name !== "constructor") {
derivedCtor.prototype[name] = baseCtor.prototype[name];
}
});
});
}
// 实现子类函数
applyMixins(bat, [Mammal, WingedAnimal]);
mixin 的限制
- 只能在继承树上继承一级的方法和属性。因为编译过后,在 JavaScript 中,父类的方法是在父类的原型对象中,子类的原型对象上找不到父类的方法。
- 如果两个或更多的父类包含了同名的方法,那么只会继承传入
applyMixins函数中baseCtor数组中最后一个类中的该方法。
TS 中的类型有哪些?
类型系统表示语言支持的不同类型的值。它在程序存储或操作所提供的值之前检查其有效性。
它可以分为两种类型,
- 内置:包括数字(number),字符串(string),布尔值(boolean),无效(void),空值(null)和未定义(undefined)。
- 用户定义的:它包括枚举(enums),类(classes),接口(interfaces),数组(arrays)和元组(tuple)。
is 关键字是做什么的
is 关键字一般用于函数返回值类型中,判断参数是否属于某一类型,并根据结果返回对应的布尔类型。
is 操作符用于 TS 的类型谓词中,是实现 TS 类型保护的一种方式(关于什么是类型保护)。
比如下面这种场景:
function doSometing(value: string | number) {
if (typeof value === "string") {
// TS 可以识别这个分支中 value 是 string 类型的参数(这就叫类型保护)
// do something
} else {
// TS 可以识别这个分支中 value 是 number 类型的参数
// do something
}
}
除去上面这种方式以外,我们可以使用 TS 的类型谓词来实现:
/**
* 此函数用于判断参数 value 是不是 string 类型
*
* 由于返回类型声明了类型谓词,可以帮助TS在代码分支中进行类型保护(默认返回 boolean 类型是没办法做到的)
**/
function isString(value: any): value is string {
return typeof value === 'string';
}
function doSometing(value: string | number) {
if (isString(value)) {
// TS 可以识别这个分支中 value 是 string 类型的参数(这就叫类型保护)
} else {
// TS 可以识别这个分支中 value 是 number 类型的参数
}
}
这样做的好处是:实现了代码复用,实现了更好的语义化。
其实,TS 代码中 Array.isArray 便是使用了这样的声明。
interface ArrayConstructor {
// ...
isArray(arg: any): arg is Array<any>;
}
Partial、Required、Readonly 是什么?
Partial 语法:Partial<T> 作用:将所有属性变为可选的 ?
interface Props {
name: string;
age: number;
}
const info: Props = {
name: "小杜杜",
age: 7,
};
const info1: Partial<Props> = {
name: "小杜杜",
};
从上述代码上来看,name 和 age 属于必填,对于 info 来说必须要设置 name 和 age 属性才行,但对于 info1 来说,只要是个对象就可以,至于是否有 name、 age 属性并不重要。
Required 语法:Required<T> 作用:将所有属性变为必选的,与 Partial相反
interface Props {
name: string;
age: number;
sex?: boolean;
}
const info: Props = {
name: "小杜杜",
age: 7,
};
const info1: Required<Props> = {
name: "小杜杜",
age: 7,
sex: true,
};
语法:Readonly<T> 作用:将所有属性都加上 readonly 修饰符来实现。也就是说无法修改
interface Props {
name: string;
age: number;
}
let info: Readonly<Props> = {
name: "小杜杜",
age: 7,
};
info.age = 1; //error read-only 只读属性
从上述代码上来看, Readonly修饰后,属性无法再次更改,只能使用
Record 和 Pick 有什么区别?
Record 语法:Record<K extends keyof any, T>
作用:将 K 中所有的属性的值转化为 T 类型。
interface Props {
name: string;
age: number;
}
type InfoProps = "JS" | "TS";
const Info: Record<InfoProps, Props> = {
JS: {
name: "小杜杜",
age: 7,
},
TS: {
name: "TypeScript",
age: 11,
},
};
从上述代码上来看, InfoProps的属性分别包含Props的属性
需要注意的一点是:K extends keyof any其类型可以是:string、number、symbol
Pick 语法:Pick<T, K extends keyof T>
作用:将某个类型中的子属性挑出来,变成包含这个类型部分属性的子类型。
interface Props {
name: string;
age: number;
sex: boolean;
}
type nameProps = Pick<Props, "name" | "age">;
const info: nameProps = {
name: "小杜杜",
age: 7,
};
从上述代码上来看, Props原本属性包括name、age、sex三个属性,通过 Pick我们吧name和age挑了出来,所以不需要sex属性
Exclude、Extra、Omit 区别?
Exclude 语法:Exclude<T, U>
作用:将 T 类型中的 U 类型剔除。
// 数字类型
type numProps = Exclude<1 | 2 | 3, 1 | 2>; // 3
type numProps1 = Exclude<1, 1 | 2>; // nerver
type numProps2 = Exclude<1, 1>; // nerver
type numProps3 = Exclude<1 | 2, 7>; // 1 2
// 字符串类型
type info = "name" | "age" | "sex";
type info1 = "name" | "age";
type infoProps = Exclude<info, info1>; // "sex"
// 类型
type typeProps = Exclude<string | number | (() => void), Function>; // string | number
// 对象
type obj = { name: 1; sex: true };
type obj1 = { name: 1 };
type objProps = Exclude<obj, obj1>; // nerver
从上述代码上来看,我们比较了下类型上的,当 T 中有 U 就会剔除对应的属性,如果 U 中又的属性 T 中没有,或 T 和 U 刚好一样的情况都会返回 nerver,且对象永远返回nerver
Extra 语法:Extra<T, U>
作用:将 T 可分配给的类型中提取 U。与 Exclude相反
type numProps = Extract<1 | 2 | 3, 1 | 2>; // 1 | 2
Omit 语法:Omit<T, U>
作用:将已经声明的类型进行属性剔除获得新类型
与 Exclude的区别:Omit 返回的是新的类型,原理上是在 Exclude之上进行的,Exclude是根据自类型返回的
ts 如何函数重载
允许创建数项名称相同但输入输出类型或个数不同的子程序,它可以简单地称为一个单独功能可以执行多项任务的能力
关于typescript函数重载,必须要把精确的定义放在前面,最后函数实现时,需要使用 |操作符或者?操作符,把所有可能的输入类型全部包含进去,用于具体实现
这里的函数重载也只是多个函数的声明,具体的逻辑还需要自己去写,typescript并不会真的将你的多个重名 function 的函数体进行合并
例如我们有一个 add 函数,它可以接收 string类型的参数进行拼接,也可以接收 number 类型的参数进行相加,如下:
// 上边是声明
function add(arg1: string, arg2: string): string;
function add(arg1: number, arg2: number): number;
// 因为我们在下边有具体函数的实现,所以这里并不需要添加 declare 关键字
// 下边是实现
function add(arg1: string | number, arg2: string | number) {
// 在实现上我们要注意严格判断两个参数的类型是否相等,而不能简单的写一个 arg1 + arg2
if (typeof arg1 === "string" && typeof arg2 === "string") {
return arg1 + arg2;
} else if (typeof arg1 === "number" && typeof arg2 === "number") {
return arg1 + arg2;
}
}
函数重载:是使用相同名称和不同参数数量或类型创建多个方法的一种能力。 在 TypeScript 中,表现为给同一个函数提供多个函数类型定义。 简单的说:可以在同一个函数下定义多种类型值,最后汇总到一块
let obj: any = {};
function setInfo(val: string): void;
function setInfo(val: number): void;
function setInfo(val: boolean): void;
function setInfo(val: string | number | boolean): void {
if (typeof val === "string") {
obj.name = val;
} else {
obj.age = val;
}
}
setInfo("Domesy");
setInfo(7);
setInfo(true);
console.log(obj); // { name: 'Domesy', age: 7 }
ts 元组和数组的区别
那么 Tuple 的作用就是限制元素的类型并且限制个数的数组,同时 Tuple这个概念值存在于TS,在JS上是不存在的
这里存在一个问题:在TS中,是允许对 Tuple 扩增的(也就是允许使用 push方法),但在访问上不允许
元祖类型是一种特殊的数据结构,其实元祖就是一个明确元素数量以及每个元素类型的一个数组。各个元素的类型,不必要完全的相同。在 TS 中可以使用类似数组字面量的这种语法去定义,如果想去访问元祖中的某个元素仍然可以使用数组下标的方式去访问。
const tuple:[number, string] = [18, 'leo'];
const age = tuple[0];
const name = tuple[1];
或者
const [age, name] = tuple
元祖一般用来在一个函数当中返回多个返回值,这种类型在现在越来越常见,比如在 React 当中使用 hooks 还有在 ES2017 中使用 Object.entries() 获取一个对象的键值数组。
const [state, setState] = useState();
const obj = {
foo: 123,
bar: 456,
};
Object.entries(obj); // ['foo', 123], ['bar', 456]
//最简单的方法是使用「类型 + 方括号」来表示数组:
let arrOfNumbers: number[] = [1, 2, 3, 4];
//数组的项中不允许出现其他的类型:
//数组的一些方法的参数也会根据数组在定义时约定的类型进行限制:
arrOfNumbers.push(3);
arrOfNumbers.push("abc");
// 元祖的表示和数组非常类似,只不过它将类型写在了里面 这就对每一项起到了限定的作用
let user: [string, number] = ["viking", 20];
//但是当我们写少一项 就会报错 同样写多一项也会有问题
user = ["molly", 20, true];
const func = (a, b) => a + b; 要求编写 Typescript,要求 a,b 参数类型一致,都为 number 或者都为 string
type Combinable = string | number;
function isString(param: unknown): param is string {
return typeof param === "string";
}
// 我实际期望这个函数的返回值能是T类型,但是会报错说返回的string或number与T的实例类型不匹配
// 问题1: 如何修复这个泛型函数?(不使用函数重载)
/* Type 'number' is not assignable to type 'T'.
'number' is assignable to the constraint of type 'T', but 'T' could be instantiated with a different subtype of constraint 'Combinable'.ts(2322) */
function add<T extends Combinable>(a: T, b: T): T {
if (isString(a)) {
// 问题2:这里为什么TS又只能确定a,b是Combinable的子类型,而不是a与b实际类型完全相同,也就是string | number
//type ta = typeof a; // 结果是 string & T === string
//type tb = typeof b; // 结果是 T 为什么TS不能确定和a一样也是string呢
return a + b;
} else {
return (a as number) + (b as number);
}
}
let a: Combinable = "123";
let b: Combinable = 123;
// 问题3:这里为何TS能推断出来a,b必须是实际上的相同类型,比如都是string或者都是number
add(a, b);
实现 ReturnType
ReturnType 语法:ReturnType<T>
作用:用于获取 函数 T 的返回类型。
type Props = ReturnType<() => string>; // string
type Props1 = ReturnType<<T extends U, U extends number>() => T>; // number
type Props2 = ReturnType<any>; // any
type Props3 = ReturnType<never>; // any
从上述代码上来看, ReturnType 可以接受 any 和 never 类型,原因是这两个类型属于顶级类型,包含函数
type Foo = () => { a: string };
type A = MyReturnType<Foo>; // {a: string}
// 实现MyReturnType<T>
type MyReturnType<T extends (...params: any[]) => any> = T extends (
...params: any[]
) => infer P
? P
: never;
实现 Readonly
type Foo = {
a: string;
};
const a: Foo = {
a: "BFE.dev",
};
a.a = "bigfrontend.dev";
// OK
const b: MyReadonly<Foo> = {
a: "BFE.dev",
};
b.a = "bigfrontend.dev";
// Error
// 实现MyReadonly
type MyReadonly<T> = {
readonly [K in keyof T]: T[K];
};
基于已有类型生成新类型:剔除类型中的 width 属性
interface A {
content: string;
width: number;
height: number;
}
infer 关键字作用
infer 最早出现在此 PR 中,表示在 extends 条件语句中待推断的类型变量。
简单示例如下:
type ParamType<T> = T extends (param: infer P) => any ? P : T;
在这个条件语句 T extends (param: infer P) => any ? P : T 中,infer P 表示待推断的函数参数。
整句表示为:如果 T 能赋值给 (param: infer P) => any,则结果是 (param: infer P) => any 类型中的参数 P,否则返回为 T。
interface User {
name: string;
age: number;
}
type Func = (user: User) => void;
type Param = ParamType<Func>; // Param = User
type AA = ParamType<string>; // string
infer:可以是使用为条件语句,可以用 infer 声明一个类型变量并且对它进行使用。如
type Info<T> = T extends { a: infer U; b: infer U } ? U : never;
type Props = Info<{ a: string; b: number }>; // Props类: string | number
type Props1 = Info<number>; // Props类型: never
keyof 和 typeof 关键字的作用?
keyof 索引类型查询操作符 获取索引类型的属性名,构成联合类型。
typeof 获取一个变量或对象的类型。
数组定义的两种方式
type Foo = Array<string>;
interface Bar {
baz: Array<{ name: string; age: number }>;
}
type Foo = string[];
interface Bar {
baz: { name: string; age: number }[];
}
TypeScript 中 ?. ?? ! !. _ 等符号的含义?
?. 可选链 遇到 null 和 undefined 可以立即停止表达式的运行。
?? 空值合并运算符 当左侧操作数为 null 或 undefined 时,其返回右侧的操作数,否则返回左侧的操作数。
! 非空断言运算符 x! 将从 x 值域中排除 null 和 undefined
!. 在变量名后添加,可以断言排除 undefined 和 null 类型
_ 数字分割符 分隔符不会改变数值字面量的值,使人更容易读懂数字 .e.g 1_101_324。
** 求幂
const 和 readonly 的区别
- const 用于变量,readonly 用于属性
- const 在运行时检查,readonly 在编译时检查
- 使用 const 变量保存的数组,可以使用 push,pop 等方法。但是如果使用
ReadonlyArray<number>声明的数组不能使用 push,pop 等方法。
ts 中如何枚举联合类型的 key?
type Name = { name: string };
type Age = { age: number };
type Union = Name | Age;
type UnionKey<P> = P extends infer P ? keyof P : never;
type T = UnionKey<Union>;
什么是抗变、双变、协变和逆变?
- Covariant 协变,TS 对象兼容性是协变,父类 <= 子类,是可以的。子类 <= 父类,错误。
- Contravariant 逆变,禁用
strictFunctionTypes编译,函数参数类型是逆变的,父类 <= 子类,是错误。子类 <= 父类,是可以的。 - Bivariant 双向协变,函数参数的类型默认是双向协变的。父类 <= 子类,是可以的。子类 <= 父类,是可以的。
implements 与 extends 的区别
- extends, 子类会继承父类的所有属性和方法。
- implements,使用 implements 关键字的类将需要实现需要实现的类的所有属性和方法。
React
setState 是同步还是异步
分为 2 种情况:
如下同样一个组件
// Test.jsx
import { Component } from "react";
export default class Tset extends Component<any, any> {
constructor(props: any) {
super(props);
this.state = {
count: 0,
};
}
componentDidMount() {
// 同步调用
this.setState({ count: 1 });
console.log(this.state.count, "第1次调用");
this.setState({ count: 2 });
console.log(this.state.count, "第2次调用"); // 异步调用
setTimeout(() => {
this.setState({ count: 3 });
console.log(this.state.count, "第3次调用");
this.setState({ count: 4 });
console.log(this.state.count, "第4次调用");
});
}
render() {
console.log("render:", this.state.count);
return <div>{this.state.count}</div>;
}
}
legacy 模式:
//index.js
import ReactDOM from "react-dom";
ReactDOM.render(<App />, document.getElementById("root"));
// =============Test.jsx 打印输出 ==========
// render: 0
// 0 '第1次调用'
// 0 '第2次调用'
// render: 2
// render: 3
// 3 '第3次调用'
// render: 4
// 4 '第4次调用'
同步逻辑下执行的 setState,是异步更新的,而在 setTimeout 异步逻辑中执行的 setState,是同步更新的。 要注意的是,legacy 在 setTimout 中没有将多次调用更新合并为 1 次。在 react17 中,setState 是批量执行的,因为执行前会设置 executionContext。但如果在 setTimeout、事件监听器等函数里,就不会设置 executionContext 了,这时候 setState 会同步执行。可以在外面包一层 batchUpdates 函数,手动设置下 excutionContext 来切换成异步批量执行。
引起同步异步更新不一致的原因是 react 在执行渲染过程中,在同步环境下会处在 react 的上下文中,react 会合并处理更新,但是如果在异步环境中,该上下文已经不存在,所以是同步执行。
concurrent 模式:
//index.js
import ReactDOM from "react-dom/client";
const root = ReactDOM.createRoot(
document.getElementById("root") as HTMLElement
);
root.render(<App />);
// =============Test.jsx 打印输出 ==========
// render: 0
// 0 '第1次调用'
// 0 '第2次调用'
// render: 2
// 2 '第3次调用'
// 2 '第4次调用'
// render: 4
并发模式下,无论是在同步逻辑还是异步逻辑里,更新都是异步执行的。 要注意的是,并发模式下,同时先后调用 setState,是会批量合并为 1 次更新的,不会出发多次更新。在 react18 里面,setState 是同步还是异步这个问题等 react18 普及以后就不会再有了,因为所有的 setState 都是异步批量执行了。
最新 react18 中,处于性能考虑,react 会把 setState 的多次调用合并为 1 个调用,且更新为异步执行,因此后面的 setState 不要直接依赖上一个 setState 的调用更新后的 state,而是使用函数形式,从入参中获得上一个更新后的 state。
设置成异步的原因是为了合并短时间内的多次更新,减少渲染次数,提高性能。
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number
) {
if (lane === SyncLane) {
// legacy或blocking模式
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
performSyncWorkOnRoot(root);
} else {
ensureRootIsScheduled(root, eventTime); // 注册回调任务
if (executionContext === NoContext) {
flushSyncCallbackQueue(); // 取消schedule调度 ,主动刷新回调队列,
}
}
} else {
// concurrent模式
ensureRootIsScheduled(root, eventTime);
}
}
当lane === SyncLane也就是 legacy 或 blocking 模式中, 注册完回调任务之后(ensureRootIsScheduled(root, eventTime)), 如果执行上下文为空, 会取消 schedule 调度, 主动刷新回调队列flushSyncCallbackQueue().
这里包含了一个热点问题(setState到底是同步还是异步)的标准答案:
- 如果逻辑进入
flushSyncCallbackQueue(executionContext === NoContext), 则会主动取消调度, 并刷新回调, 立即进入fiber树构造过程. 当执行setState下一行代码时,fiber树已经重新渲染了, 故setState体现为同步. - 正常情况下, 不会取消
schedule调度. 由于schedule调度是通过MessageChannel触发(宏任务), 故体现为异步.
React 合成事件是如何实现的
SyntheticEvent 是浏览器原生事件的包装,除了兼容所有浏览器外,还拥有和浏览器事件相同的接口,如 stopPropagation() 和 preventDefault()。其存在的目的是消除不同浏览器之间对“事件对象”上的差异。
合成事件会模拟浏览器的事件捕获和事件冒泡的传播机制。
其实现如下:
1、通过 addEvent 方法,在根元素上绑定“指定事件类型对应的事件回调”,所有子元素触发该事件都会根据事件委托机制冒泡到根元素的这个回调上;
2、根元素触发 dispatchEvent,通过触发事件的 DOM 元素(e.target),寻找这个 DOM 节点对应的 fiberNode。(注:react 会给所有 render 的 dom 节点上添加 fiber 相关属性);
3、收集从当前 fibernode 到 HostRootFiber 之间所有“注册该事件的回调函数”,也就是不断往上遍历 fiber 树,寻找所有 fibernode 上监听这个事件的回调函数,主要是从 fibernode 的 memoizedProps 属性上查找;
4、反向遍历并执行一遍所有回调函数,模拟事件捕获阶段;
5、正向遍历并执行一遍所有回调函数,模拟事件冒泡阶段。
注意:如需注册捕获阶段的事件处理函数,则应为事件名添加 Capture。例如,处理捕获阶段的点击事件请使用 onClickCapture,而不是 onClick。
// 仅实现了stopPropagation,相同原理还可以实现preventDefault等
class SyntheticEvent {
constructor(e) {
this.nativeEvent = e;
}
stopPropagation() {
this._stopPropagation = true;
if (this.nativeEvent.stopPropagation) {
this.nativeEvent.stopPropagation();
}
}
}
export const addEvent = (container, type) => {
container.addEventListener(type, (e) => {
dispatchEvent(e, type.toUpperCase(), container);
});
};
const collectPaths = (type, begin) => {
const paths = [];
while (begin.tag !== 3) {
const { memoizedProps, tag } = begin;
if (tag === 5) {
const eventName = ("on" + type).toUpperCase();
if (memoizedProps && Object.keys(memoizedProps).includes(eventName)) {
const pathNode = {};
pathNode[type.toUpperCase()] = memoizedProps[eventName];
paths.push(pathNode);
}
}
begin = begin.return;
}
return paths;
};
const triggerEventFlow = (paths, type, se) => {
for (let i = paths.length; i--; ) {
const pathNode = paths[i];
const callback = pathNode[type];
if (callback) {
callback.call(null, se);
}
if (se._stopPropagation) {
break;
}
}
};
export const dispatchEvent = (e, type) => {
const se = new SyntheticEvent(e);
const ele = e.target;
let fiber;
for (const prop in ele) {
if (prop.toLowerCase().includes("fiber")) {
fiber = ele[prop];
}
}
const paths = collectPaths(type, fiber);
triggerEventFlow(paths, type + "CAPTURE", se);
if (!se._stopPropagation) {
triggerEventFlow(paths.reverse(), type, se);
}
};
HOC、renderProps、hooks 的区别
HOC(High Order Component)高阶组件是参数为组件,返回值为新函数的函数。
import React, { Component } from "react";
//HOC.js
const HOC = (WrappedComponent) =>
class WrapperComponent extends Component {
state = { number: 0 };
btnClick = () => {
this.setState({
number: this.state.number++,
});
};
render() {
const newProps = {
btnClick: this.btnClick,
number: this.state.number,
};
return (
<div>
rere HOC {" "}
<WrappedComponent {...this.props} {...this.newProps} />
{" "}
</div>
);
}
};
export default HOC;
// MyComponent.js
class MyComponent extends Component {
//...
}
export default HOC(MyComponent);
优点: 可以复用组件逻辑,不影响被包裹组件的内部逻辑
缺点:
hoc 会劫持被包裹组件的 props,如果存在同名的 props 就会存在覆盖问题
当有多个 props 时,无法确定 props 来自哪里,可读性差,易用性差
Render Props 从名知义,也是一种剥离重复使用的逻辑代码,提升组件复用性的解决方案。在被复用的组件中,通过一个名为“render”(属性名也可以不是 render,只要值是一个函数即可)的属性,该属性是一个函数,这个函数接受一个对象并返回一个子组件,会将这个函数参数中的对象作为 props 传入给新生成的组件。
ReactDOM.render(
<Router>
{" "}
<Route
path="/home"
render={(routeProps) => (
<div>Customize HZFE's {routeProps.location.pathname}</div>
)}
/>
{" "}
</Router>,
node
);
优缺点: 优点:复用代码逻辑,不用关心 props 从哪儿来,它只能从父组件传递过来,也不用担心 props 的命名问题,且是动态构建的
缺点:难以在 render 函数外使用数据源,也容易形成潜逃地狱
Hooks 是 react 提供的一组 api,开发者可以在不使用 class 的情况下,借助 hooks 在纯函数中使用状态和其他功能。
function Example() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p> {" "}
<button onClick={() => setCount(count + 1)}>Click me</button> {" "}
</div>
);
}
优点:hooks 可以清楚的看到组件接受的 props 以及传递的功能,可以对 props 重命名而不会有命名冲突,也不存在嵌套地狱。
类组件和函数组件的区别
类组件:
- 有生命周期
- 需要继承 class
- 有自己的状态 state
- 可以通过 this 获取实例
函数组件:
- 无生命周期(可以通过 hooks useEffect 实现)
- 无需继承 class
- 需要通过 hooks 拥有 state
- 没有实例
优缺点:
- 类组件有生命周期,当需要在特定生命周期处理逻辑时,类组件优
- 类组件有错误边界,函数组件没有,类组件优
- 函数组建更简洁已读,代码逻辑更清晰,颗粒度更轻,函数组件优
- 函数组件比较好拆分和复用,函数组件优
React 元素(Element)和组件(Component)的区别
组件 Component 是可复用的小的代码片段,它返回的是要在页面中渲染的 React 元素,开发者可以在 React 中定义函数和类组件。
对于ReactElement来讲, ReactComponent仅仅是诸多type类型中的一种.
对于开发者来讲, ReactComponent使用非常高频(在状态组件章节中详细解读), 在本节只是先证明它只是一种特殊的ReactElement.
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
元素 Element 是描述你在屏幕上想看到内容,它是不可变对象,它也会被 React.createElement 方法转化为描述 dom 的结构。也就是 createElement 的返回值。所有采用jsx语法书写的节点, 都会被编译器转换, 最终会以React.createElement(...)的方式, 创建出来一个与之对应的ReactElement对象.
ReactElement对象的数据结构如下:
export type ReactElement = {| // 用于辨别ReactElement对象 $$typeof: any,
// 内部属性 type: any, // 表明其种类 key: any, ref: any, props: any,
// ReactFiber 记录创建本对象的Fiber节点, 还未与Fiber树关联之前, 该属性为null _owner: any,
// __DEV__ dev环境下的一些额外信息, 如文件路径, 文件名, 行列信息等 _store: {validated: boolean, ...}, _self: React$Element<any>, _shadowChildren: any, _source: Source,|};
const element = <Welcome />;
可以简单的认为, 包括<App/>及其所有子节点都是ReactElement对象(在 render 之后才会生成子节点, 后文详细解读), 每个ReactElement对象的区别在于 type 不同.
在v17.0.2中, 定义了 20 种内部节点类型. 根据运行时环境不同, 分别采用 16 进制的字面量和Symbol进行表示.
如REACT_ELEMENT_TYPE,REACT_PORTAL_TYPE等等
什么是虚拟 dom,原理?优缺点?
虚拟 dom 本质上就是一个 js 对象,他用来抽象描述真实 dom 的层级结构和数据。这个数据结构对象一般包含 type、props、children 等字段,通过树状结构来描述真是 dom。虚拟 dom 的好处在于当更新发生时,较少了 dom 的直接操作,而是通过虚拟 dom 在数据层面的 diff 对比,计算出需要更新的最小操作步骤,实现 dom 的更新。此外,虚拟 dom 抽象了原本的渲染流程,也方便了跨平台的能力。
在不同的框架中,都存在讲代码转化为虚拟 dom 的函数,在 react 中是 react.createElement 函数,vue 中是 h 函数。
虚拟 Dom 和 Fiber 有什么区别?
Fiber 是 React 16 版本之后出现的架构模式,Fiber Node 是 Fiber 架构中的节点类型.FiberNode 有多层含义,但作为静态数据结构来看,每个 FiberNode 都对应一个 React 元素,用于保存 React 元素的类型和对应的 DOM 元素信息等。
而虚拟 Dom 来自 React15,主要是通过 js 对象来描述 ui。一般包含 type、props、children 等字段。
因此,从这个角度讲,Fiber 是虚拟 DOM 在 16 版本后的实现。但是,FiberNode 包含的信息处理描述 dom 之外,还包含了一些作为树结构中的其他连接属性,如 return 指向父节点,sibling 指向右边的兄弟节点,child 指向第一个子节点等。而作为工作单元,包含如 lane 优先级模型、flags 操作标识,alternate 缓存指针等等其他信息。
因此,Fiber 属于虚拟 DOM 在新的 fiber reconciler 架构下的升级。
Diff 原理,时间复杂度
react diff 算法将一颗树转换为另一棵树的最小操作为 O(n^3),其中 n 为元素数量。但是 react 通过 2 个操作,讲其降到了 O(n):
1、两个不同类型的元素会产生两颗不同的树
2、开发者可以使用 key 来标识哪些子元素在不同渲染中可能是不变的。
三大策略:
1、Tree diff (树比对)
- 比较新旧两棵树,找出哪些节点需要更新
- 发现组件则进入 Component diff
- 发现节点则进入 Element diff
2、Component diff (组件比对)
- 如果节点是组件,比对组件类型
- 类型不同直接替换(删除旧组件,创建新组件)
- 类型相同则只更新属性
- 然后深入组件进行 Tree diff(递归)
3、Element diff (元素比对)
- 如果节点是原生标签,则看标签名
- 标签名不同直接替换(删除旧元素,创建新元素)
- 标签名相同则只更新属性
- 然后深入标签做 Tree diff(递归) 当 react 比较两棵树时,react 会首先比较两个树的根节点,
1、当根节点为不同类型元素时,react 直接卸载原先的树并建立新的树
2、当两个元素相同时,react 会保留节点,仅对比和更新有更改的属性
3、当对比两个相同类型的组件时,组件实例会保持不变,仅通过更新属性来保持一致性
4、当递归对比子节点时,react 会同时遍历两个子元素的列表(以新的子元素为基准),有差异时产生 mutation
5、当子元素存在 key 时,react 使用 key 来匹配原来树和最新树上的子元素。
Fiber 原理
fiber 架构出现在 reactv16 版本之后,主要用来解决 cpu 和 i/o 瓶颈问题的。
具体来说:cpu 瓶颈是当项目变得庞大复杂之后,由于遇到组件繁多,计算量大或者是设备性能不足时,会出现页面卡顿掉帧的现象。I/O 瓶颈是当发送网络请求是,由于需要时间等待数据返回,而导致页面不能快速响应。
react 在页面渲染时会分为两个阶段:
reconciliation 调和阶段:这个阶段 react 会根据更新数据生成虚拟 DOM,然后通过 diff 算法对比快速找到需要更新的元素,然后放到更新队列里面去,得到新的更新队列。
commit 渲染阶段:react 会遍历更新队列,讲所有的更新一次性更新到 dom 上。
因此,在 React15 架构中主要分为两层:1、reconciler 协调器,找出变化的组件,2、renderer 渲染器,负责讲变化渲染到页面。Reconciler 会采用递归的方式创建虚拟 dom,也成为 Stack Reconciler,他在递归过程中是不能中断的,如果层级很深就会导致占用的时间很长,如果占用的事件超过了 1000ms/60=16.6ms,页面就会出现卡顿情况。
未解决这种问题,react16 将无法中断的更新重构为异步可中断的更新,也就是引入了 Fiber 架构,这种架构下的协调器被称为 Fiber Reconciler。
React16 架构变为了 3 层:1、Shceduler(调度器),负责调度任务的优先级,讲高优先级的任务优先进入 Reconciler 中。2、Reconciler(协调器):负责找出变化的组件,更新工作也从递归变成了可以中断的循环过程,也就是使用了 Fiber 架构。3、Render(渲染器):把变化的组件渲染到页面上。
针对优先级的判断,React16 中采用 expirationTimes 模型,但是只能区分是否>=expirationTimes 来决定是否更新,在 React17 中升级为 lanes 模型,可以选定一个更新区间,处理更细颗粒度的更新。
Fiber reconciler 和 Stack reconciler 区别
Stack Reconciler
基于栈的 Reconciler,浏览器引擎会从执行栈的顶端开始执行,执行完毕就弹出当前执行上下文,开始执行下一个函数,直到执行栈被清空才会停止。然后将执行权交还给浏览器。由于 React 将页面视图视作一个个函数执行的结果。每一个页面往往由多个视图组成,这就意味着多个函数的调用。
如果一个页面足够复杂,形成的函数调用栈就会很深。每一次更新,执行栈需要一次性执行完成,中途不能干其他的事儿,只能"一心一意"。结合前面提到的浏览器刷新率,JS 一直执行,浏览器得不到控制权,就不能及时开始下一帧的绘制。如果这个时间超过 16ms,当页面有动画效果需求时,动画因为浏览器不能及时绘制下一帧,这时动画就会出现卡顿。不仅如此,因为事件响应代码是在每一帧开始的时候执行,如果不能及时绘制下一帧,事件响应也会延迟。
Fiber Reconciler
在 React Fiber 中用链表遍历的方式替代了 React 16 之前的栈递归方案。在 React 16 中使用了大量的链表。
- 使用多向链表的形式替代了原来的树结构;(fibernode 中通过 return、child、silbing 字段指向对应节点)
- 副作用单链表
- 状态更新单链表
链表是一种简单高效的数据结构,它在当前节点中保存着指向下一个节点的指针;遍历的时候,通过操作指针找到下一个元素。链表相比顺序结构数据格式的好处就是:
- 操作更高效,比如顺序调整、删除,只需要改变节点的指针指向就好了。
- 不仅可以根据当前节点找到下一个节点,在多向链表中,还可以找到他的父节点或者兄弟节点。
但链表也不是完美的,缺点就是:
- 比顺序结构数据更占用空间,因为每个节点对象还保存有指向下一个对象的指针。
- 不能自由读取,必须找到他的上一个节点。
React 用空间换时间,更高效的操作可以方便根据优先级进行操作。同时可以根据当前节点找到其他节点,在下面提到的挂起和恢复过程中起到了关键作用。
Fiber 数据结构是怎样的?
基于时间分片的增量更新需要更多的上下文信息,之前的 vDOM tree 显然难以满足,所以扩展出了 fiber tree(即 Fiber 上下文的 vDOM tree),更新过程就是根据输入数据以及现有的 fiber tree 构造出新的 fiber tree(workInProgress tree)。
FiberNode 上的属性有很多,根据笔者的理解,以下这么几个属性是值得关注的:return、child、sibling(主要负责 fiber 链表的链接);stateNode;effectTag;expirationTime;alternate;nextEffect。各属性介绍参看下面的class FiberNode:
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode
) {
// Instance
this.tag = tag; // FiberNode类型,目前总有25种类型,常用的就是FunctionComponent 和 ClassComponent
this.key = key; //和组件Element中的key一致
this.elementType = null;
this.type = null; //Function|String|Symbol|Number|Object
this.stateNode = null; //FiberRoot|DomElement|ReactComponentInstance等绑定的其他对象
// Fiber
this.return = null; // FiberNode|null 父级FiberNode
this.child = null; // FiberNode|null 第一个子FiberNode
this.sibling = null; // FiberNode|null 相邻的下一个兄弟节点
this.index = 0; //当前父fiber中的位置
this.ref = null; //和组件Element中的ref一致
this.pendingProps = pendingProps; // Object 新的props
this.memoizedProps = null; // Object 处理后的新props
this.updateQueue = null; // UpdateQueue 即将要变更的状态
this.memoizedState = null; //Object 处理后的新state
this.dependencies = null;
this.mode = mode; // number
// 普通模式,同步渲染,React15-16的生产环境使用
// 并发模式,异步渲染,React17的生产环境使用
// 严格模式,用来检测是否存在废弃API,React16-17开发环境使用
// 性能测试模式,用来检测哪里存在性能问题,React16-17开发环境使用
// Effects
this.flags = NoFlags;
this.subtreeFlags = NoFlags;
this.deletions = null; // render阶段的diff过程检测到fiber的子节点如果有需要被删除的节点
this.lanes = NoLanes; //如果fiber.lanes不为空,则说明该fiber节点有更新
this.childLanes = NoLanes; //判断当前子树是否有更新的重要依据,若有更新,则继续向下构建,否则直接复用已有的fiber树
this.alternate = null; //FiberNode|null 候补节点,缓存之前的Fiber节点,与双缓存机制相关,后续讲解
}
Fiber 如何实现更新过程的可控?
更新过程的可控主要体现在下面几个方面:
- 任务拆分
- 任务挂起、恢复、终止
- 任务具备优先级
任务拆分:
在 React Fiber 机制中,它采用"化整为零"的思想,将调和阶段(Reconciler)递归遍历 VDOM 这个大任务分成若干小任务,每个任务只负责一个节点的处理。
任务挂起、恢复和终止:
workInProgress tree
workInProgress 代表当前正在执行更新的 Fiber 树。在 render 或者 setState 后,会构建一颗 Fiber 树,也就是 workInProgress tree,这棵树在构建每一个节点的时候会收集当前节点的副作用,整棵树构建完成后,会形成一条完整的副作用链。
currentFiber tree
currentFiber 表示 上次渲染构建的 Filber 树 。 在每一次更新完成后 workInProgress 会赋值给 currentFiber。在新一轮更新时 workInProgress tree 再重新构建,新 workInProgress 的节点通过 alternate 属性和 currentFiber 的节点建立联系。
在新 workInProgress tree 的创建过程中,会同 currentFiber 的对应节点进行 Diff 比较,收集副作用。同时也会复用和 currentFiber 对应的节点对象,减少新创建对象带来的开销。也就是说无论是创建还是更新、挂起、恢复以及终止操作都是发生在 workInProgress tree 创建过程中的。workInProgress tree 构建过程其实就是循环的执行任务和创建下一个任务。
挂起:
当第一个小任务完成后,先判断这一帧是否还有空闲时间,没有就挂起下一个任务的执行,记住当前挂起的节点,让出控制权给浏览器执行更高优先级的任务。
恢复:
在浏览器渲染完一帧后,判断当前帧是否有剩余时间,如果有就恢复执行之前挂起的任务。如果没有任务需要处理,代表调和阶段完成,可以开始进入渲染阶段。
- 如何判断一帧是否有空闲时间的呢?
使用前面提到的 RIC (RequestIdleCallback) 浏览器原生 API,React 源码中为了兼容低版本的浏览器,对该方法进行了 Polyfill。
- 恢复执行的时候又是如何知道下一个任务是什么呢?
答案是在前面提到的链表。在 React Fiber 中每个任务其实就是在处理一个 FiberNode 对象,然后又生成下一个任务需要处理的 FiberNode。
终止:
其实并不是每次更新都会走到提交阶段。当在调和过程中触发了新的更新,在执行下一个任务的时候,判断是否有优先级更高的执行任务,如果有就终止原来将要执行的任务,开始新的 workInProgressFiber 树构建过程,开始新的更新流程。这样可以避免重复更新操作。这也是在 React 16 以后生命周期函数 componentWillMount 有可能会执行多次的原因。
任务优先级:
React Fiber 除了通过挂起,恢复和终止来控制更新外,还给每个任务分配了优先级。具体点就是在创建或者更新 FiberNode 的时候,通过算法给每个任务分配一个到期时间(expirationTime)。在每个任务执行的时候除了判断剩余时间,如果当前处理节点已经过期,那么无论现在是否有空闲时间都必须执行该任务。过期时间的大小还代表着任务的优先级。
任务在执行过程中顺便收集了每个 FiberNode 的副作用,将有副作用的节点通过 firstEffect、lastEffect、nextEffect 形成一条副作用单链表 A1(TEXT)-B1(TEXT)-C1(TEXT)-C1-C2(TEXT)-C2-B1-B2(TEXT)-B2-A。
其实最终都是为了收集到这条副作用链表,有了它,在接下来的渲染阶段就通过遍历副作用链完成 DOM 更新。这里需要注意,更新真实 DOM 的这个动作是一气呵成的,不能中断,不然会造成视觉上的不连贯(commit)。
<div id="A1">
A1
<div id="B1">
B1
<div id="C1">C1</div>
<div id="C2">C2</div>
</div>
<div id="B2">B2</div>
</div>

什么是 concurrent mode(并发模式)?
Concurrent Mode 指的就是 React 利用上面 Fiber 带来的新特性的开启的新模式 (mode)。react17 开始支持 concurrent mode,这种模式的根本目的是为了让应用保持 cpu 和 io 的快速响应,它是一组新功能,包括 Fiber、Scheduler、Lane,可以根据用户硬件性能和网络状况调整应用的响应速度,核心就是为了实现异步可中断的更新。concurrent mode 也是未来 react 主要迭代的方向。
concurrent mode 的目的是实现一套异步可中断/恢复的更新机制,其中主要包含两部分:
1、fiber reconciler 架构
2、基于协程架构的启发式更新算法(React16 使用 expirationTime 区分更新优先级,React17 指定了一个连续的优先级区间,这种优先级区间程为 lanes 模型)
什么是 React 启发式更新算法?
https://zhuanlan.zhihu.com/p/182411298
为什么会出现启发式更新算法
框架的运行性能是框架设计者在设计框架时需要重点关注的点。
Vue使用模版语法,可以在编译时对确定的模版作出优化。
而React纯JS写法太过灵活,使他在编译时优化方面先天不足。
所以,React的优化主要在运行时。
React15 的痛点
在运行时优化方面,React一直在努力。
比如,React15实现了batchedUpdates(批量更新)。
即同一事件回调函数上下文中的多次setState只会触发一次更新。
但是,如果单次更新就很耗时,页面还是会卡顿(这在一个维护时间很长的大应用中是很常见的)。
这是因为React15的更新流程是同步执行的,一旦开始更新直到页面渲染前都不能中断。
为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。
重构的目标是实现Concurrent Mode(并发模式)。
Concurrent Mode
Concurrent Mode的目的是实现一套可中断/恢复的更新机制。
其由两部分组成:
- 一套
协程架构 - 基于
协程架构的启发式更新算法
其中,协程架构就是React16中实现的Fiber Reconciler。
我们可以将Fiber Reconciler理解为React自己实现的Generator。
Fiber Reconciler从理念到源码的详细介绍见这里
协程架构使更新可以在需要的时机被中断,这样浏览器就有时间完成样式布局与样式绘制,减少卡顿(掉帧)的出现。
当浏览器进入下一次事件循环,协程架构可以恢复中断或者抛弃之前的更新,重新开始新的更新流程。
启发式更新算法就是控制协程架构工作方式的算法。
React16 的启发式更新算法
启发式更新算法的启发式指什么呢?
启发式指不通过显式的指派,而是通过优先级调度更新。
其中优先级来源于人机交互的研究成果。
比如:
人机交互的研究成果表明:
- 当用户在输入框输入内容时,希望输入的内容能实时响应在输入框
- 当异步请求数据后,即使等待一会儿再显示内容,用户也是可以接受的
基于此,在React16中
输入框输入内容触发的`更新`优先级 > 请求数据返回后触发`更新`优先级
算法实现
在React16、17中,在组件内执行this.setState后会在该组件对应的fiber节点内产生一种链表数据结构update。
其中,update.expirationTimes为类似时间戳的字段,表示优先级。
expirationTimes从字面意义理解为过期时间。
该值离当前时间越接近,该update 优先级越高。
当update.expirationTimes超过当前时间,则代表该update过期,优先级变为最高(即同步)。
一棵fiber树的多个fiber节点可能存在多个update。
每次Fiber Reconciler调度更新时,会在所有fiber节点的所有update.expirationTimes中选择一个expirationTimes(一般选择最大的),作为本次更新的优先级。
并从根fiber节点开始向下构建新的fiber树。
构建过程中如果某个fiber节点包含update,且
update.expirationTimes >= expirationTimes
则该update对应的state变化会体现在本次更新中。
可以理解为:每次更新,都会选定一个优先级(expirationTimes),最终页面会渲染为该优先级对应update的快照。
举个例子,我们有如图所示fiber树,当前还没有更新产生,所以没有构建中的fiber树。
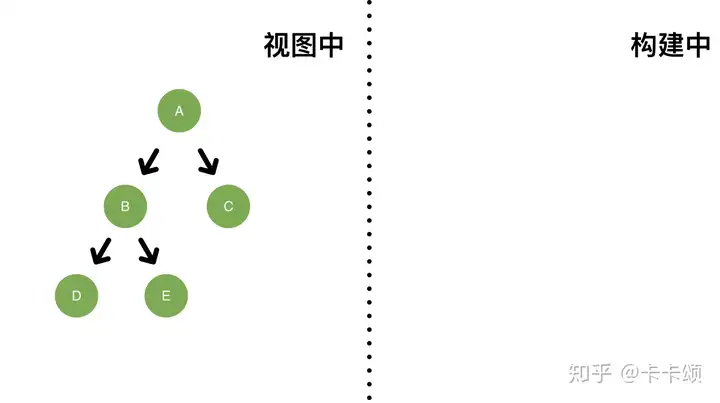
当在C创建一个低优先级update,调度更新,本次更新选择的优先级为低优先级。
开始构建新的fiber树(图右侧)。
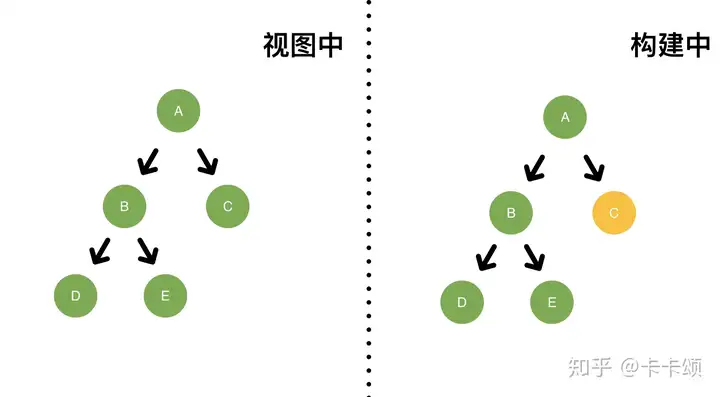
此时,我们在D创建一个高优先级update。
这会中断进行中的低优先级更新,重新开始以高优先级生成一棵fiber树。
由于之前的更新被中断,还没有任何渲染操作,此时视图中(左图)还没有任何变化。
本次更新选定的优先级为高优先级,C的update(低优先级)会被跳过。
更新完成后新的fiber树会被渲染到视图中。
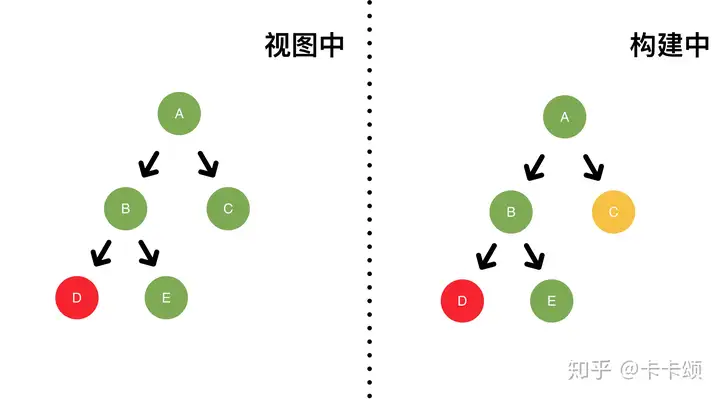
由于C被跳过,所以不会在视图(左图)中体现。
接下来我们在E触发一次高优先级update。
C虽然包含低优先级update,但随着时间的推移,他的expirationTimes已经过期,变为高优先级。
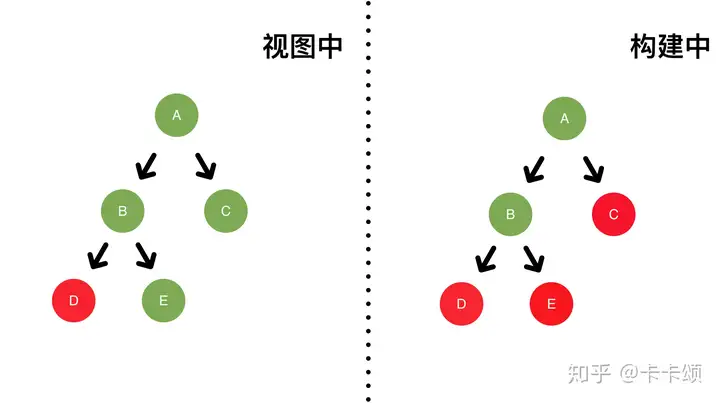
所以本次更新会有C E两个fiber节点产生变化。
最终完成更新后,视图如下:
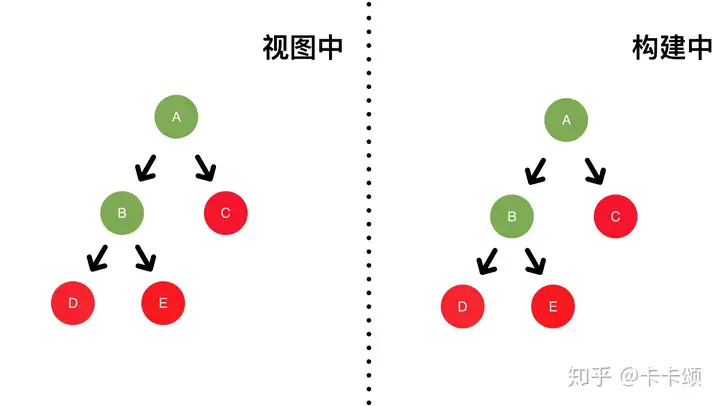
关于更新
优先级的详细解释参考这里
算法缺陷
如果只考虑中断/继续这样的CPU操作,以expirationTimes大小作为衡量优先级依据的模型可以很好工作。
但是expirationTimes模型不能满足IO操作(Suspense)。
在该模型下,高优先级IO任务(Suspense)会中断低优先级CPU任务。
还记得么,每次更新,都是以某一优先级作为整棵树的优先级更新标准,而不仅仅是某一组件,即使更新的源头(update)确实是某个组件产生的。
expirationTimes模型只能区分是否>=expirationTimes这种情况。
为了拓展Concurrent Mode能力边界,需要一种更细粒度的启发式优先级更新算法。
React17 启发式更新算法
最理想的模型是:可以指定任意几个优先级,更新会以这些优先级对应update生成页面快照。
但是现有架构下,该方案实现上有瓶颈。
妥协之下,React17的解决方案是:指定一个连续的优先级区间,每次更新都会以区间内包含的优先级生成对应页面快照。
这种优先级区间模型被称为lanes(车道模型)。
具体做法是:使用一个 31 位的二进制代表 31 种可能性。
- 其中每个
bit被称为一个lane(车道),代表优先级 - 某几个
lane组成的二进制数被称为一个lanes,代表一批优先级
可以从源码中看到,从蓝线一路划下去,每个bit都对应一个lane或lanes。
当update产生,会根据React16同样的启发式方式,获得如下优先级的一种:
export const SyncLanePriority: LanePriority = 17;
export const SyncBatchedLanePriority: LanePriority = 16;
export const InputDiscreteLanePriority: LanePriority = 14;
export const InputContinuousLanePriority: LanePriority = 12;
export const DefaultLanePriority: LanePriority = 10;
export const TransitionShortLanePriority: LanePriority = 8;
export const TransitionLongLanePriority: LanePriority = 6;
其中值越高,优先级越大。
比如:
点击事件回调中触发this.setState产生的update会获得InputDiscreteLanePriority。- 同步的
update会获得SyncLanePriority。
接下来,update会以priority为线索寻找没被占用的lane。
如果当前fiber树已经存在更新且更新的lanes包含了该lane,则update需要寻找其他lane。
比如,InputDiscreteLanePriority对应的lanes为InputDiscreteLanes。
// 第4、5位为1
const InputDiscreteLanes: Lanes = 0b0000000000000000000000000011000;
该lanes包含第 4、5 位 2 个bit位。
如果其中
// 第五位为1
0b0000000000000000000000000010000
第五位的lane已经被占用,则该update可以尝试占有后一个,即
// 第四位为1
0b0000000000000000000000000001000
如果InputDiscreteLanes的两个lane都被占用,则该update的优先级会下降到InputContinuousLanePriority并继续寻找空余的lane。
这个过程就像:购物中心每一层(不同优先级)都有一个露天停车场(lanes),停车场有多个车位(lane)。
我们先开车到顶楼找车位(lane),如果没有车位就下一楼继续找。
直到找到空余车位。
由于lanes可以包含多个lane,可以很方便的区分IO操作(Suspense)与CPU操作。
当构建fiber树进入构建Suspense子树时,会将Suspense的lane插入本次更新选定的lanes中。
当构建离开Suspense子树时,会将Suspense lane从本次更新的lanes中移除。
总结
React16的expirationTimes模型只能区分是否>=expirationTimes决定节点是否更新。
React17的lanes模型可以选定一个更新区间,并且动态的向区间中增减优先级,可以处理更细粒度的更新。
双缓存原理
当我们用canvas绘制动画,每一帧绘制前都会调用ctx.clearRect清除上一帧的画面。
如果当前帧画面计算量比较大,导致清除上一帧画面到绘制当前帧画面之间有较长间隙,就会出现白屏。
为了解决这个问题,我们可以在内存中绘制当前帧动画,绘制完毕后直接用当前帧替换上一帧画面,由于省去了两帧替换间的计算时间,不会出现从白屏到出现画面的闪烁情况。
这种在内存中构建并直接替换的技术叫做双缓存 (opens new window)。
React使用“双缓存”来完成Fiber树的构建与替换——对应着DOM树的创建与更新
在React中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。
current Fiber树中的Fiber节点被称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,他们通过alternate属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;
React应用的根节点通过使current指针在不同Fiber树的rootFiber间切换来完成current Fiber树指向的切换。
即当workInProgress Fiber树构建完成交给Renderer渲染在页面上后,应用根节点的current指针指向workInProgress Fiber树,此时workInProgress Fiber树就变为current Fiber树。
每次状态更新都会产生新的workInProgress Fiber树,通过current与workInProgress的替换,完成DOM更新。
图来表述double buffering的概念如下:
- 构造过程中,
fiberRoot.current指向当前界面对应的fiber树.

- 构造完成并渲染, 切换
fiberRoot.current指针, 使其继续指向当前界面对应的fiber树(原来代表界面的 fiber 树, 变成了内存中).

class component 和 pure component 区别
区别:
PureComponent 通过 prop 和 state 的浅比较来实现 shouldComponentUpdate,当 prop 或 state 的值或者引用地址发生改变时,组件就会发生更新。也就是说如果是引用类型,只要地址不变就不会更新,如果是基本类型,变化了是会更新的。
而 Component 只要 state 发生改变, 不论值是否与之前的相等,都会触发更新。
react 使用哪种方式遍历树
DFS 深度遍历
React.memo,useMemo 和 useCallback 的区别,它们的实现原理是什么?
momo 是一种 react 的缓存技术,useMemo 把创建函数和依赖数组作为参数传入,当依赖数组中的依赖性发生改变时才会重新计算 memoized值。通常用来避免每次渲染都进行高开销的计算。
注意:useMemo 不只是缓存了函数的返回值,同时保证了返回值的引用地址不变。这个非常重要。
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
useCallback 返回的是一个 memorized 函数。它把内联回调函数和依赖数组作为参数,然后返回这个回调函数的缓存版本,这个回调函数仅当依赖项发生变化时才更新。
const memoizedCallback = useCallback(() => {
doSomething(a, b);
}, [a, b]);
useCallback 与 useMemo 有些许不同,缓存的是函数本身以及它的引用地址,而不是返回值。 当然了,理解了这一点,我们可以很轻松的用 useMemo 模拟一个 useCallback 出来。
useCallback(callBackFn, deps)
useMemo(() => callBackFn, deps)
React.memo 是 React 自带的高阶组件,能够把组件的渲染结果缓存,并有效复用,就能够减少主线程的阻塞。 React.memo 的思想是,当 props 没有改变时,组件就不需要重新渲染。
const MemoComponent = React.memo(Component)
const MemoComponent = React.memo(Component, areEqual)
与 Hooks 的依赖数组相同,检查 props 是否相同,是通过浅比较实现的。除了默认情况,如果有复杂的对象类型,也可以自己写一个比较函数 areEqual,需要作为第二个参数传入。
看到这里,结合浅比较的知识,不难发现如果 props 中存在回调函数或者多层嵌套的复杂对象,那么只用 React.memo 是无法达到目的的,需要自己写比较函数,或者搭配 useCallback 使用。
最后:
useCallback和useMemo是一样的东西,只是入参有所不同。
useCallback缓存的是回调函数,如果依赖项没有更新,就会使用缓存的回调函数;
useMemo缓存的是回调函数的return,如果依赖项没有更新,就会使用缓存的return;
官网有这样一段描述useCallback(fn, deps) 相当于 useMemo(() => fn, deps)。
ReactElement, Fiber, DOM 三者的关系
- ReactElement 对象(type 定义在shared 包中)
- 所有采用
jsx语法书写的节点, 都会被编译器转换, 最终会以React.createElement(...)的方式, 创建出来一个与之对应的ReactElement对象
- 所有采用
- fiber 对象(type 类型的定义在ReactInternalTypes.js中)
fiber对象是通过ReactElement对象进行创建的, 多个fiber对象构成了一棵fiber树,fiber树是构造DOM树的数据模型,fiber树的任何改动, 最后都体现到DOM树.
- DOM 对象: 文档对象模型
DOM将文档解析为一个由节点和对象(包含属性和方法的对象)组成的结构集合, 也就是常说的DOM树.JavaScript可以访问和操作存储在 DOM 中的内容, 也就是操作DOM对象, 进而触发 UI 渲染.
它们之间的关系反映了我们书写的 JSX 代码到 DOM 节点的转换过程:

注意:
- 开发人员能够控制的是
JSX, 也就是ReactElement对象. fiber树是通过ReactElement生成的, 如果脱离了ReactElement,fiber树也无从谈起. 所以是ReactElement树(不是严格的树结构, 为了方便也称为树)驱动fiber树.fiber树是DOM树的数据模型,fiber树驱动DOM树
开发人员通过编程只能控制ReactElement树的结构, ReactElement树驱动fiber树, fiber树再驱动DOM树, 最后展现到页面上. 所以fiber树的构造过程, 实际上就是ReactElement对象到fiber对象的转换过程.
react 怎样知道下一次该从哪个节点开始执行?
如果在 reconciler 中的 workLoopConcurrent 被中断了,则会返回一个 performConcurrentWorkOnRoot 方法,在 scheduler 中的 workLoop 发现 continuationCallback 返回的值为一个方法,则会存下当前中断的回调,且不让当前执行的任务出栈,也就意味着当前的 task 没有执行完,下一次循环时可以继续执行,而执行的方法便是 continuationCallback 。
以此,实现了任务的恢复。
https://blog.csdn.net/xiaofeng123aazz/article/details/127243961
React dom 绑定事件和原生事件有什么区别
从架构上来讲, SyntheticEvent打通了从外部原生事件到内部fiber树的交互渠道, 使得react能够感知到浏览器提供的原生事件, 进而做出不同的响应, 修改fiber树, 变更视图等.
从实现上讲, 主要分为 3 步:
- 监听原生事件: 对齐
DOM元素和fiber元素 - 收集
listeners: 遍历fiber树, 收集所有监听本事件的listener函数. - 派发合成事件: 构造合成事件, 遍历
listeners进行派发.
为什么需要 hooks
更容易复用代码
清爽的代码风格+代码量更少
代码可读性更强
组件树层级变浅
不用再去考虑 this 的指向问题
手动实现一个 hooks
import ReactDOM from "react-dom";
let workInProgressHook;
let isMount = true;
const fiber = {
momoizedState: null,
stateNode: App,
};
const Dispatcher = (() => {
function mountWorkInProgressHook() {
//mount时调用
const hook = {
//构建hook
queue: {
//更新队列
pending: null, //未执行的update队列
},
memoizedState: null, //当前state
next: null, //下一个hook
};
if (!fiber.memoizedState) {
fiber.memoizedState = hook; //第一个hook的话直接赋值给fiber.memoizedState
} else {
workInProgressHook.next = hook; //不是第一个的话就加在上一个hook的后面,形成链表
}
workInProgressHook = hook; //记录当前工作的hook
return workInProgressHook;
}
function updateWorkInProgressHook() {
//update时调用
let curHook = workInProgressHook;
workInProgressHook = workInProgressHook.next; //下一个hook
return curHook;
}
function useState(initialState) {
let hook;
if (isMount) {
hook = mountWorkInProgressHook();
hook.memoizedState = initialState;
} else {
hook = updateWorkInProgressHook();
}
let baseState = hook.memoizedState;
if (hook.queue.pending) {
let firstUpdate = hook.queue.pending.next;
do {
const action = firstUpdate.action;
baseState = action(baseState);
firstUpdate = firstUpdate.next;
} while (firstUpdate !== hook.queue.pending);
hook.queue.pending = null;
}
hook.memoizedState = baseState;
return [baseState, dispatchAction.bind(null, hook.queue)];
}
return {
useState,
};
})();
function dispatchAction(queue, action) {
//触发更新
const update = {
//构建update
action,
next: null,
};
if (queue.pending === null) {
update.next = update; //update的环状链表
} else {
update.next = queue.pending.next; //新的update的next指向前一个update
queue.pending.next = update; //前一个update的next指向新的update
}
queue.pending = update; //更新queue.pending
isMount = false; //标志mount结束
workInProgressHook = fiber.memoizedState; //更新workInProgressHook
schedule(); //调度更新
}
function App() {
let [count, setCount] = Dispatcher.useState(1);
let [age, setAge] = Dispatcher.useState(10);
return (
<>
<p>Clicked {count} times</p>
<button onClick={() => setCount(() => count + 1)}> Add count</button>
<p>Age is {age}</p>
<button onClick={() => setAge(() => age + 1)}> Add age</button>
</>
);
}
function schedule() {
ReactDOM.render(<App />, document.querySelector("#root"));
}
schedule();
创建 ref 的方法
函数组件中: useRef
类组件传使用 forwardRef 递给子组建
类组件:React.createRef
回调函数 ref:
class CustomTextInput extends React.Component {
constructor(props) {
super(props);
this.textInput = null;
this.setTextInputRef = element => { this.textInput = element; };
this.focusTextInput = () => { // 使用原生 DOM API 使 text 输入框获得焦点 if (this.textInput) this.textInput.focus(); }; }
componentDidMount() {
// 组件挂载后,让文本框自动获得焦点
this.focusTextInput(); }
render() {
// 使用 `ref` 的回调函数将 text 输入框 DOM 节点的引用存储到 React
// 实例上(比如 this.textInput)
return (
<div>
<input
type="text"
ref={this.setTextInputRef} />
<input
type="button"
value="Focus the text input"
onClick={this.focusTextInput} />
</div>
);
}
}
useRef、ref、forwardRef 区别
useRef 是在函数组件中创建 ref 的 hook
forwardRef 是 ref 转发,通常是在父组件中创建 ref,然后用 forwardRef 包裹子组件,然后子组件才能获得传递过来的 ref。
ref 是元素上的属性,React 提供的这个 ref 属性,表示为对组件真正实例的引用。ref可以挂载到组件上也可以是 dom 元素上;
useEffect 第二个参数,传空数组和依赖数组的区别?如果 return 函数,传空数组的话是在什么时候执行? 传依赖数组的时候是在什么时候执行?
useEffect 第二个参数:
1、不传时,mount 和 update 时都会执行,也就是每次 render 都执行
2、传空数组,mount 后执行一次
3、传依赖数组,依赖数组中的值发生变化时触发回调函数,依赖项时浅对比
传空数组时,return 函数在组件卸载的时候执行。
传依赖数组时,会在先一次回调函数执行前触发。
useState 和 useRef 区别
1、与 state 不同,存储在 ref 的数据或值保持不变,即使在组件重新渲染之后也是如此。因此,ref 不会影响组件渲染,但 state 会影响。
2、useState 返回 2 个属性或一个数组。一个是值或状态,另一个是更新状态的函数。相比之下, useRef 只返回一个值,即实际存储的数据。
3、当 ref 发生变化时,无需刷新或重新渲染即可更新。但是在 useState 中,组件必须再次渲染以更新状态或其值。
hooks 如何清除副作用
在 effect 回调函数中 return 一个清除函数
context 的实现原理是什么?如何做依赖收集?
Context的实现思路还是比较清晰, 总体分为 2 步.
- 在消费状态时,
ContextConsumer节点调用readContext(MyContext)获取最新状态. - 在更新状态时, 由
ContextProvider节点负责查找所有ContextConsumer节点, 并设置消费节点的父路径上所有节点的fiber.childLanes, 保证消费节点可以得到更新.
React 的生命周期(React15、React16)
React15

React16

react 一些生命周期被废弃的原理,componentWillMount、componentWillMount、componentWillUpdate 为什么标记 UNSAFE
答:新的 Fiber 架构能在 scheduler 的调度下实现暂停继续,排列优先级,Lane 模型能使 Fiber 节点具有优先级,在高优先级的任务打断低优先级的任务时,低优先级的更新可能会被跳过,所有以上生命周期可能会被执行多次,和之前版本的行为不一致。
react 元素$$typeof 属性什么
答:用来表示元素的类型,是一个 symbol 类型
useLayout/componentDidMount 和 useEffect 的区别是什么
class App extends React.Component {
componentDidMount() {
console.log("mount");
}
}
useEffect(() => {
console.log("useEffect");
}, []);
他们在 commit 阶段不同时机执行,useEffect 在 commit 阶段结尾异步调用,useLayout/componentDidMount 同步调用

React 内部的优先级管理如何划分
React内部对于优先级的管理, 根据功能的不同分为LanePriority,SchedulerPriority,ReactPriorityLevel3 种类型. 本文基于react@17.0.2, 梳理源码中的优先级管理体系.
LanePriority
LanePriority: 属于react-reconciler包, 定义于ReactFiberLane.js(见源码).
export const SyncLanePriority: LanePriority = 15;
export const SyncBatchedLanePriority: LanePriority = 14;
const InputDiscreteHydrationLanePriority: LanePriority = 13;
export const InputDiscreteLanePriority: LanePriority = 12;
const InputContinuousHydrationLanePriority: LanePriority = 11;
export const InputContinuousLanePriority: LanePriority = 10;
const DefaultHydrationLanePriority: LanePriority = 9;
export const DefaultLanePriority: LanePriority = 8;
const TransitionHydrationPriority: LanePriority = 7;
export const TransitionPriority: LanePriority = 6;
const RetryLanePriority: LanePriority = 5;
const SelectiveHydrationLanePriority: LanePriority = 4;
const IdleHydrationLanePriority: LanePriority = 3;
const IdleLanePriority: LanePriority = 2;
const OffscreenLanePriority: LanePriority = 1;
export const NoLanePriority: LanePriority = 0;
// ....
export const NoLanes: Lanes = /* */ 0b0000000000000000000000000000000;
export const NoLane: Lane = /* */ 0b0000000000000000000000000000000;
export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
export const SyncBatchedLane: Lane = /* */ 0b0000000000000000000000000000010;
//Discrete 离散的
export const InputDiscreteHydrationLane: Lane = /* */ 0b0000000000000000000000000000100;
const InputDiscreteLanes: Lanes = /* */ 0b0000000000000000000000000011000;
//Continuous 不断的
const InputContinuousHydrationLane: Lane = /* */ 0b0000000000000000000000000100000;
const InputContinuousLanes: Lanes = /* */ 0b0000000000000000000000011000000;
export const DefaultHydrationLane: Lane = /* */ 0b0000000000000000000000100000000;
export const DefaultLanes: Lanes = /* */ 0b0000000000000000000111000000000;
//Transition 过渡
const TransitionHydrationLane: Lane = /* */ 0b0000000000000000001000000000000;
const TransitionLanes: Lanes = /* */ 0b0000000001111111110000000000000;
const RetryLanes: Lanes = /* */ 0b0000011110000000000000000000000;
export const SomeRetryLane: Lanes = /* */ 0b0000010000000000000000000000000;
export const SelectiveHydrationLane: Lane = /* */ 0b0000100000000000000000000000000;
const NonIdleLanes = /* */ 0b0000111111111111111111111111111;
export const IdleHydrationLane: Lane = /* */ 0b0001000000000000000000000000000;
const IdleLanes: Lanes = /* */ 0b0110000000000000000000000000000;
export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;
与fiber构造过程相关的优先级(如fiber.updateQueue,fiber.lanes)都使用LanePriority.
SchedulerPriority
SchedulerPriority, 属于scheduler包, 定义于SchedulerPriorities.js中(见源码).
export const NoPriority = 0;
export const ImmediatePriority = 1;
export const UserBlockingPriority = 2;
export const NormalPriority = 3;
export const LowPriority = 4;
export const IdlePriority = 5;
与scheduler调度中心相关的优先级使用SchedulerPriority.
ReactPriorityLevel
reactPriorityLevel, 属于react-reconciler包, 定义于SchedulerWithReactIntegration.js中(见源码).
export const ImmediatePriority: ReactPriorityLevel = 99;
export const UserBlockingPriority: ReactPriorityLevel = 98;
export const NormalPriority: ReactPriorityLevel = 97;
export const LowPriority: ReactPriorityLevel = 96;
export const IdlePriority: ReactPriorityLevel = 95;
// NoPriority is the absence of priority. Also React-only.
export const NoPriority: ReactPriorityLevel = 90;
LanePriority与SchedulerPriority通过ReactPriorityLevel进行转换
转换关系
为了能协同调度中心(scheduler包)和 fiber 树构造(react-reconciler包)中对优先级的使用, 则需要转换SchedulerPriority和LanePriority, 转换的桥梁正是ReactPriorityLevel.
在SchedulerWithReactIntegration.js 中, 可以互转SchedulerPriority 和 ReactPriorityLevel:
export function getCurrentPriorityLevel(): ReactPriorityLevel {
switch (Scheduler_getCurrentPriorityLevel()) {
case Scheduler_ImmediatePriority:
return ImmediatePriority;
case Scheduler_UserBlockingPriority:
return UserBlockingPriority;
case Scheduler_NormalPriority:
return NormalPriority;
case Scheduler_LowPriority:
return LowPriority;
case Scheduler_IdlePriority:
return IdlePriority;
default:
invariant(false, "Unknown priority level.");
}
}
function reactPriorityToSchedulerPriority(reactPriorityLevel) {
switch (reactPriorityLevel) {
case ImmediatePriority:
return Scheduler_ImmediatePriority;
case UserBlockingPriority:
return Scheduler_UserBlockingPriority;
case NormalPriority:
return Scheduler_NormalPriority;
case LowPriority:
return Scheduler_LowPriority;
case IdlePriority:
return Scheduler_IdlePriority;
default:
invariant(false, "Unknown priority level.");
}
}
在ReactFiberLane.js中, 可以互转LanePriority 和 ReactPriorityLevel:
export function schedulerPriorityToLanePriority(
schedulerPriorityLevel: ReactPriorityLevel
): LanePriority {
switch (schedulerPriorityLevel) {
case ImmediateSchedulerPriority:
return SyncLanePriority;
case UserBlockingSchedulerPriority:
return InputContinuousLanePriority;
case NormalSchedulerPriority:
case LowSchedulerPriority:
// TODO: Handle LowSchedulerPriority, somehow. Maybe the same lane as hydration.
return DefaultLanePriority;
case IdleSchedulerPriority:
return IdleLanePriority;
default:
return NoLanePriority;
}
}
export function lanePriorityToSchedulerPriority(
lanePriority: LanePriority
): ReactPriorityLevel {
switch (lanePriority) {
case SyncLanePriority:
case SyncBatchedLanePriority:
return ImmediateSchedulerPriority;
case InputDiscreteHydrationLanePriority:
case InputDiscreteLanePriority:
case InputContinuousHydrationLanePriority:
case InputContinuousLanePriority:
return UserBlockingSchedulerPriority;
case DefaultHydrationLanePriority:
case DefaultLanePriority:
case TransitionHydrationPriority:
case TransitionPriority:
case SelectiveHydrationLanePriority:
case RetryLanePriority:
return NormalSchedulerPriority;
case IdleHydrationLanePriority:
case IdleLanePriority:
case OffscreenLanePriority:
return IdleSchedulerPriority;
case NoLanePriority:
return NoSchedulerPriority;
default:
invariant(
false,
"Invalid update priority: %s. This is a bug in React.",
lanePriority
);
}
}
React bailout 策略和 eagerState 策略是什么?
都是用来性能优化的。
eagerState 策略:如果某个状态更新前后没什么变化,则可以跳过后续的更新流程。比如onCLick={() => setNum(1)}点击多次,num 永远是 1,没有变化,所以后续流程可以跳过。
bail out英文短语翻译为解救, 纾困, 在源码中,bailout用于判断子树节点是否完全复用, 如果可以复用, 则会略过 fiber 树构造.
与初次创建不同, 在对比更新过程中, 如果是老节点, 那么current !== null, 需要进行对比, 然后决定是否复用老节点及其子树(即bailout逻辑).
bailout 就是更新阶段判断子节点能不能复用。
React 怎么解决饥饿问题
随之时间的推移,低优先级的任务被插队,最后也会变成高优先级的任务
jsx 和 Fiber 有什么关系
mount 时通过 jsx 对象(调用 createElement 的结果)调用 createFiberFromElement 生成 Fiber
update 时通过 reconcileChildFibers 或 reconcileChildrenArray 对比新 jsx 和老的 Fiber(current Fiber)生成新的 wip Fiber 树
react17 之前 jsx 文件为什么要声明 import React from 'react',之后为什么不需要了
jsx 经过编译之后编程 React.createElement,不引入 React 就会报错,react17 改变了编译方式,变成了 jsx.createElement
function App() {
return <h1>Hello World</h1>;
}
//转换后
import { jsx as _jsx } from "react/jsx-runtime";
function App() {
return _jsx("h1", { children: "Hello world" });
}
Fiber 是什么,它为什么能提高性能
Fiber 是一个 js 对象,能承载节点信息、优先级、updateQueue,同时它还是一个工作单元。
- Fiber 双缓存可以在构建好 wip Fiber 树之后切换成 current Fiber,内存中直接一次性切换,提高了性能
- Fiber 的存在使异步可中断的更新成为了可能,作为工作单元,可以在时间片内执行工作,没时间了交还执行权给浏览器,下次时间片继续执行之前暂停之后返回的 Fiber
- Fiber 可以在 reconcile 的时候进行相应的 diff 更新,让最后的更新应用在真实节点上
为什么 hooks 不能写在条件判断中
答:hook 会按顺序存储在链表中,如果写在条件判断中,就没法保持链表的顺序
react18 变化
1、renderAPI
2、setState 批处理
3、退出批处理 flushSync
4、移除卸载组件时,报错“无法对未挂载组件执行状态更新,疑似有内存泄露”。
5、不再检查组件返回 undefined 导致的崩溃
6、suspense 不在需要通过 fallback 来捕获,而是寻找最近的 suspense,如果没有 fallback 就显示 null
7、新的 api:useId、useSyncExternalStore、useInsertionEffect、useTransition、useDeferredValue 等
react-router 实现原理
源码:https://github.com/remix-run/react-router/
history:https://github.com/remix-run/history/
通过 history 库创建,如:createBrowserHistory、 createHashHistory、createMemoryHistory 等
const BeforeUnloadEventType = "beforeunload";
const HashChangeEventType = "hashchange";
const PopStateEventType = "popstate";
borewser:监听 popstate 函数
hash 模式:监听 hashchange 函数
数据传递通过 Context,Router 使用 Context.Provider、Route 使用 Context.Consumer
v6 文档:https://reactrouter.com/en/main
redux 原理?Redux 是如何派发数据的? connect 原理?
1、用户操作触发一个 action,会通过 dispatch(action)的方式提交给 redux
2、redux 接受到 aciton 后,会在 dispacth 方法中调用 reducer(state,action)
3、reducer 是在 createStore(reducer)时定义的,reducer 负责根据不同的 action.type 来返回新的 state
4、dispatch 接收到新的 state 之后,会把所有 subscribe 的回调队列执行一遍,也就是发布订阅模式
5、此时,store 中的 state 也就是最新的 state 了。
其中应用到了发布订阅原理。
connect:
import React, { Component } from "react";
import PropTypes from "prop-types";
import bindActionCreators from "../redux/bindActionCreators";
export default function connect(mapStateToProps, mapDispatchToProps) {
return function (Component) {
class Connect extends React.Component {
componentDidMount() {
// 从context获取store并订阅更新
this.context.store.subscribe(this.handleStoreChange.bind(this));
}
handleStoreChange() {
// 触发的方法有多种,这里为了简洁起见,直接forceUpdate强制更新,读者也可以通过setState来触发子组件更新
this.forceUpdate();
}
render() {
const dispathProps =
typeof mapDispatchToProps &&
bindActionCreators(mapDispatchToProps, this.context.store.dispatch);
return (
<Component
// 传入该组件的props,需要由connect这个高阶组件原样传回原组件
{...this.props}
// 根据mapStateToProps把state挂到this.props上
{...mapStateToProps(this.context.store.getState())}
// 根据mapDispatchToProps把dispatch(action)挂到this.props上
{...dispathProps}
/>
);
}
}
// 接收context的固定写法
Connect.contextTypes = {
store: PropTypes.object,
};
return Connect;
};
}
使用:
connect(mapStateToProps, mapDispatchToProps)(App)
mobx 原理?和 redux 区别
mobx 通过 object.definproperty 讲对象变为响应式的对象,并在 geter 方法中收集依赖,让发生修改是 setter 中调用依赖通知更新。
与 redux 相比:
1、redux 是单向数据流,state 是不可变的,只能通过 reducer 返回新的 state。而 mobx 是响应式的,通过劫持 state 的 set 和 get 来触发更新,state 是可以直接改变的
2、store 管理上,在 Redux 应用中,我们总是将所有共享的应用数据集中在一个大的 store 中,而 Mobx 则通常按模块将应用状态划分,在多个独立的 store 中管理。
3、存储数据上,Redux 默认以 JavaScript 原生对象形式存储数据,而 Mobx 使用可观察对象:
key 在 diff 中的作用
主要是在 reconcileChildrenArray 时,也就是多节点对比时,为了降低时间复杂度,会通过 key 来对比新旧节点是否复用。如果 type 不变且 key 变,那么节点就会被复用,只会看属性是否会有变化并对应更新。
什么场景会触发重新渲染(re-render)
组件发生重新渲染有四个原因:状态更改、父级(或子级)重新渲染、context 变化以及 hooks 变化。这里有一个很大的误区:当组件的 props 改变时,组件会重新渲染。就其本身而言,这并不是真的(见本文后面的介绍)。
状态变化
当组件的状态发生变化时,它将重新渲染自身。通常,它发生在回调或 useEffect 中。状态变化是所有重新渲染的根因。
父组件重新渲染
如果组件的父组件重新渲染,则组件将重新渲染自身。反过来看也是对的:当组件重新渲染时,它也会重新渲染其所有子组件。但是,子组件的重新渲染不会触发父级的 re-render。
context 变化
当 Context Provider 中的值发生变化时,使用该 Context 的所有组件都要 re-render,即使它们并没有使用发生变化的那部分数据。这些 re-render 并不能直接通过 memoize 来避免掉,但是可以用一些变通的方法来避免
hooks 变化
hooks 中发生的一切都“属于”使用它的组件。因此 Context 和 State 的更新规则同样也适用于这里:
- hooks 内部的状态变化会触发组件的 re-render
- 如果 hooks 使用了 context,并且 context 的值发生了变化,也会触发组件的 re-render
hooks 可以嵌套使用,其中每个 hooks 都 “属于” 使用它的组件,相同的规则适用于其中任何一个 hooks。
props 变化
说到未被 memo 包裹的组件 re-render 时,组件的 props 是否发生变化并不重要。组件的 props 即便是发生了改变,也是由父组件来更新它们。也就是说,父组件的重新渲染触发了子组件的重新渲染,与子组件的 props 是否变化无关。只有那些使用了 React.memo 和 useMemo 的组件,props 的变化才会触发组件的重新渲染。
useEffect、useMemo、useCallback 是如何做依赖收集的
第二个参数可以传数组,其中包含的就是依赖项
vue 和 react 在虚拟 dom 的 diff 上,做了哪些改进使得速度很快?
传统 diff
计算两颗树形结构差异并进行转换,传统 diff 算法是这样做的:循环递归每一个节点 。传统 diff 算法复杂度达到 O(n^3 )这意味着 1000 个节点就要进行数 10 亿次的比较,这是非常消耗性能的。react 大胆的将 diff 的复杂度从 O(n^3)降到了 O(n)
1.vue 的 diff 算法
diff 算法发生在虚拟 dom 上
判断是否同一个节点:selector 和 key 都要一样
diff 规则:
- 只比较同层的节点,不同层不做比较。删除原节点,并且新建插入更新节点(实际开发中很少遇到)
- 新旧节点是同层节点,但不是同一个节点,不做精细化比较。删除原节点,并且新建插入更新节点(实际开发中很少遇到)
- 新旧节点是同层节点,也是同一个节点,需要做精细化比较
2.react 的 diff 算法
从左往右依次对比,利用元素的 index 和标识 lastIndex 进行比较,如果满足 index < lastIndex 就移动元素,删除和添加则各自按照规则调整
跨层不比较,同层比较,跟 vue 一样
diff 策略
新节点的位置是 lastIndex,旧节点的位置是 index。从新的节点中依次读取节点索引,对比旧的节点数据索引
- 不满足 index < lastIndex 的条件,不移动;满足 index < lastIndex 的条件,移动节点。
- 每一次比较都需要重新设置 lastIndex=(index,lastIndex)中的较大数
- 移动的节点在前一个被操作的节点后面
- 如果从新的节点集合获取的节点在旧节点集合未找到,就是新增,lastIndex 为上一次的值不变
- 如果新的节点集合遍历完了,旧节点还有值就是删除,loop 删除掉就行
最恶心的情况:如果把最后一个元素移到最前面,react 会依次移动节点向后
3.对比
相同点:
Vue 和 react 的 diff 算法,都是不进行跨层级比较,只做同级比较。
不同点:
1.Vue 进行 diff 时,调用 patch 打补丁函数,一边比较一边给真实的 DOM 打补丁 2.Vue 对比节点,当节点元素类型相同,但是 className 不同时,认为是不同类型的元素,删除重新创建,而 react 则认为是同类型节点,进行修改操作 3.
① Vue 的列表比对,采用从两端到中间的方式,旧集合和新集合两端各存在两个指针,两两进行比较,如果匹配上了就按照新集合去调整旧集合,每次对比结束后,指针向队列中间移动; ② 而 react 则是从左往右依次对比,利用元素的 index 和标识 lastIndex 进行比较,如果满足 index < lastIndex 就移动元素,删除和添加则各自按照规则调整; ③ 当一个集合把最后一个节点移动到最前面,react 会把前面的节点依次向后移动,而 Vue 只会把最后一个节点放在最前面,这样的操作来看,Vue 的 diff 性能是高于 react 的
vue 和 react 里的 key 的作用是什么? 为什么不能用 index?用了会怎样? 如果不加 key 会怎样?
作为多节点是否可以复用的参考依据
index 不稳定,如果 index 没变但是元素变了就无法更新了
不加 key 就相当于全量更新无法复用子节点
react diff 算法和 vue diff 算法的区别
相同点
只有使用了虚拟 DOM 的这些框架,在进行更新 Diff 对比的时候,都是优先处理简单的场景,再处理复杂的场景。
React 中是先处理左边部分,左边部分处理不了,再进行复杂部分的处理;
Vue2 则先进行首尾、首首、尾尾部分的处理,然后再进行中间复杂部分的处理;
Vue3 则先处理首尾部分,然后再处理中间复杂部分,
Vue2 和 Vue3 最大的区别就是在处理中间复杂部分使用了最长递增子序列算法找出稳定序列的部分。
在处理老节点部分,都需要把节点处理 key - value 的 Map 数据结构,方便在往后的比对中可以快速通过节点的 key 取到对应的节点。同样在比对两个新老节点是否相同时,key 是否相同也是非常重要的判断标准。所以不同是 React, 还是 Vue,在写动态列表的时候,都需要设置一个唯一值 key,这样在 diff 算法处理的时候性能才最大化。
在移动或者创建节点的时候都使用了 insertBefore(newnode,existingnode) 这个 API:
- newnode 必需。需要插入的节点对象。
- existingnode 可选。在其之前插入新节点的子节点。如果未规定,则 insertBefore 方法会在结尾插入 newnode。
不同点
对静态节点的处理不一样。
由于 Vue 是通过 template 模版进行编译的,所以在编译的时候可以很好对静态节点进行分析然后进行打补丁标记,然后在 Diff 的时候,Vue2 是判断如果是静态节点则跳过过循环对比,而 Vue3 则是把整个静态节点进行提升处理,Diff 的时候是不过进入循环的,所以 Vue3 比 Vue2 的 Diff 性能更高效。而 React 因为是通过 JSX 进行编译的,是无法进行静态节点分析的,所以 React 在对静态节点处理这一块是要逊色的。
Vue2 和 Vue3 的比对和更新是同步进行的,这个跟 React15 是相同的,就是在比对的过程中,如果发现了那些节点需要移动或者更新或删除,是立即执行的,也就是 React 中常讲的不可中断的更新,如果比对量过大的话,就会造成卡顿,所以 React16 起就更改为了比对和更新是异步进行的,所以 React16 以后的 Diff 是可以中断,Diff 和任务调度都是在内存中进行的,所以即便中断了,用户也不会知道。
另外 Vue2 和 Vue3 都使用了双端对比算法,而 React 的 Fiber 由于是单向链表的结构,所以在 React 不设置由右向左的链表之前,都无法实现双端对比。那么双端对比目前 React 的 Diff 算法要好吗?接下来我们来看看一个例子,看看它分别在 React、Vue2、Vue3 中的是怎么处理的。
比如说我们现在有以下两组新老节点:
老:A, B, C, D
新:D, A, B, C
那么我们可以看到,新老两组节点唯一的不同点就是,D 节点在新的节点中跑到开头去了,像这种情况:
React 是从左向右进行比对的,在上述这种情况,React 需要把 A, B, C 三个节点分别移动到 D 节点的后面。
Vue2 在进行老节点的结尾与新节点的开始比对的时候,就发现这两个节点是相同的,所以直接把老节点结尾的 D 移动到新节点开头就行了,剩下的就只进行老节点的开始与新节点的开始进行比对,就可以发现它们的位置并没有发生变化,不需要进行移动。
Vue3 是没有了 Vue2 的新老首尾节点进行比较,只是从两组节点的开头和结尾进行比较,然后往中间靠拢,那么 Vue3 在进行新老节点的开始和结尾比对的时候,都没有比对成功,接下来就进行中间部分的比较,先把老节点处理成 key - value 的 Map 数据结构,然后又使用最长递增子序列算法找出其中的稳定序列部分,也就是:A, B, C,然再对新节点进行循环比对,然后就会发现新节点的 A, B, C 都在稳定序列部分,不需要进行移动,然就只对 D,进行移动即可。
最后上述的例子在 Vue2 和 Vue3 中都只需要移动一个节点就可以完成 Diff 算法比对,而 React 在这种极端例子中则没办法进行很好的优化,需要进行多次节点移动操作。
Vue
vue2.0 和 vue3.0 区别
Vue 内部根据功能可以被分为三个大的模块:响应性 reactivite、运行时 runtime、编辑器 compiler,以及一些小的功能点。那么要说 vue2 与 vue3 的区别,我们需要从这三个方面加小的功能点进行说起。
首先先来说 响应性 reactivite:
vue2 的响应性主要依赖 Object.defineProperty 进行实现,但是 Object.defineProperty 只能监听 指定对象的指定属性的 getter 行为和 setter 行为,那么这样在某些情况下就会出现问题。
什么问题呢?
比如说:我们在 data 中声明了一个对象 person ,但是在后期为 person 增加了新的属性,那么这个新的属性就会失去响应性。想要解决这个问题其实也非常的简单,可以通过 Vue.$set 方法来增加 指定对象指定属性的响应性。但是这样的一种方式,在 Vue 的自动响应性机制中是不合理。
所以在 Vue3 中,Vue 引入了反射和代理的概念,所谓反射指的是 Reflect,所谓代理指的是 Proxy。我们可以利用 Proxy 直接代理一个普通对象,得到一个 proxy 实例 的代理对象。在 vue3 中,这个过程通过 reactive 这个方法进行实现。
但是 proxy 只能实现代理复杂数据类型,所以 vue 额外提供了 ref 方法,用来处理简单数据类型的响应性。ref 本质上并没有进行数据的监听,而是构建了一个 RefImpl 的类,通过 set 和 get 标记了 value 函数,以此来进行的实现。所以 ref 必须要通过 .value 进行触发,之所以要这么做本质是调用 value 方法。
接下来是运行时 runtime:
所谓的运行时,大多数时候指的是 renderer 渲染器,渲染器本质上是一个对象,内部主要三个方法 render、hydrate、createApp ,其中 render 主要处理渲染逻辑,hydrate 主要处理服务端渲染逻辑,而 createApp 就是创建 vue 实例的方法。
这里咱们主要来说 render 渲染函数,vue3 中为了保证宿主环境与渲染逻辑的分离,把所有与宿主环境相关的逻辑进行了抽离,通过接口的形式进行传递。这样做的目的其实是为了解绑宿主环境与渲染逻辑,以保证 vue 在非浏览器端的宿主环境下可以正常渲染。
再往下是 编辑器 compiler:
vue 中的 compiler 其实是一个 DSL(特定领域下专用语言编辑器) ,其目的是为了把 template 模板 编译成 render 函数。 逻辑主要是分成了三大步: parse、transform 和 generate。其中 parse 的作用是为了把 template 转化为 AST(抽象语法树),transform 可以把 AST(抽象语法树) 转化为 JavaScript AST,最后由 generate 把 JavaScript AST 通过转化为 render 函数。转化的过程中会涉及到一些稍微复杂的概念,比如 有限自动状态机 这个就不再这里展开说了。
除此之外,还有一些其他的变化。比如 vue3 新增的 composition API。 composition API 在 vue3.0 和 vue3.2 中会有一些不同的呈现,比如说:最初的 composition API 以 setup 函数作为入口函数, setup 函数必须返回两种类型的值:第一是对象,第二是函数。
当 setup 函数返回对象时,对象中的数据或方法可以在 template 中被使用。当 setup 函数返回函数时,函数会被作为 render 函数。
但是这种 setup 函数的形式并不好,因为所有的逻辑都集中在 setup 函数中,很容易出现一个巨大的 setup 函数,我们把它叫做巨石(屎山)函数。所以 vue 3.2 的时候,新增了一个 script setup 的语法糖,尝试解决这个问题。目前来看 script setup 的呈现还是非常不错的。
除此之外还有一些小的变化,比如 Fragment、Teleport、Suspense 等等,这些就不去说了...
双向绑定原理
双向数据绑定通常是指我们使用的v-model指令的实现,是Vue的一个特性,也可以说是一个input事件和value的语法糖。 Vue通过v-model指令为组件添加上input事件处理和value属性的赋值。
什么是数据双向绑定?
vue 是一个 mvvm 框架,即数据双向绑定,即当数据发生变化的时候,视图也就发生变化,当视图发生变化的时候,数据也会跟着同步变化。这也算是 vue 的精髓之处了。值得注意的是, 我们所说的数据双向绑定,一定是对于 UI 控件来说的,非 UI 控件不会涉及到数据双向绑定。 单向数据绑定是使用状态管理工具(如 redux)的前提。如果我们使用 vuex,那么数据流也是单项的,这时就会和双向数据绑定有冲突。
为什么要实现数据的双向绑定?
在 vue 中,如果使用 vuex,实际上数据还是单向的,之所以说是数据双向绑定,这是用的 UI 控件来说,对于我们处理表单,vue 的双向数据绑定用起来就特别舒服了。
即两者并不互斥, 在全局性数据流使用单项,方便跟踪; 局部性数据流使用双向,简单易操作。
实现一个简单的数据双向绑定还是不难的: 使用 Object.defineProperty()来定义属性的 set 函数,属性被赋值的时候,修改 Input 的 value 值以及 span 中的 innerHTML;然后监听 input 的 keyup 事件,修改对象的属性值,即可实现这样的一个简单的数据双向绑定。
vue 组件通信方式
1、父组件通过props的方式向子组件传递数据,而通过$emit 子组件可以向父组件通信。
2、$children / $parent,通过$parent和$children就可以访问组件的实例,拿到实例代表什么?代表可以访问此组件的所有方法和data。
3、provide/ inject,provide/ inject 是vue2.2.0新增的 api, 简单来说就是父组件中通过provide来提供变量, 然后再子组件中通过inject来注入变量。
4、ref / refs,ref:如果在普通的 DOM 元素上使用,引用指向的就是 DOM 元素;如果用在子组件上,引用就指向组件实例,可以通过实例直接调用组件的方法或访问数据。this.$refs.childA.xxx()....
5、eventBus 又称为事件总线,在 vue 中可以使用它来作为沟通桥梁的概念, 就像是所有组件共用相同的事件中心,可以向该中心注册发送事件或接收事件, 所以组件都可以通知其他组件。
6、Vuex
7、localStorage / sessionStorage
8、$attrs与 $listeners
常见使用场景可以分为三类:
- 父子组件通信:
props;$parent/$children;provide/inject;ref;$attrs/$listeners - 兄弟组件通信:
eventBus; vuex - 跨级通信:
eventBus;Vuex;provide/inject、$attrs/$listeners
v-for 为什么需要 key
Vue 在处理更新同类型 vnode 的一组子节点的过程中,为了减少 DOM 频繁创建和销毁的性能开销:
对没有 key 的子节点数组更新调用的是patchUnkeyedChildren这个方法,核心是就地更新的策略。它会通过对比新旧子节点数组的长度,先以比较短的那部分长度为基准,将新子节点的那一部分直接 patch 上去。然后再判断,如果是新子节点数组的长度更长,就直接将新子节点数组剩余部分挂载(mount);如果是新子节点数组更短,就把旧子节点多出来的那部分给卸载掉(unmount)。所以如果子节点是组件或者有状态的 DOM 元素,原有的状态会保留,就会出现渲染不正确的问题。
有 key 的子节点更新是调用的patchKeyedChildren,这个函数就是大家熟悉的实现核心 diff 算法的地方,大概流程就是同步头部节点、同步尾部节点、处理新增和删除的节点,最后用求解最长递增子序列的方法区处理未知子序列。是为了最大程度实现对已有节点的复用,减少 DOM 操作的性能开销,同时避免了就地更新带来的子节点状态错误的问题。
综上,如果是用 v-for 去遍历常量或者子节点是诸如纯文本这类没有”状态“的节点,是可以使用不加 key 的写法的。但是实际开发过程中更推荐统一加上 key,能够实现更广泛场景的同时,避免了可能发生的状态更新错误,我们一般可以使用 ESlint 配置 key 为 v-for 的必需元素。
diff 算法原理
Diff 算法是一种对比算法。对比两者是旧虚拟DOM和新虚拟DOM,对比出是哪个虚拟节点更改了,找出这个虚拟节点,并只更新这个虚拟节点所对应的真实节点,而不用更新其他数据没发生改变的节点,实现精准地更新真实 DOM,进而提高效率。
使用虚拟DOM算法的损耗计算: 总损耗 = 虚拟 DOM 增删改+(与 Diff 算法效率有关)真实 DOM 差异增删改+(较少的节点)排版与重绘
直接操作真实DOM的损耗计算: 总损耗 = 真实 DOM 完全增删改+(可能较多的节点)排版与重绘
Diff 算法的原理
Diff 同层对比
新旧虚拟 DOM 对比的时候,Diff 算法比较只会在同层级进行, 不会跨层级比较。 所以 Diff 算法是:深度优先算法。 时间复杂度:O(n)
Diff 对比流程
当数据改变时,会触发setter,并且通过Dep.notify去通知所有订阅者Watcher,订阅者们就会调用patch方法,给真实 DOM 打补丁,更新相应的视图。对于这一步不太了解的可以看一下我之前写Vue 源码系列
newVnode和oldVnode:同层的新旧虚拟节点
patch 方法
这个方法作用就是,对比当前同层的虚拟节点是否为同一种类型的标签(同一类型的标准,下面会讲):
- 是:继续执行
patchVnode方法进行深层比对 - 否:没必要比对了,直接整个节点替换成
新虚拟节点
来看看patch的核心原理代码
function patch(oldVnode, newVnode) {
// 比较是否为一个类型的节点
if (sameVnode(oldVnode, newVnode)) {
// 是:继续进行深层比较
patchVnode(oldVnode, newVnode);
} else {
// 否
const oldEl = oldVnode.el; // 旧虚拟节点的真实DOM节点
const parentEle = api.parentNode(oldEl); // 获取父节点
createEle(newVnode); // 创建新虚拟节点对应的真实DOM节点
if (parentEle !== null) {
api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)); // 将新元素添加进父元素
api.removeChild(parentEle, oldVnode.el); // 移除以前的旧元素节点
// 设置null,释放内存
oldVnode = null;
}
}
return newVnode;
}
sameVnode 方法
patch 关键的一步就是sameVnode方法判断是否为同一类型节点,那问题来了,怎么才算是同一类型节点呢?这个类型的标准是什么呢?
咱们来看看 sameVnode 方法的核心原理代码,就一目了然了
function sameVnode(oldVnode, newVnode) {
return (
oldVnode.key === newVnode.key && // key值是否一样
oldVnode.tagName === newVnode.tagName && // 标签名是否一样
oldVnode.isComment === newVnode.isComment && // 是否都为注释节点
isDef(oldVnode.data) === isDef(newVnode.data) && // 是否都定义了data
sameInputType(oldVnode, newVnode) // 当标签为input时,type必须是否相同
);
}
patchVnode 方法
这个函数做了以下事情:
- 找到对应的
真实DOM,称为el - 判断
newVnode和oldVnode是否指向同一个对象,如果是,那么直接return - 如果他们都有文本节点并且不相等,那么将
el的文本节点设置为newVnode的文本节点。 - 如果
oldVnode有子节点而newVnode没有,则删除el的子节点 - 如果
oldVnode没有子节点而newVnode有,则将newVnode的子节点真实化之后添加到el - 如果两者都有子节点,则执行
updateChildren函数比较子节点,这一步很重要
function patchVnode(oldVnode, newVnode) {
const el = (newVnode.el = oldVnode.el); // 获取真实DOM对象
// 获取新旧虚拟节点的子节点数组
const oldCh = oldVnode.children,
newCh = newVnode.children;
// 如果新旧虚拟节点是同一个对象,则终止
if (oldVnode === newVnode) return;
// 如果新旧虚拟节点是文本节点,且文本不一样
if (
oldVnode.text !== null &&
newVnode.text !== null &&
oldVnode.text !== newVnode.text
) {
// 则直接将真实DOM中文本更新为新虚拟节点的文本
api.setTextContent(el, newVnode.text);
} else {
// 否则
if (oldCh && newCh && oldCh !== newCh) {
// 新旧虚拟节点都有子节点,且子节点不一样
// 对比子节点,并更新
updateChildren(el, oldCh, newCh);
} else if (newCh) {
// 新虚拟节点有子节点,旧虚拟节点没有
// 创建新虚拟节点的子节点,并更新到真实DOM上去
createEle(newVnode);
} else if (oldCh) {
// 旧虚拟节点有子节点,新虚拟节点没有
//直接删除真实DOM里对应的子节点
api.removeChild(el);
}
}
}
其他几个点都很好理解,我们详细来讲一下updateChildren
updateChildren 方法
这是patchVnode里最重要的一个方法,新旧虚拟节点的子节点对比,就是发生在updateChildren方法中,接下来就结合一些图来讲,让大家更好理解吧
是怎么样一个对比方法呢?就是首尾指针法,新的子节点集合和旧的子节点集合,各有首尾两个指针,举个例子:
<ul>
<li>a</li>
<li>b</li>
<li>c</li>
</ul>
修改数据后
<ul>
<li>b</li>
<li>c</li>
<li>e</li>
<li>a</li>
</ul>
那么新旧两个子节点集合以及其首尾指针为:
然后会进行互相进行比较,总共有五种比较情况:
- 1、
oldS 和 newS使用sameVnode方法进行比较,sameVnode(oldS, newS) - 2、
oldS 和 newE使用sameVnode方法进行比较,sameVnode(oldS, newE) - 3、
oldE 和 newS使用sameVnode方法进行比较,sameVnode(oldE, newS) - 4、
oldE 和 newE使用sameVnode方法进行比较,sameVnode(oldE, newE) - 5、如果以上逻辑都匹配不到,再把所有旧子节点的
key做一个映射到旧节点下标的key -> index表,然后用新vnode的key去找出在旧节点中可以复用的位置。
接下来就以上面代码为例,分析一下比较的过程
分析之前,请大家记住一点,最终的渲染结果都要以 newVDOM 为准,这也解释了为什么之后的节点移动需要移动到 newVDOM 所对应的位置
- 第一步
(oldS = a), (oldE = c);
(newS = b), (newE = a);
比较结果:oldS 和 newE 相等,需要把节点a移动到newE所对应的位置,也就是末尾,同时oldS++,newE--
- 第二步
(oldS = b), (oldE = c);
(newS = b), (newE = e);
比较结果:oldS 和 newS相等,需要把节点b移动到newS所对应的位置,同时oldS++,newS++
- 第三步
(oldS = c), (oldE = c);
(newS = c), (newE = e);
比较结果:oldS、oldE 和 newS相等,需要把节点c移动到newS所对应的位置,同时oldS++,newS++
- 第四步
oldS > oldE,则oldCh先遍历完成了,而newCh还没遍历完,说明newCh比oldCh多,所以需要将多出来的节点,插入到真实 DOM 上对应的位置上
- 思考题 我在这里给大家留一个思考题哈。上面的例子是
newCh比oldCh多,假如相反,是oldCh比newCh多的话,那就是newCh先走完循环,然后oldCh会有多出的节点,结果会在真实 DOM 里进行删除这些旧节点。大家可以自己思考一下,模拟一下这个过程,像我一样,画图模拟,才能巩固上面的知识。
附上updateChildren的核心原理代码
function updateChildren(parentElm, oldCh, newCh) {
let oldStartIdx = 0,
newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx;
let idxInOld;
let elmToMove;
let before;
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx];
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx];
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode);
api.insertBefore(
parentElm,
oldStartVnode.el,
api.nextSibling(oldEndVnode.el)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode);
api.insertBefore(parentElm, oldEndVnode.el, oldStartVnode.el);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
// 使用key时的比较
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx); // 有key生成index表
}
idxInOld = oldKeyToIdx[newStartVnode.key];
if (!idxInOld) {
api.insertBefore(
parentElm,
createEle(newStartVnode).el,
oldStartVnode.el
);
newStartVnode = newCh[++newStartIdx];
} else {
elmToMove = oldCh[idxInOld];
if (elmToMove.sel !== newStartVnode.sel) {
api.insertBefore(
parentElm,
createEle(newStartVnode).el,
oldStartVnode.el
);
} else {
patchVnode(elmToMove, newStartVnode);
oldCh[idxInOld] = null;
api.insertBefore(parentElm, elmToMove.el, oldStartVnode.el);
}
newStartVnode = newCh[++newStartIdx];
}
}
}
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].el;
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx);
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}
响应式原理
vue2 依赖 Object.defineProperty
vue3 依赖 Proxy 和 Reflect
一个响应式数据最基本的实现依赖于对“读取”和“设置”操作的拦截,从而在副作用函数与响应式数据之间建立联系。当“读取”操作发生时,我们将当前执行的副作用函数存储到“桶”中;当“设置”操作发生时,再将副作用函数从“桶”里取出并执行。这就是响应系统的根本实现原理。
在 Vue3 实现的 Proxy 中,在 get 中收集依赖,并构成依赖树,每个 key 有一个数组分别保存依赖的监听者,然后当 set 触发时,会一次触发监听者的回调。为了解决分支切换问题,每次副作用都会清理之前建立的响应关系。
computed 和 watch 区别和原理
computed 看上去是方法,但是实际上是计算属性,它会根据你所依赖的数据动态显示新的计算结果。计算结果会被缓存,computed 的值在 getter 执行后是会缓存的,只有在它依赖的属性值改变之后,下一次获取 computed 的值时才会重新调用对应的 getter 来计算
watcher 更像是一个 data 的数据监听回调,当依赖的 data 的数据变化,执行回调,在方法中会传入 newVal 和 oldVal。可以提供输入值无效,提供中间值 特场景。Vue 实例将会在实例化时调用 $watch(),遍历 watch 对象的每一个属性。如果你需要在某个数据变化时做一些事情,使用 watch。
1.如果一个数据依赖于其他数据,那么把这个数据设计为 computed 的
2.如果你需要在某个数据变化时做一些事情,使用 watch 来观察这个数据变化
nextTick 原理
当你在 Vue 中更改响应式状态时,最终的 DOM 更新并不是同步生效的,而是由 Vue 将它们缓存在一个队列中,直到下一个“tick”才一起执行。这样是为了确保每个组件无论发生多少状态改变,都仅执行一次更新。
nextTick() 可以在状态改变后立即使用,以等待 DOM 更新完成。你可以传递一个回调函数作为参数,或者 await 返回的 Promise。
Vue2 实现上主要是判断用哪个宏任务或微任务,因为宏任务耗费的时间是大于微任务的,所以成先使用微任务,判断顺序如下
PromiseMutationObserversetImmediatesetTimeout
Vu3 是基于 promise 实现的。
export function nextTick<T = void>(
this: T,
fn?: (this: T) => void
): Promise<void> {
const p = currentFlushPromise || resolvedPromise;
return fn ? p.then(this ? fn.bind(this) : fn) : p;
}
vue 怎样自定义一个 plugin
一个插件可以是一个拥有 install() 方法的对象,也可以直接是一个安装函数本身。安装函数会接收到安装它的应用实例和传递给 app.use() 的额外选项作为参数.
让我们从设置插件对象开始。建议在一个单独的文件中创建并导出它,以保证更好地管理逻辑,如下所示:
// plugins/i18n.js
export default {
install: (app, options) => {
// 在这里编写插件代码
},
};
我们希望有一个翻译函数,这个函数接收一个以 . 作为分隔符的 key 字符串,用来在用户提供的翻译字典中查找对应语言的文本。期望的使用方式如下:
<h1>{{ $translate('greetings.hello') }}</h1>
这个函数应当能够在任意模板中被全局调用。这一点可以通过在插件中将它添加到 app.config.globalProperties 上来实现:
// plugins/i18n.js
export default {
install: (app, options) => {
// 注入一个全局可用的 $translate() 方法
app.config.globalProperties.$translate = (key) => {
// 获取 `options` 对象的深层属性
// 使用 `key` 作为索引
return key.split(".").reduce((o, i) => {
if (o) return o[i];
}, options);
};
},
};
我们的 $translate 函数会接收一个例如 greetings.hello 的字符串,在用户提供的翻译字典中查找,并返回翻译得到的值。
用于查找的翻译字典对象则应当在插件被安装时作为 app.use() 的额外参数被传入:
import i18nPlugin from "./plugins/i18n";
app.use(i18nPlugin, {
greetings: {
hello: "Bonjour!",
},
});
vue.use 原理,做了哪些事
use(plugin: Plugin, ...options: any[]) {
if (installedPlugins.has(plugin)) {
__DEV__ && warn(`Plugin has already been applied to target app.`)
} else if (plugin && isFunction(plugin.install)) {
installedPlugins.add(plugin)
plugin.install(app, ...options)
} else if (isFunction(plugin)) {
installedPlugins.add(plugin)
plugin(app, ...options)
} else if (__DEV__) {
warn(
`A plugin must either be a function or an object with an "install" ` +
`function.`
)
}
return app
},
Vue 和 React 区别
两者的区别体现在以下方面
相同点:
1、react 和 vue 都支持服务端渲染
2、都有虚拟 DOM,组件化开发,通过 props 传参进行父子组件数据的传递
3、都是数据驱动视图
4、都有支持 native 的方案(react 的 react native,vue 的 weex)
5、都有状态管理(react 有 redux,vue 有 vuex)
不同点:
1、react 严格上只能算是 MVC 的 view 层,vue 则是 MVVM 模式
2、虚拟 DOM 不一样,vue 会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树
而对于 react 而言,每当应用的状态被改变时,全部组件都会重新渲染,所以 react 中会需要 shouldComponentUpdate 这个生命周期函数方法来进行控制
3、组件写法不一样,react 推荐的做法是 JSX+inline style,也就是把 HTML 和 CSS 全都写进 javaScript 了
4、数据绑定:vue 实现了数据的双向绑定,react 数据流动是单向的
5、state 对象在 react 应用中是不可变的,需要使用 setState 方法更新状态
在 vue 中,state 对象不是必须的,数据有 data 属性在 vue 对象中管理
v-model 原理
v-model 其实就是一个语法糖 他的本质其实就是两个操作
1.v-bind 绑定一个 value 属性
2.v-on 绑定一个 input 事件
Vuex 流程和原理
import { createApp } from "vue";
import { createStore } from "vuex";
// 创建一个新的 store 实例
const store = createStore({
state() {
return {
count: 0,
};
},
mutations: {
increment(state) {
state.count++;
},
},
});
const app = createApp({
/* 根组件 */
});
// 将 store 实例作为插件安装
app.use(store);
首先通过 use 函数作为插件注册到 vue 实例上,因此 vuex 中一定使用了 install 函数
install (app, injectKey) {
app.provide(injectKey || storeKey, this)
app.config.globalProperties.$store = this
const useDevtools = this._devtools !== undefined
? this._devtools
: __DEV__ || __VUE_PROD_DEVTOOLS__
if (useDevtools) {
addDevtools(app, this)
} }
install 中使用 provide 方法讲 store 实例注册到了全局。
Store 上包含了常见的 get 和 set 等方法,并使用 computed 和 reactive 等 vue api 实现了响应式。
vue 的 keep-alive 的作用是什么?怎么实现的?如何刷新的?
<KeepAlive> 是一个内置组件,它的功能是在多个组件间动态切换时缓存被移除的组件实例。被keep-alive包裹的组件,会被保留在组件树里,你可以继续操作其他叶子节点的组件,但是其他叶子节点的组件还会正常经历创建,生成,销毁的完整的声明周期,你重新访问组件的时候什么都是新的了,而这个被keep-alive 包裹的组件就一直长在树上了,会一直存在,除了会经历创建生成,在页面卸载之前不会被销毁,你可以浅薄的理解为,像闭包一样保存在内存中不会消亡。在 Vue 中,就体现为,始终将该组件保留在虚拟 DOM 中,并且保持该组件以及后代组件的状态,只不过不渲染而已了,这里敲下黑板,注意一下,是始终将该组件保留在虚拟 DOM 中,并且保持该组件以及后代组件的状态但是不渲染了。嗯,没错,你引入的组件的后代组件也会被缓存的。
在 keep-alive 标签上,存在两个属性(以下定义是个人总结,请重点记忆):
include:包含,包含在这个集合或者用正则匹配到的 name 值的组件会被缓存
exclude:排查 包含在这个集合或者用正则匹配到的 name 值的组件不会被缓存
使用 LRU 删除缓存
vue 是怎么解析 template 的? template 会变成什么?
Vue 的模版编译过程主要如下:template->ast->render函数。
Vue 在模版编译中会执行compileToFunctions将template转化为render函数。
- 调用 parse 方法将 template 转化为 ast(抽象语法树)
- optimize对静态节点做优化
- generate 将 ast 抽象语法树编译成
render字符串并将静态部分放到staticRenderFns中,最后通过new Function(render)生成 render 函数。
怎样自己封装一些指令
将一个自定义指令全局注册到应用层级也是一种常见的做法:
const app = createApp({});
// 使 v-focus 在所有组件中都可用
app.directive("focus", {
/* ... */
});
一个指令的定义对象可以提供几种钩子函数 (都是可选的):
const myDirective = {
// 在绑定元素的 attribute 前
// 或事件监听器应用前调用
created(el, binding, vnode, prevVnode) {
// 下面会介绍各个参数的细节
},
// 在元素被插入到 DOM 前调用
beforeMount(el, binding, vnode, prevVnode) {},
// 在绑定元素的父组件
// 及他自己的所有子节点都挂载完成后调用
mounted(el, binding, vnode, prevVnode) {},
// 绑定元素的父组件更新前调用
beforeUpdate(el, binding, vnode, prevVnode) {},
// 在绑定元素的父组件
// 及他自己的所有子节点都更新后调用
updated(el, binding, vnode, prevVnode) {},
// 绑定元素的父组件卸载前调用
beforeUnmount(el, binding, vnode, prevVnode) {},
// 绑定元素的父组件卸载后调用
unmounted(el, binding, vnode, prevVnode) {},
};
声明式和命令式的区别和好处
命令式更加关注过程,而声明式更加关注结果。命令式在理论上可以做到极致优化,但是用户要承受巨大的心智负担;而声明式能够有效减轻用户的心智负担,但是性能上有一定的牺牲,框架设计者要想办法尽量使性能损耗最小化。
vuex 为什么同时设计 mutation 和 action?只设计一个行不行?
不行,action 异步,mutaition 同步
vue2 和 vue3 在数据绑定这一块有什么区别?
一个使用了 defineProperty,一个使用了 proxy
vue 挂载和卸载父子组件生命周期钩子执行顺序

小程序
小程序的架构和原理?
小程序的架构模型有别与传统 web 单线程架构,小程序为双线程架构。
微信小程序的渲染层与逻辑层分别由两个线程管理,渲染层的界面使用 webview 进行渲染;逻辑层采用 JSCore运行JavaScript代码。

Webview 渲染线程

JSCore 逻辑线程

双线程分别做什么事儿?为什么有两个线程?
加载及渲染性能
小程序的设计之初就是要求快速,这里的快指的是加载以及渲染。
目前主流的渲染方式有以下 3 种:
- Web 技术渲染
- Native 技术渲染
- Hybrid 技术渲染(同时使用了 webview 和原生来渲染)
从小程序的定位来讲,它就不可能用纯原生技术来进行开发,因为那样它的编译以及发版都得跟随微信,所以需要像 Web 技术那样,有一份随时可更新的资源包放在远程,通过下载到本地,动态执行后即可渲染出界面。
但如果用纯web技术来开发的话,会有一个很致命的缺点那就是在 Web 技术中,UI 渲染跟 JavaScript 的脚本执行都在一个单线程中执行,这就容易导致一些逻辑任务抢占 UI 渲染的资源,这也就跟设计之初要求的快相违背了。
因此微信小程序选择了 Hybrid 技术,界面主要由成熟的 Web 技术渲染,辅之以大量的接口提供丰富的客户端原生能力。同时,每个小程序页面都是用不同的 WebView 去渲染,这样可以提供更好的交互体验,更贴近原生体验,也避免了单个 WebView 的任务过于繁重。
微信小程序是以 webview 渲染为主,原生渲染为辅的混合渲染方式
管控安全
由于 web 技术的灵活开放特点,如果基于纯 web 技术来渲染小程序的话,势必会存在一些不可控因素和安全风险。
为了解决安全管控的问题,小程序从设计上就阻止了开发者去使用一些浏览器提供的开放性 api,比如说跳转页面、操作 DOM 等等。如果把这些东西一个一个地去加入到黑名单,那么势必会陷入一个非常糟糕的循环,因为浏览器的接口也非常丰富,那么就很容易遗漏一些危险的接口,而且就算是禁用掉了所有的接口,也防不住浏览器内核的下次更新。
所以要彻底解决这个问题,必须提供一个沙箱环境来运行开发者的JavaScript 代码。这个沙箱环境只提供纯 JavaScript 的解释执行环境,没有任何浏览器相关接口。那么像HTML5中的ServiceWorker、WebWorker特性就符合这样的条件,这两者都是启用另一线程来执行 javaScript。
这就是小程序双线程模型的由来:
- 渲染层: 界面渲染相关的任务全都在 WebView 线程里执行,通过逻辑层代码去控制渲染哪些界面。一个小程序存在多个界面,所以渲染层存在多个 WebView。
- 逻辑层: 创建一个单独的线程去执行 JavaScript,在这个环境下执行的都是有关小程序业务逻辑的代码。
小程序为什么不直接使用webComponent,而是选择自行搭建一套组件系统?
- 管控与安全:web 技术可以通过脚本获取修改页面敏感内容或者随意跳转其它页面
- 能力有限:会限制小程序的表现形式
- 标签众多:增加理解成本
微信小程序编译原理
打开微信开发者工具的WeappVendor文件夹,

在这里我们我们会看到一些wxvpkg文件,这是小程序的各个版本的基础库文件,还有两个值得我们注意的文件:wcc、wcsc,这两个文件是小程序的编译器,分别用来编译wxml和wxss文件。
编译 wxml:
随便写一个 wxml 文件
<view>
<text>wxml编译测试</text>
<view>{{ name }}</view>
</view>
运行
./wcc.exe -b test.wxml >> wxml_output.js

然后它会在当前目录下生成一个wxml_output.js文件,文件中有一个非常重要的方法$gwx,该方法会返回一个函数。该函数的具体作用我们可以尝试执行一下看看结果。
我们打开渲染层webview搜索一下该方法(为了方便查看,这里会用个小项目来演示)
从这里我们可以看到该方法会传入一个小程序页面的路径,返回的依然是一个函数
var decodeName = decodeURI("./index/index.wxml");
var generateFunc = $gwx(decodeName);
我们尝试按这里流程执行一下$gwx返回的函数,看看返回的内容是什么?
<!--compiler-test/index.wxml-->
<view class="qd_container" >
<text name="title">wxml编译</text>
<view >{{ name }}</view>
</view>
const func = $gwx(decodeURI('index.wxml'))
console.log(func())
没错,这个函数正是用来生成Virtual DOM
编译 wxss
我们同样可以用微信开发者工具中的wcsc来编译一下wxss文件。
(大家认为这里应该是会生成css文件还是js文件呢?)
我们在终端执行一下以下命令来编译 wxss 文件
.\wcsc.exe -js .\test.wxss >> wxss.output.js

相比之前的wcc编译wxml文件来说,这次的编译相对来说比较简单,它主要完成了以下内容:
- rpx 单位的换算,转换成 px
- 提供
setCssToHead方法将转换好的 css 添加到 head 中

微信小程序渲染流程
先来了解渲染层模版
从上面的渲染层webview我们可以找到这两个 webview

第一个index/indexwebview 我们上面说了它就是对应我们的小程序的渲染层,也就是真正的小程序页面。
那么下面这个instanceframe.html是什么呢?
这个 webview 其实是小程序渲染模版,打开查看一番

它其实就是提前注入了一些页面所需要的公共文件,以及红框内的一些页面独立的文件占位符,这些占位符会等小程序对应页面文件编译完成后注入进来。
如何保证代码的注入是在渲染层 webview 的初始化之后执行?
在刚刚渲染模版webview的下方有这样一段脚本:
if (document.readyState === "complete") {
alert("DOCUMENT_READY");
} else {
const fn = () => {
alert("DOCUMENT_READY");
window.removeEventListener("load", fn);
};
window.addEventListener("load", fn);
}
很明显,这里在页面初始化完成后,通过alert来进行通知。此时的native/nw.js会拦截这个alert,从而知道此时的 webview 已经初始化完成。
整体渲染流程
1、打开小程序,创建视图层页的 webview 时,此时会初始化渲染层webview,并且会将该 webview 地址设置为instanceframe.html,也就是我们的渲染层模版
2、然后进入页面/index/index,等instanceframewebview 初始化完成,会将页面index/index编译好的代码注入进来并执行
// 将webview src路径修改为页面路径
history.pushState("", "", "http://127.0.0.1:26444/__pageframe__/index/index");
/*
...
这里还有一些 wx config及wxss编译后的代码
*/
// 这里是
var decodeName = decodeURI("./index/index.wxml");
var generateFunc = $gwx(decodeName);
if (decodeName === "./__wx__/functional-page.wxml") {
generateFunc = function () {
return {
tag: "wx-page",
children: [],
};
};
}
if (generateFunc) {
var CE =
typeof __global === "object"
? window.CustomEvent || __global.CustomEvent
: window.CustomEvent;
document.dispatchEvent(
new CE("generateFuncReady", {
detail: {
generateFunc: generateFunc,
},
})
);
__global.timing.addPoint("PAGEFRAME_GENERATE_FUNC_READY", Date.now());
} else {
document.body.innerText = decodeName + " not found";
console.error(decodeName + " not found");
}
3、此时通过history.pushState方法修改 webview 的 src 但是 webview 并不会发送页面请求,并且将调用$gwx为生成一个generateFun方法,前面我们了解到该方法是用来生成虚拟 dom 的
4、然后会判断该方法存在时,通过document.dispatchEvent 派发发自定义事件generateFuncReady 将 generateFunc 当作参数传递给底层渲染库
5、然后在底层渲染库WAWebview.js中会监听自定义事件generateFuncReady ,然后通过 WeixinJSBridge 通知 JS 逻辑层视图已经准备好()

6、最后 JS 逻辑层将数据给 Webview 渲染层,WAWebview.js在通过virtual dom生成真实 dom 过程中,它会挂载到页面的document.body上,至此一个页面的渲染流程就结束了
小程序和 vue 的区别
整体来讲,小程序身上或多或少都有着 vue 的影子...(模版文件,data,指令,虚拟 dom,生命周期等)
但在数据更新这里,小程序却与 Vue 表现的截然不同。
1.页面更新 DOM 是同步的还是异步的?
2.既然更新 DOM 是个同步的过程,为什么 Vue 中还会有 nextTick 钩子?
mounted() {
this.name = '前端南玖'
console.log('sync',this.$refs.title.innerText) // 旧文案
// 新文案
Promise.resolve().then(() => {
console.log('微任务',this.$refs.title.innerText)
})
setTimeout(() => {
console.log('宏任务',this.$refs.title.innerText)
}, 0)
this.$nextTick(() => {
console.log('nextTick',this.$refs.title.innerText)
})
}

然而小程序却没有这个队列概念,频繁调用,视图会一直更新,阻塞用户交互,引发性能问题。
而 Vue 每次赋值操作并不会直接更新视图,而是缓存到一个数据更新队列中,异步更新,再触发渲染,在同一个tick内多次赋值,也只会渲染一次。
taro 怎样兼容不同的小程序
Taro3 之前版本:
重编译,轻运行。

编译时是使用 babel-parser 将 Taro 代码解析成抽象语法树,然后通过 babel-types 对抽象语法树进行一系列修改、转换操作,最后再通过 babel-generate 生成对应的目标代码。
存在的问题:
1、jsx 语法太灵活,靠编译适配不完。每次 react 新特性更新都需要大量适配工作
2、在通过 ast 各种转换后,不支持 sourcemap 了
Taro3 版本:
Taro 3 则可以大致理解为解释型架构(相对于 Taro 1/2 而言),主要通过在小程序端模拟实现 DOM、BOM API 来让前端框架直接运行在小程序环境中,从而达到小程序和 H5 统一的目的,而对于生命周期、组件库、API、路由等差异,依然可以通过定义统一标准,各端负责各自实现的方式来进行抹平。而正因为 Taro 3 的原理,在 Taro 3 中同时支持 React、Vue 等框架,甚至还支持了 jQuery,还能支持让开发者自定义地去拓展其他框架的支持,比如 Angular,Taro 3 整体架构如下:

taro2.0 和 taro3.0 区别
Taro 1/2
Taro 1/2 属于编译型架构,主要通过对类 React 代码进行语法编译转换地方式,得到各个端可以运行的代码,再配合非常轻量的运行时适配,以及根据标准组件库、API 进行差异抹平,从而实现多端适配的目的,整体架构如下。

而 Taro 1 与 Taro 2 的都是基于这种架构建立的方案,他们之间的区别主要是 Taro 1 在小程序端是自建构建体系,而 Taro 2 则是所有端都采用 Webpack 进行编译,可以降低 Taro 自身编译系统的复杂度,同时能够让开发者使用 Webpack 的生态来自定义编译过程和结果,可以认为 Taro 2 是 Taro 1 和 3 之间的一个过渡性版本。
Taro 3
Taro 3 则可以大致理解为解释型架构(相对于 Taro 1/2 而言),主要通过在小程序端模拟实现 DOM、BOM API 来让前端框架直接运行在小程序环境中,从而达到小程序和 H5 统一的目的,而对于生命周期、组件库、API、路由等差异,我们依然可以通过定义统一标准,各端负责各自实现的方式来进行抹平。而正因为 Taro 3 的原理,所以我们可以在 Taro 3 中同时支持 React、Vue 等框架,甚至我们还支持了 jQuery,在不久的将来我们还能支持让开发自定义地去拓展其他框架的支持,比如 Angular,Taro 3 整体架构如下。

为什么小程序拿不到 dom 相关的 api
Web 开发渲染线程和脚本线程是互斥的,这就是为什么长时间脚本运行可能会导致页面失去响应。开发人员可以使用各种浏览器公开的 DOM API 来选择和操作 DOM。在小程序中,它们是分开的,运行在不同的线程中,而逻辑层运行在 JSCore 中,没有完整的浏览器对象,所以缺少相关的 DOM API 和 BOM API。
说说小程序的三层架构
逻辑层、渲染层、Native 层
Taro 的优化方案
优化更新性能
1、全局配置项 baseLevel
对于不支持模板递归的小程序(微信、QQ、京东小程序),在 DOM 层级达到一定数量后,Taro 会使用原生自定义组件协助递归。
简单理解就是 DOM 结构超过 N 层后,会使用原生自定义组件进行渲染。N 默认是 16 层,可以通过修改配置项 baseLevel 修改 N。
把 baseLevel 设置为 8 甚至 4 层,能非常有效地提升更新时的性能。但是设置是全局性的,会带来若干问题
2、CustomWrapper 组件
为了解决全局配置不灵活的问题,我们增加了一个基础组件 CustomWrapper。它的作用是创建一个原生自定义组件,对后代节点的 setData 将由此自定义组件进行调用,达到局部更新的效果。
开发者可以使用它去包裹遇到更新性能问题的模块,提升更新时的性能。因为 CustomWrapper 组件需要手动使用,开发者能够清楚“这层使用了自定义组件,需要避免自定义组件的两个问题”。
优化初次渲染性能
当初次渲染的数据量非常大时,可能会导致页面白屏一段时间。因此 Taro 提供了预渲染功能来解决此问题。
优化长列表性能
针对长列表的场景,Taro 提供了 VirtualList 组件辅助开发者进行优化。
它只会渲染当前可视区域内的组件,非可视区域的组件将会在用户滚动到可视区域内后再渲染,从而减少实际渲染的组件、优化渲染性能。
跳转预加载
在小程序中,从调用 Taro.navigateTo 等路由跳转 API 后,到小程序页面触发 onLoad 会有一定延时,因此一些网络请求可以提前到发起跳转的前一刻去请求。
Taro 3 提供了 Taro.preload API,可以把需要预加载的内容作为参数传入,然后在新页面加载后通过 Taro.getCurrentInstance().preloadData 获取到预加载的内容。
其他:
编译优化、分包、依赖预加载等。
小程序体积压缩的方案
分包、treeshaking、分析依赖包
小程序页面间有哪些传递数据的方法?
使用全局变量实现数据传递 在 app.js 文件中定义全局变量 globalData, 将需要存储的信息存放在里面
// app.js
App({
// 全局变量
globalData: {
userInfo: null,
},
});
使用的时候,直接使用 getApp() 拿到存储的信息
使用 wx.navigateTo 与 wx.redirectTo 的时候,可以将部分数据放在 url 里面,并在新页面 onLoad 的时候初始化
// Navigate
wx.navigateTo({
url: '../pageD/pageD?name=raymond&gender=male',
})
// Redirect
wx.redirectTo({
url: '../pageD/pageD?name=raymond&gender=male',
})
// pageB.js
...
Page({
onLoad: function(option){
console.log(option.name + 'is' + option.gender)
this.setData({
option: option
})
}
})
需要注意的问题:wx.navigateTo 和 wx.redirectTo 不允许跳转到 tab 所包含的页面 onLoad 只执行一次
使用本地缓存 Storage 相关
小程序的生命周期函数
- onLoad 页面加载时触发。一个页面只会调用一次,可以在 onLoad 的参数中获取打开当前页面路径中的参数
- onShow() 页面显示/切入前台时触发
- onReady() 页面初次渲染完成时触发。一个页面只会调用一次,代表页面已经准备妥当,可以和视图层进行交互
- onHide() 页面隐藏/切入后台时触发。 如 navigateTo 或底部 tab 切换到其他页面,小程序切入后台等
- onUnload() 页面卸载时触发。如 redirectTo 或 navigateBack 到其他页面时
小程序事件绑定
事件绑定的写法同组件的属性,以 key、value 的形式。
key 以 bind 或 catch 开头,然后跟上事件的类型,如 bindtap、catchtouchstart。value 是一个字符串,
需要在对应的 Page 中定义同名的函数。不然当触发事件的时候会报错。
bind 事件绑定不会阻止冒泡事件向上冒泡,catch 事件绑定可以阻止冒泡事件向上冒泡
小程序的双向绑定和 vue 的异同
大体相同,但小程序直接 this.data 的属性是不可以同步到视图的,必须调用 this.setData()方法!
生命周期不一样,微信小程序生命周期比较简单
数据绑定也不同,微信小程序数据绑定需要使用{{}},vue 直接:就可以
显示与隐藏元素,vue中,使用 v-if 和 v-show 控制元素的显示和隐藏,小程序中,使用wx-if 和hidden 控制元素的显示和隐藏
事件处理不同,小程序中,全用 bindtap(bind+event),或者 catchtap(catch+event) 绑定事件,vue:使用 v-on:event 绑定事件,或者使用@event 绑定事件
数据双向绑定也不也不一样在 vue中,只需要再表单元素上加上 v-model,然后再绑定 data中对应的一个值,当表单元素内容发生变化时,data中对应的值也会相应改变,这是 vue非常 nice 的一点。微信小程序必须获取到表单元素,改变的值,然后再把值赋给一个 data中声明的变量。
微信小程序中的 js 运行环境和浏览器 js 的运行环境有什么不同?
微信小程序 js 运行环境是 jsCore 中,没有 window 和 document 对象
工程化
webpack:
webpack 原理
webpack 热更新原理
webpack plugin 和 loader 区别
plugin 用来增强功能,loader 用来对编译的代码进行转换
webpack 构建的优化手段
- 提高优化速度
- 压缩打包文件的大小
- 改善用户体验。
1、多线程可以提高程序的效率,我们也可以在 Webpack 中使用。而 thread-loader 是一个可以在 Webpack 中启用多线程的加载器。
2、在我们的项目开发过程中,Webpack 需要多次构建项目。为了加快后续构建,我们可以使用缓存,与缓存相关的加载器是缓存加载器。
3、当我们在项目中修改一个文件时,Webpack 默认会重新构建整个项目,但这并不是必须的。我们只需要重新编译这个文件,效率更高,这种策略称为 Hot update。Webpack 内置了 Hot update 插件,我们只需要在配置中开启 Hot update 即可。
4、在我们的项目中,一些文件和文件夹永远不需要参与构建。所以我们可以在配置文件中指定这些文件,防止 Webpack 取回它们,从而提高编译效率。
5、css-minimizer-webpack-plugin 可以压缩和去重 CSS 代码。
6、terser-webpack-plugin 可以压缩和去重 JavaScript 代码。
7、tree-shaking 就是:只编译实际用到的代码,不编译项目中没有用到的代码。
Webpack5 中,默认情况下会启用 tree-shaking。我们只需要确保在最终编译时使用生产模式。
8、当我们的代码出现 bug 时,source-map 可以帮助我们快速定位到源代码的位置。但是这个文件很大。
为了平衡性能和准确性,我们应该:在开发模式下生成更准确(但更大)的 source-map;在生产模式下生成更小(但不那么准确)的源映射。
9、我们可以使用 webpack-bundle-analyzer 来查看打包后的 bundle 文件的体积,然后进行相应的体积优化。
10、如果模块没有延迟加载,整个项目的代码会被打包成一个 js 文件,导致单个 js 文件体积非常大。那么当用户请求网页时,首屏的加载时间会更长。
使用模块来加载后,大 js 文件会被分割成多个小 js 文件,加载时网页按需加载,大大提高了首屏的加载速度。
11、Gzip 是一种常用的文件压缩算法,可以提高传输效率。但是,此功能需要后端配合。
12、对于一些小图片,可以转成 base64 编码,这样可以减少用户的 HTTP 请求次数,提升用户体验。url-loader 在 webpack5 中已被弃用,我们可以使用 assets-module 代替。
13、我们可以将哈希添加到捆绑文件中,这样可以更轻松地处理缓存。
webpack 和 vite 区别
简单对 Webpack 和 Vite 进行一个对比:
Webpack
- 支持的模块规范:ES Modules,CommonJS 和 AMD Modules;
- Dev Server:通过
webpack-dev-server托管打包好的模块; - 生产环境构建:webpack
Vite
- 支持的模块规范:ES Modules;
- Dev Server:原生 ES Modules;
- 生产环境构建:Rollup
总结
由于浏览器原生 ES Modules 的支持,当浏览器发出请求时,Vite 可以在不将源码打包为一个 Bundle 文件的情况下,将源码文件转化为 ES Modules 文件之后返回给浏览器。这样 Vite 的应用启动和热更新 HMR 时的速度都不会随着应用规模的增加而变慢。
为什么 vite 构建更快
基于 ES Module,不会打包全部文件,而死按需将 ESmoduel 源码提供给浏览器,让浏览器分担一部分打包工作。
webpack5 和 webpack4 的区别
1、webpack5 自动开启 treeshaking(treeshaking 只支持 esmodule,不支持 commonjs)
2、压缩代码,webpack4 需要安装 terser-webpack-plugin,weboack5 内置了压缩
3、webpack 4 加载资源需要用不同的 loader,webpack5 的 asset 模块类型替换 loader
- asset/resource 替换 file-loader(发送单独文件)
- asset/inline 替换 url-loader (导出 url)
- asset/source 替换 raw-loader(导出源代码)
- 。。。
4、webpack4 通过 webpack-dev-server 启动服务,webpack5 启动服务内置使用 webpack serve 启动
5、模块联邦,webpack 可以实现 应用程序和应用程序之间的引用。
https://webpack.docschina.org/blog/2020-10-10-webpack-5-release/#new-plugin-order
webpack hash 策略
指纹文件策略一共有三种,hash、chunkhash、contenthash
hash 策略
hash 策略只要文件改变,那么所有的文件都会发生改变。也就是重新打包
chunkhash 策略
chunkhash 策略只和相对用的 chunk 相关,一个 chunk 的改变并不会对其他 chunk 文件进行重新打包。也就是所谓的关联文件
contenthash 策略
contenthash 只已自己的文件为单位,并不影响其他文件的打包
webpack5 模块联邦是什么
webpack 执行过程
手动实现一个 loader
const var2const = function (source) {
return source.replace(/var/g, "const");
};
module.exports = var2const;
手动实现一个 plugin
// https://segmentfault.com/a/1190000021214520
const ConcatSource = require("webpack-sources").ConcatSource;
class CopyrightPlugin {
constructor(text) {
this.copyright = this.wrapText(text || "");
}
wrapText = (str) => {
if (!str.includes("\n")) return `/*! ${str} */`;
return `/*!\n * ${str.split("\n").join("\n * ")}\n */`;
};
// 注册插件函数
apply(compiler) {
compiler.hooks.compilation.tap("CopyrightPlugin", (compilation) => {
// console.log("CopyrightPlugin", compilation);
compilation.hooks.optimizeChunkAssets.tap("CopyrightPlugin", (chunks) => {
for (const chunk of chunks) {
for (const file of chunk.files) {
compilation.updateAsset(
file,
(old) => new ConcatSource(old, "\n", this.copyright)
);
}
}
});
});
}
}
module.exports = CopyrightPlugin;
什么是 tree shaking?工作流程是什么
Tree-Shaking 因 rollup.js 而普及,简单来说,Tree-Shaking 是指擦除那些不会执行的代码,webpack 也支持 Tree-Shaking。
我们知道,只要是被写进项目的代码,都会经过 http 请求返回到浏览器端,如果一些被引入项目的代码都不会被执行,那么这些代码就白白占用了项目的打包体积,打包体积大,http 请求的速度也会减慢,页面的性能也会受到影响。
Tree-Shaking 就可以把项目中没有使用的代码(dead code)擦除掉,举个例子,Vue 内部内置了很多组件,例如 <Transition>,如果我们的项目中根本就没有用到该组件,就会被 Tree-Shaking 自动忽略掉,它的代码不会被打包到项目最终的构建资源中。
想要实现 Tree-Shaking,必须满足一个条件,即模块必须是 ESM(ES Module),因为 Tree-Shaking 依赖 ESM 的静态结构。
webpack 打包后的代码实际是怎么运行起来的
首先 minifest.js 会定义一个 webpackJsonp 方法,待其他打包后的文件(也可称为 chunk)调用。当调用 chunk 时,会先将该 chunk 中所有的 moreModules, 也就是每一个依赖的文件也可称为 module (如 test.js)存起来。之后通过 executeModules 判断这个文件是不是入口文件,决定是否执行第一次 webpack_require。而 webpack_require 的作用,就是根据这个 module 所 require 的东西,不断递归调用 webpack_require,webpack_require函数返回值后供 require 使用。当然,模块是不会重复加载的,因为 installedModules 记录着 module 调用后的 exports 的值,只要命中缓存,就返回对应的值而不会再次调用 module。webpack 打包后的文件,就是通过一个个函数隔离 module 的作用域,以达到不互相污染的目的。
babel:
babel 原理
Babel 的工作过程主要分为三个阶段:解析(Parsing)、转换(Transforming)和生成(Generation)。
- 解析:Babel 首先将源代码解析成抽象语法树(AST)。AST 是一种树状的数据结构,用于表示源代码的结构。解析过程通常包括两个子阶段:词法分析(将源代码分解成词法单元/标记)和语法分析(根据词法单元构建 AST)。
- 转换:在转换阶段,Babel 对 AST 进行修改,以实现新特性的向后兼容。这是通过应用一系列插件来完成的,每个插件都负责处理一个特定的语言特性。插件可以对 AST 进行修改、添加或删除节点。
- 生成:在生成阶段,Babel 将经过转换的 AST 转换回源代码。这个过程也称为代码生成,通常会考虑代码的格式和缩进等样式。
AST 原理
AST 抽象语法树就是对源代码的抽象语法结构的树状表现形式。
在不同的场景下,会有不同的解析器将源码解析成抽象语法树。
let answer = 2 * 3;转换后为:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "answer"
},
"init": {
"type": "BinaryExpression",
"operator": "*",
"left": {
"type": "Literal",
"value": 2,
"raw": "2"
},
"right": {
"type": "Literal",
"value": 3,
"raw": "3"
}
}
}
],
"kind": "let"
}
],
"sourceType": "script"
}
AST 是如何生成的
AST 是通过 JS Parser (解析器),将 js 源码转化为抽象语法树,主要分为两步
- 分词
将整个的代码字符串,分割成语法单元数组(token)。 JS 中的语法单元(token)指标识符(function,return),运算符,括号,数字,字符串等能解析的最小单元。主要有以下几种:
- 标识符 没有被引号括起来的连续字符,可以包含字母、数字、_、$,其中数字不能作为开头。 标识符可能是 var,return,function 等关键字,也可能是 true,false 这样的内置常量,或是一个变量。具体是哪种语义,分词阶段不区分,只要正确拆分即可。
- 数字 十六进制,十进制,八进制以及科学表达式等都是最小单元
- 运算符: +、-、 *、/ 等
- 字符串 对计算机而言,字符串只会参与计算和展示,具体里面细分没必要分析
- 注释 不管是行注释还是块注释,对于计算机来说并不关心其内容,所以可以作为不可再拆分的最小单元
- 空格 连续的空格,换行,缩进等,只要不在字符串中都没有实际的逻辑意义,所以连续的空格可以作为一个语法单元。
- 其他,大括号,中括号,小括号,冒号 等等。
依然拿上面的代码作为例子,分词后生成的语法单元数组如下
[
{
type: "Keyword",
value: "var",
range: [0, 3],
},
{
type: "Identifier",
value: "answer",
range: [4, 10],
},
{
type: "Punctuator",
value: "=",
range: [11, 12],
},
{
type: "Numeric",
value: "2",
range: [13, 14],
},
{
type: "Punctuator",
value: "*",
range: [15, 16],
},
{
type: "Numeric",
value: "3",
range: [17, 18],
},
{
type: "Punctuator",
value: ";",
range: [18, 19],
},
];
- 语义分析
语义分析的目的是将分词得到的语法单元进行一个整体的组合,分析确定语法单元之间的关系。
简单来说,语义分析可以理解成对语句(statement)和表达式(expression)的识别。
- 语句,一个具备边界的代码区域。相邻的两个语句之间从语法上讲互不影响。比如:
var a = 1; if(xxx){xxx} - 表达式,指最终会有一个结果的一小段代码,它可以嵌入到另一个表达式中,且包含在表达式中。比如:
a++,i > 0 && i< 6
语义分析是一个递归的过程,它会将分词分析出来的数组转化成树形的表达形式。同时,会验证语法,语法如果存在错误的话,会抛出语法错误。
AST 的具体应用
文章一开始就说到了,babel,webpack,css 预处理,eslint 等都应用到了 AST 树,那么 AST 到底做了一个什么样的角色呢!? 下面我们就来看一下。
首先看一下 babel 工作原理的实现。
- babel 实现原理
babel 是一个 javascript 编译器,用来将 es6 语法编译成 es5
babel 的工作可以分为 3 个阶段:
第 1 步 解析(Parse):通过解析器 babylon 将代码解析成抽象语法树
第 2 步 转换(TransForm): 通过 babel-traverse plugin 对抽象语法树进行深度优先遍历,遇到需要转换的,就直接在 AST 对象上对节点进行添加、更新及移除操作,比如遇到箭头函数,就转换成普通函数,最后得到新的 AST 树。
第 3 步 生成(Generate): 通过 babel-generator 将 AST 树生成 es5 代码
- vue 模板编译过程
Vue 提供了 2 个版本,一个是 Runtime + Compiler ,另一个是 Runtime only 的,前者是包含编译代码的,会把编译的过程放在运行时做,后者是不包含编译代码的,需要借助 webpack 的 vue-loader 把模板编译 render 函数。不管使用哪个版本,都有一个环节,就是将模板编译成 render 函数。
下面我们分析下 vue 模板的编译过程,这也是 vue 源码实现中非常重要的一个模块。 vue 模板的编译过程分为 3 个阶段
第 1 步 解析(Parse)
const ast = parse(template.trim(), options)
将模板字符串解析生成 AST,这里的解析器是 vue 自己实现的,解析过程中会使用正则表达式对模板顺序解析,当解析到开始标签、闭合标签、文本的时候都会有相对应的回调函数执行,来达到构造 AST 树的目的。
生成的 AST 元素节点总共有 3 种类型,1 为普通元素, 2 为表达式,3 为纯文本。下面看一个例子
<ul :class="bindCls" class="list" v-if="isShow">
<li v-for="(item,index) in data" @click="clickItem(index)">{{item}}:{{index}}</li>
</ul>
上面模板解析生成的 AST 树如下:
ast = {
'type': 1,
'tag': 'ul',
'attrsList': [],
'attrsMap': {
':class': 'bindCls',
'class': 'list',
'v-if': 'isShow'
},
'if': 'isShow',
'ifConditions': [{
'exp': 'isShow',
'block': // ul ast element
}],
'parent': undefined,
'plain': false,
'staticClass': 'list',
'classBinding': 'bindCls',
'children': [{
'type': 1,
'tag': 'li',
'attrsList': [{
'name': '@click',
'value': 'clickItem(index)'
}],
'attrsMap': {
'@click': 'clickItem(index)',
'v-for': '(item,index) in data'
},
'parent': // ul ast element
'plain': false,
'events': {
'click': {
'value': 'clickItem(index)'
}
},
'hasBindings': true,
'for': 'data',
'alias': 'item',
'iterator1': 'index',
'children': [
'type': 2,
'expression': '_s(item)+":"+_s(index)'
'text': '{{item}}:{{index}}',
'tokens': [
{'@binding':'item'},
':',
{'@binding':'index'}
]
]
}]
}
第 2 步 优化语法树(Optimize)
optimize(ast, options)
vue 模板中并不是所有数据都是响应式的,有很多数据是首次渲染后就永远不会变化的,那么这部分数据生成的 DOM 也不会变化,我们可以在 patch 的过程跳过对他们的比对。 此阶段会深度遍历生成的 AST 树,检测它的每一颗子树是不是静态节点,如果是静态节点则它们生成 DOM 永远不需要改变,这对运行时对模板的更新起到极大的优化作用。
遍历过程中,会对整个 AST 树中的每一个 AST 元素节点标记 static 和 staticRoot(递归该节点的所有 children,一旦子节点有不是 static 的情况,则为 false,否则为 true)。
经过该阶段,上面例子中的 ast 会变成
ast = {
'type': 1,
'tag': 'ul',
'attrsList': [],
'attrsMap': {
':class': 'bindCls',
'class': 'list',
'v-if': 'isShow'
},
'if': 'isShow',
'ifConditions': [{
'exp': 'isShow',
'block': // ul ast element
}],
'parent': undefined,
'plain': false,
'staticClass': 'list',
'classBinding': 'bindCls',
'static': false,
'staticRoot': false,
'children': [{
'type': 1,
'tag': 'li',
'attrsList': [{
'name': '@click',
'value': 'clickItem(index)'
}],
'attrsMap': {
'@click': 'clickItem(index)',
'v-for': '(item,index) in data'
},
'parent': // ul ast element
'plain': false,
'events': {
'click': {
'value': 'clickItem(index)'
}
},
'hasBindings': true,
'for': 'data',
'alias': 'item',
'iterator1': 'index',
'static': false,
'staticRoot': false,
'children': [
'type': 2,
'expression': '_s(item)+":"+_s(index)'
'text': '{{item}}:{{index}}',
'tokens': [
{'@binding':'item'},
':',
{'@binding':'index'}
],
'static': false
]
}]
}
第 3 步 生成代码
const code = generate(ast, options)
通过 generate 方法,将 ast 生成 render 函数
with (this) {
return isShow
? _c(
"ul",
{
staticClass: "list",
class: bindCls,
},
_l(data, function (item, index) {
return _c(
"li",
{
on: {
click: function ($event) {
clickItem(index);
},
},
},
[_v(_s(item) + ":" + _s(index))]
);
})
)
: _e();
}
- Prettier 实现原理
通过上面对 babel 实现原理和 vue 模板的编译原理可以看出,他们的实现有很多相同之处,都是先将源码解析成 AST 树,然后对 AST 树就行处理,最后生成想要的东西。
Prettier 的实现同样是这样,首先依然是将代码解析生成 AST 树,然后是对 AST 遍历,调整长句,整理空格,括号等,最后输出代码,这里就不赘述了。
小结
我们分析了 Babel 原理、vue 模板编译过程、Prettier 原理,这里我们简单总结一下。
如果把源码比作一个机器,那么分词过程就是将这台机器拆分成一个个零件,语义分析过程就是分析每个零件的位置以及作用,然后根据需要对零件进行加工处理,最后再组装成一个新的机器。
AST 还能做什么
那么工作中我们能使用 AST 做些什么呢?!
这里就要发挥想象了,看看我们日常工作中有什么需求是可以通过 AST 开发个工具来解决。
比如,可以通过 AST 可以将代码自动转成流程图;
或者根据自定义的注释规范,通过工具自动生成文档;
或是通过工具自动生成骨架屏文件。
手动实现一个 babel 插件
var babel = require("babel-core");
var t = require("babel-types");
const visitor = {
BinaryExpression(path) {
const node = path.node;
let result;
// 判断表达式两边,是否都是数字
if (t.isNumericLiteral(node.left) && t.isNumericLiteral(node.right)) {
// 根据不同的操作符作运算
switch (node.operator) {
case "+":
result = node.left.value + node.right.value;
break;
case "-":
result = node.left.value - node.right.value;
break;
case "*":
result = node.left.value * node.right.value;
break;
case "/":
result = node.left.value / node.right.value;
break;
case "**":
let i = node.right.value;
while (--i) {
result = result || node.left.value;
result = result * node.left.value;
}
break;
default:
}
}
// 如果上面的运算有结果的话
if (result !== undefined) {
// 把表达式节点替换成number字面量
path.replaceWith(t.numericLiteral(result));
let parentPath = path.parentPath;
// 向上遍历父级节点
parentPath && visitor.BinaryExpression.call(this, parentPath);
}
},
};
module.exports = function (babel) {
return {
visitor,
};
};
插件写好了,我们运行下插件试试
const babel = require("babel-core");
const result = babel.transform("const result = 1 + 2;", {
plugins: [require("./index")],
});
console.log(result.code); // const result = 3;
npm 执行机制,npm run 执行过程
commonjs amd cmd umd esmodule 区别
网络 HTTP
UDP 和 TCP 区别
https://mp.weixin.qq.com/s/3QM0rIVhD87buHgV__Ng3g
TCP(Transmission Control Protocol)和 UDP(User Datagram Protocol)是两种常用的传输层协议,它们有以下的区别:
1、连接方面:TCP 是面向连接的协议,而 UDP 是无连接的协议。在 TCP 中,发送方和接收方必须先建立连接,然后才能传输数据。UDP 则不需要建立连接,直接发送数据即可。
2、可靠性:TCP 保证数据传输的可靠性,通过序列号、确认应答和重传机制等方式来保证数据的完整性和正确性。UDP 则不保证数据传输的可靠性,因为它不提供确认和重传机制。
3、传输速度:因为 TCP 要保证数据传输的可靠性,所以在传输速度方面相对较慢。而 UDP 则不需要进行复杂的传输控制,因此传输速度更快。
4、传输内容:TCP 是一种面向字节流的协议,将数据看作是一连串的字节流,没有明确的消息边界。UDP 则是面向报文的协议,将数据看作是一系列的报文,每个报文是一个独立的单元,具有明确的消息边界。
基于以上的特点,TCP 和 UDP 适用于不同的场景。TCP 适用于对传输可靠性要求比较高的场景,例如网页浏览、文件传输、邮件等。而 UDP 则适用于对传输可靠性要求较低、传输速度要求较高的场景,例如在线游戏、视频直播等。
TCP 和 UDP 是计算机网络中两种常用的传输层协议,用于实现可靠传输和无连接传输。
TCP(Transmission Control Protocol)是一种面向连接的、可靠的传输协议。它通过三次握手四次挥手进行连接和断开链接,保证数据的可靠性、完整性和顺序性,具有较高的传输效率。
TCP 协议适用于要求可靠传输的场景,如文件传输、电子邮件传输等。
TCP 协议的工作流程如下:
- 客户端向服务器发送连接请求(
SYN)。 - 服务器收到连接请求后,回复确认请求(
SYN+ACK)。 - 客户端收到确认请求后,回复确认(
ACK),完成连接。 - 数据传输完成后,客户端和服务器分别发送关闭连接请求(
FIN)。 - 对方收到关闭请求后,回复确认(
ACK)。 - 双方都收到对方的关闭请求和确认后,关闭连接。
UDP(User Datagram Protocol)是一种无连接的、不可靠的传输协议。它不需要建立连接和维护连接状态,具有较高的传输速度和实时性,但不保证数据的完整性和顺序性。
UDP 协议适用于实时性要求高、数据量小、丢失数据不会影响结果的场景,如视频直播、语音通话等。 UDP 协议工作流程:
- 客户端向服务器发送数据报。
- 服务器收到数据报后,直接处理数据并回复确认。
- 客户端收到确认后,继续发送下一个数据报。
- 如果数据报丢失或损坏,客户端不会重传,而是直接忽略。
两者的区别主要如下:
- 连接方式:TCP 是面向连接的协议,UDP 是无连接的协议。
- 可靠性:TCP 提供可靠的传输,保证数据的完整性和顺序性,而 UDP 不保证数据的完整性和顺序性。
- 速度:UDP 比 TCP 更快,因为它不需要建立连接和维护连接状态。
- 传输方式:TCP 是基于字节流的传输方式,UDP 是基于数据报的传输方式。

针对于 TCP 的特点,其应用场景主要有:
- 文件传输:通过 TCP 协议传输文件时,确保文件的完整性和安全性;
- 邮件传输:通过 TCP 协议传输邮件时,确保邮件的完整性和可靠性;
- 网页浏览:通过 TCP 协议传输网页时,确保网页的完整性和正确性;
针对 UDP 的特点,其应用场景主要有:
- 视频流传输:通过 UDP 协议传输视频流时,要求实时性高,允许数据的丢失和重复。
- 语音通话:通过 UDP 协议传输语音时,要求实时性高,允许数据的丢失和重复。
- 游戏应用:通过 UDP 协议传输游戏数据时,要求实时性高,允许数据的丢失和重复。
5 层网络模型、4 层网络模型和 7 层网络模型是什么
5 层网络模型(TCP/IP)
应用层---》传输层---》网络层---》数据链路层---》物理层
4 层网络模型
应用层---》传输层---》网络层---》数据链路层
7 层网络模型(OSI)
应用层---》表示层---》会话层---》传输层---》网络层---》数据链路层---》物理层

有时候我们会在网上看到有四层网络模型、五层网络模型还有七层网络模型,那到底有几层?最早开始的时候只有四层网络模型,分别是:应用层、传输层、网络层以及物理链路层,这四层模型几乎全世界各个机构都是认可这套模型的,后来有个专门搞标准的组织叫 OSI,作为一个标准组织自然有自己的傲气,又搞出来一个七层模型,分别是应用层、表示层、会话层、传输层、网络层、物理链路层以及物理层。这七层模型实际上只存在一些教科书资料中,实际上并没有啥应用,大家认可这个有这个七层模型,毕竟是标准组织,得给点面子,有点像那个叫好但没行动,后来受到七层网络模型的启发又形成了五层模型:应用层、传输层、网络层、物理链路层、物理层,五层模型只是把四层模型的数据链路层细分出来一个物理层,其实分不分都是要做这些事情的,没什么区别的
分别解释一下五层网络模型
应用层
所谓的应用层就是说我们在互联网应用的过程中产生特定的应用需求,比如上网访问网页的过程中如何跟服务器进行交互。如果用老默送鱼的例子解释,老默和强哥相当于两个软件,老默送鱼的过程就好像是两个软件之间的通信。这些软件应用就被成为应用层。
应用层有很多的协议,比如:HTTP协议、FTP协议(文件传输)、DNS协议(域名解析)、SMTP协议(邮件传输),这些协议类似于包装层的方案选择什么来装鱼,黑色袋子、麻袋、还是揣兜里,用于处理不同的场景,当我们访问网页的时候,就会用到 HTTP 协议,规定了请求头-请求体,响应的时候有响应头+响应体。HTTP 协议还有一个安全版本是HTTPS协议,这两个协议本质上都是用相同的方式获取对象,只不过 HTTPS 实际上是在一个称为TLS(Transport Layer Security,传输层安全)的安全协议上使用 HTTP。
应用层我理解就是软件部分开发者可以直接操作的部分,主要用来通过不同协议实现不同应用功能
传输层
传输层主要是保证消息的可靠传递,当强哥发消息告诉老默:我想吃鱼了,老默立马心领神会,知道该干嘛了,那如果强哥发的是:老默我想吃鱼了,结果老默收到的是:老默我想吃__了,少了个“鱼”字,老默是不是很懵逼,百思不得其解,这种情况在网络中我们称为“丢包”。
传输层也有相关的协议,比如:TCP协议,UDP协议,TCP协议(Transmission Control Protocol,传输控制协议)就是处理可靠传输的,保证数据的正确性,只要使用这个协议,那双方的数据永远不可能错乱,多个字或者少个字的情况。而UDP协议(User Datagram Protocol,用户数据报协议)并不是解决可靠传递的,这个协议只管发送数据,至于数据能不能送到,双手插兜无所谓。
区分到底用什么来传输这些消息,对消息传递的可靠稳定是否有什么特定需求等
网络层
通过应用层和传输层,我们拿到了“信息”,也保证了信息的可靠传递,接下来的问题就是这些信息传输给谁呢?这就是网络层要做的事情,如何在茫茫互联网找到对的人?老默要送鱼,起码得知道强哥住在哪里吧,不然怎么送呢!而且送鱼路线是有多条的,走哪一条最近也是网络层需要解决的事情
网络层的协议代表就是IP协议(Internet Protocol),网络层会接收到来自传输层的“数据”,然后将这些数据拆分很多片段,主要是为了方便 IP 数据包的发送,理论上每个数据包最多可以存储 64KB,但实际上数据包不超过 1500 个字节,IP 路由器会转发每一个数据包,沿着一条路径从一台路由器传递到下一台路由器,直到达到目的地,然后会在网络层重组,这里的网络层指的是快到强哥家的时候,因为数据是有一个封装和解封装的过程。
网络层主要就是用来找门牌号的,上面两层确定了数据(消息怎么发、怎么传输),接下来要确定找到接受数据的目的地地址
数据链路层
数据链路层需要做的就是如何在子网中找到对方?可能有的小伙伴就要问了,网络层不也是在茫茫人海找人嘛,这两者有什么不一样呢?网络层协议的代表就是IP协议,我举个例子,我们在公众号留言的时候,会出现 IP 地址,告诉我们这个人来自哪个省,以前是没有的
那问题来了,我们光凭这个 IP 地址能否找到这个人?他用的是哪一台电脑?不用想,答案是否定的,所以这时候数据链路层来了,它就是帮助我们找到这个人的手段
数据链路层的代表就是MAC协议(medium access control,介质访问控制),也就是我们常说的 MAC 地址,苹果电脑可以通过ifconfig查询,windows 通过ipconfig查询,MAC 地址是跟网卡绑定在一起的,全球唯一
👉IP地址和MAC地址区别:
MAC 地址相当于我们的身份证号,无论我们在哪个城市,它都是唯一不变的,而 IP 地址换个城市就会变,当前在北京就是北京,广东就是在广东,IP 地址只是在同一个网络环境下是唯一的
主要用来确定门牌号,上面网络层找到了小区,但是还没确定门牌号,通过数据链路层的 MAC 地址,才最终确定了门牌号,找到了最后的地址
物理层
到了这一步之后,老默的鱼准备好了,也能保证了可靠的运送,强哥地址也有了,万事俱备就开始配送了,配送方式也有很多,飞船、火箭、白色货车都可以,但是在计算机里只有二进制数据,二进制数据可以用光纤、双绞线、同轴电缆、电力线等等,像这些传输的介质我们一般称为导向的传输介质,因为信号传输都是沿着物理电缆的路径而有导向的
完事准备好了,最后就是屋里设备层面的传输了
TCP/IP 包含了五层(或四层)模型,从上层往下层分别是:
应用层:负责应用程序间的数据通讯。(HTTP/FTP/SMTP/DNS)
传输层:负责两台主机之间的数据传输。(TCP/UDP)
网络层:负责网络地址的管理和路由选择。(TP)
数据链路层:负责设备之间的数据帧的传送和识别。(MAC)
物理层(可选):负责数据和信号间的转换。
分层的主要好处有:
1、各层之间是独立的,每一层向上和向下通过层间接口提供服务,无需暴露内部实现
2、灵活性好
3、结构上可分割
4、易于实现和维护
5、能促进标准化工作
说说网络的五层模型
从上到下分别为:应用层、传输层、网络层、数据链路层、物理层。在发送消息时,消息从上到下进行打包,每一层会在上一层基础上加包,而接受消息时,从下到上进行解包,最终得到原始信息。
其中:
- 应用层主要面向互联网中的应用场景,比如网页、邮件、文件中心等等,它的代表协议有 http、smtp、pop3、ftp、DNS 等等
- 传输层主要面向传输过程,比如 TCP 协议是为了保证可靠的传输,而 UDP 协议则是一种无连接的广播,它们提供了不同的传输方式
- 网络层主要解决如何定位目标的问题,比如 IP、ICMP、ARP 等等
- 数据链路层的作用是将数据可靠的传输到目标,比如常见的以太网协议、P2P 协议
- 物理层是要规范网络两端使用的物理设备,比如蓝牙、wifi、光纤、网线接头等等
HTTP 0.9,1.0,1.1,2.0,2.1,3.0 之间的区别
Http 0.9:
- 只能支持 get 请求, 由于不支持其他请求方式, 所以不能向服务端传输太多信息
- 没有请求头概念, 服务端也只能返回 html 字符串
- 服务端响应后, 会自己断开连接
HTTP0.9 具有典型的无状态、无连接特性。
Http1.0:
现在应用最广泛的一个版本,是无状态、无连接的应用层协议。相比于 0.9:
- 增加了 POST、HEAD 等请求方法
- 增加了请求头(request Header), 响应头(response Header)等概念。引入头部信息,除了要传输的数据外,每次通信都包含头信息、用来描述一些信息
- 传输数据不再局限于 HTML 格式,可以根据 content-type 支持多种数据格式。这样使得互联网不仅可以传输文字,也可以传输图像、视频音频等二进制文件
- 引入 cache 缓存机制
- 引入状态码
HTTP/1.0规定客户端与服务器之间保持短暂的连接,每个 TCP 连接只能发送一个请求,当服务器响应后就会关闭这个 TCP 连接,下一次请求需要再次建立 TCP 连接。TCP 连接建立的成本很高,因为需要客户端和服务器端进行三次握手。因此当一个网页需要发送多个 HTTP 请求时,就会造成性能问题。
其次就是队头阻塞。由于HTTP/1.0规定下一个请求必须在前一个请求响应到达之前才能发送,若前一个请求响应一直不到达,那下一个请求就不发送,同样后面的请求也被阻塞了。
缺陷:
- 无状态: 服务器不跟踪不记录请求过的状态: 可以借助 cookie/session 机制做身份认证和状态记录
- 无连接:
- 无法复用连接, 每次都需要进行三次握手, 四次挥手, 浪费网络资源
- 队头阻塞: HTTP1.0 规定, 在前一个响应完成后, 下一次请求才能发出, 如果前一个阻塞, 后面的请求也阻塞了
为解决这些问题,HTTP/1.1出现了
HTTP 1.1:
为了解决 1.0 短连接造成的性能开销,1.1 引入了持久连接
- 引入持久连接(即长连接) 。可以通过设置
connection: keep-alive来保持 HTTP 连接不断开。避免了每次客户端与服务器端请求都要重复建立释放连接,一个 TCP 连接可以被多个请求复用,提高了网络的利用率。客户端和服务器端发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求是,发送connection: false来明确要求服务器关闭 TCP 连接。

- 加入管道机制。基于
HTTP/1.1的长链接,在同一个 TCP 连接里,允许多个请求同时发送,使得请求管道化成为可能。管道化使得请求能够“并行“传输。
举个例子,假设客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里,先发送 A 请求,然后等待服务做出响应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求,但服务器还是按照请求顺序,先响应 A 请求,再响应 B 请求,所以这并不是真正意义上的并行传输。现阶段的浏览器厂商实现并行传输,采用的做法是允许我们打开多个 TCP 会话,这就是我们所熟悉的浏览器对同一个域下能够并行加载 6~8 个资源的限制。

Content-length字段。因为现在一个 TCP 连接可以传送多个回应,那么就要有一种机制,来区分数据包是属于哪一个回应的,这就是Content-length字段的作用,用来声明本次回应的数据长度。- 分块传输编码。使用
Content-length字段的前提条件是,服务器发送响应之前,必须知道响应的数据长度。对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用“流模式”(stream),取代“缓存模式”(buffer)。因此,1.1 版本规定可以不是使用Content-Length字段,而使用“分块传输编码”(chunk transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明响应将由数量未定的数据块组成。Transfer-Encoding: chunked // 分块传输 - 新增了请求方式PUT、PATCH、OPTIONS、DELETE等。
- 增加 cache 缓存策略,如 cache-control,Etag、If-Unmodified-Since、If-Match、If-None-Match 等可供选择的了缓存头来控制缓存策略。
- 客户端请求的头信息新增了 Host 字段,用来指定服务器的域名。
HTTP/1.1支持文件断点续传,RANGE:bytes,HTTP/1.0 每次传送文件都是从文件头开始,即 0 字节处开始。RANGE:bytes=XXXX表示要求服务器从文件 XXXX 字节处开始传送,断点续传。即返回码是 206(Partial Content)
缺点:虽然发送请求时不会阻塞, 但是响应时, 依旧是按顺序返回, 无法解决队头阻塞问题
Http2.0:
- 二进制分帧:
HTTP/1.1版本的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制,HTTP/2.0则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为“帧”(frame):头信息帧和数据帧。那么如何在不改动 HTTP/1.1 的语义、方法、状态码、URI 以及首部字段等请情况下,将 HTTP/1.1 过渡到 HTTP/2.0 呢?关键之一就在于在应用层(HTTP/2.0)和传输层(TCP or UDP)之间增加一个二进制分帧层。在二进制分帧层中,HTTP/2.0 会将所有传输的信息分割为更小的信息并封装在帧中,并对他们采用二进制格式的编码。

多路复用(连接共享) :HTTP/2.0版本会复用 TCP 连接。在一个连接里,客户端和服务器端都可以同时发送多个请求或响应,而且不用按照顺序一一对应,这样就避免了“队头阻塞”。
下面是几个概念:
- 流(stream):已建立连接上的双向字节流。
- 消息:与逻辑消息对应的完整的一系列数据帧。
- 帧(frame):
HTTP/2.0通信的最小单位,每个帧包含帧头部,至少会标识出当前帧所属的流(stream id)。下面是帧的结构:

帧的字节中保存了不同的信息,前 9 个字节对于每个帧都是一致的,服务器解析 HTTP/2.0 的数据帧时,只需要解析这些字节,就能准确的指导整个镇期望多少字节数来进行处理信息,先了解一下帧中每个字段所代表的信息:
| 名称 | 长度 | 描述 |
|---|---|---|
| Length | 3 字节 | 表示帧负载的长度,默认最大帧大小 2^14 |
| Type | 1 字节 | 当前帧的类型,下面会做介绍 |
| Flags | 1 字节 | 具体帧的标识 |
| R | 1 字节 | 保留位,不需要设置,否则可能带来严重后果 |
| Stream Identifier | 31 位 | 每个流的唯一 ID |
| Frame Payload | 3 字节 | 真实帧的长度,真实长度在 Length 中设置 |
下面是 HTTP/2.0 数据传输图示:

从图中可见,所有的HTTP/2.0通信都在一个 TCP 连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一个或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的stream id标识符来重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识当前帧所属的数据流,不同属的帧可以在连接中混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求中去。
另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP/2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
可见,HTTP/2.0实现了真正的并行传输,它能够在一个 TCP 连接上进行任意数量的请求,而这个强大的功能则是基于“二进制分帧”的特性。
头部压缩:在
HTTP/1.x中,头部元数据都是以纯文本的形式发送的,通常会给每个请求增加 500~800 字节的负荷。因为 HTTP 协议是无状态的,所以每次请求都必须带上所有信息。所以请求的很多字段都是重复的,比如 Cookie 和 UserAgent,一模一样的内容,每次请求都必须携带,这会浪费很多带宽,也影响传输速度。
HTTP/2.0对这一点做了优化,引入头信息压缩机制(header compression)。一方面,头信息用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器端同时维护一张头信息表,所有的字段都会存入这个表,生成一个索引号,以后就不发送同样的字段了,只发送索引号,减少了需要传输的数据大小。服务器推送:
HTTP/2.0允许服务器不需要客户端的请求就可以主动向客户端发送资源。流量控制: HTTP/2.0 不同于 HTTP/1.1 的只要客户端可以处理,服务端就会尽可能快地发送数据。HTTP/2.0 提供了客户端调整传输速度的能力(服务端也可以),在每一个数据帧中告诉对方,发送方想要接受多少字节的数据。
Http3.0:
基于 UDP 开发了一个 QUIC 协议
首先说 http1.0
它的特点是每次请求和响应完毕后都会销毁 TCP 连接,同时规定前一个响应完成后才能发送下一个请求。这样做有两个问题:
- 无法复用连接
每次请求都要创建新的 TCP 连接,完成三次握手和四次挥手,网络利用率低
- 队头阻塞
如果前一个请求被某种原因阻塞了,会导致后续请求无法发送。
然后是 http1.1
http1.1 是 http1.0 的改进版,它做出了以下改进:
- 长连接
http1.1 允许在请求时增加请求头 connection:keep-alive,这样便允许后续的客户端请求在一段时间内复用之前的 TCP 连接
- 管道化
基于长连接的基础,管道化可以不等第一个请求响应继续发送后面的请求,但响应的顺序还是按照请求的顺序返回。
- 缓存处理
新增响应头 cache-control,用于实现客户端缓存。
- 断点传输
在上传/下载资源时,如果资源过大,将其分割为多个部分,分别上传/下载,如果遇到网络故障,可以从已经上传/下载好的地方继续请求,不用从头开始,提高效率
最后是 http2.0
http2.0 进一步优化了传输效率,它主要有以下改进:
- 二进制分帧
将传输的消息分为更小的二进制帧,每帧有自己的标识序号,即便被随意打乱也能在另一端正确组装
- 多路复用
基于二进制分帧,在同一域名下所有访问都是从同一个 tcp 连接中走,并且不再有队头阻塞问题,也无须遵守响应顺序
- 头部压缩
http2.0 通过字典的形式,将头部中的常见信息替换为更少的字符,极大的减少了头部的数据量,从而实现更小的传输量
- 服务器推送
http2.0 允许服务器直接推送消息给客户端,无须客户端明确的请求
为什么 HTTP1.1 不能实现多路复用(腾讯)
HTTP/1.1 不是二进制传输,而是通过文本进行传输。由于没有流的概念,在使用并行传输(多路复用)传递数据时,接收端在接收到响应后,并不能区分多个响应分别对应的请求,所以无法将多个响应的结果重新进行组装,也就实现不了多路复用。
http2 的多路复用?
在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。 帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。 多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
谈谈你对 TCP 三次握手和四次挥手的理解
TCP 协议通过三次握手建立可靠的点对点连接,具体过程是:
首先服务器进入监听状态,然后即可处理连接
第一次握手:建立连接时,客户端发送 syn 包到服务器,并进入 SYN_SENT 状态,等待服务器确认。在发送的包中还会包含一个初始序列号 seq。此次握手的含义是客户端希望与服务器建立连接。
第二次握手:服务器收到 syn 包,然后回应给客户端一个 SYN+ACK 包,此时服务器进入 SYN_RCVD 状态。此次握手的含义是服务端回应客户端,表示已收到并同意客户端的连接请求。
第三次握手:客户端收到服务器的 SYN 包后,向服务器再次发送 ACK 包,并进入 ESTAB_LISHED 状态。
最后,服务端收到客户端的 ACK 包,于是也进入 ESTAB_LISHED 状态,至此,连接建立完成
当需要关闭连接时,需要进行四次挥手才能关闭
- Client 向 Server 发送 FIN 包,表示 Client 主动要关闭连接,然后进入 FIN_WAIT_1 状态,等待 Server 返回 ACK 包。此后 Client 不能再向 Server 发送数据,但能读取数据。
- Server 收到 FIN 包后向 Client 发送 ACK 包,然后进入 CLOSE_WAIT 状态,此后 Server 不能再读取数据,但可以继续向 Client 发送数据。
- Client 收到 Server 返回的 ACK 包后进入 FIN_WAIT_2 状态,等待 Server 发送 FIN 包。
- Server 完成数据的发送后,将 FIN 包发送给 Client,然后进入 LAST_ACK 状态,等待 Client 返回 ACK 包,此后 Server 既不能读取数据,也不能发送数据。
- Client 收到 FIN 包后向 Server 发送 ACK 包,然后进入 TIME_WAIT 状态,接着等待足够长的时间(2MSL)以确保 Server 接收到 ACK 包,最后回到 CLOSED 状态,释放网络资源。
- Server 收到 Client 返回的 ACK 包后便回到 CLOSED 状态,释放网络资源。
介绍 HTTPS 握手过程
- 客户端请求服务器,并告诉服务器自身支持的加密算法以及密钥长度等信息
- 服务器响应公钥和服务器证书
- 客户端验证证书是否合法,然后生成一个会话密钥,并用服务器的公钥加密密钥,把加密的结果通过请求发送给服务器
- 服务器使用私钥解密被加密的会话密钥并保存起来,然后使用会话密钥加密消息响应给客户端,表示自己已经准备就绪
- 客户端使用会话密钥解密消息,知道了服务器已经准备就绪。
- 后续客户端和服务器使用会话密钥加密信息传递消息
HTTP 请求头字段和响应头字段
Accept 设置接受的内容类型
Accept: text/plain
Accept-Charset 设置接受的字符编码
Accept-Charset: utf-8
Accept-Encoding 设置接受的编码格式
Accept-Encoding: gzip, deflate
Accept-Datetime 设置接受的版本时间
Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT
Accept-Language 设置接受的语言
Accept-Language: en-US
Authorization 设置 HTTP 身份验证的凭证
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Cache-Control 设置请求响应链上所有的缓存机制必须遵守的指令
Cache-Control: no-cache
Connection 设置当前连接和 hop-by-hop 协议请求字段列表的控制选项
Connection: keep-alive Connection: Upgrade
Content-Length 设置请求体的字节长度
Content-Length: 348
Content-MD5 设置基于 MD5 算法对请求体内容进行 Base64 二进制编码
Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ==
Content-Type 设置请求体的 MIME 类型(适用 POST 和 PUT 请求)
Content-Type: application/x-www-form-urlencoded
Cookie 设置服务器使用 Set-Cookie 发送的 http cookie
Cookie: $Version=1; Skin=new;
Date 设置消息发送的日期和时间
Date: Tue, 15 Nov 1994 08:12:31 GMT
Expect 标识客户端需要的特殊浏览器行为
Expect: 100-continue
Forwarded 披露客户端通过 http 代理连接 web 服务的源信息
Forwarded: for=192.0.2.60;proto=http;by=203.0.113.43 Forwarded: for=192.0.2.43, for=198.51.100.17
From 设置发送请求的用户的 email 地址
From: user@example.com
Host 设置服务器域名和 TCP 端口号,如果使用的是服务请求标准端口号,端口号可以省略
Host: en.wikipedia.org:8080 Host: en.wikipedia.org
If-Match 设置客户端的 ETag,当时客户端 ETag 和服务器生成的 ETag 一致才执行,适用于更新自从上次更新之后没有改变的资源
If-Match: "737060cd8c284d8af7ad3082f209582d
If-Modified-Since 设置更新时间,从更新时间到服务端接受请求这段时间内如果资源没有改变,允许服务端返回 304 Not Modified
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
If-None-Match 设置客户端 ETag,如果和服务端接受请求生成的 ETage 相同,允许服务端返回 304 Not Modified
If-None-Match: "737060cd8c284d8af7ad3082f209582d"
If-Range 设置客户端 ETag,如果和服务端接受请求生成的 ETage 相同,返回缺失的实体部分;否则返回整个新的实体
If-Range: "737060cd8c284d8af7ad3082f209582d"
If-Unmodified-Since 设置更新时间,只有从更新时间到服务端接受请求这段时间内实体没有改变,服务端才会发送响应
If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Max-Forwards 限制代理或网关转发消息的次数
Max-Forwards: 10
Origin 标识跨域资源请求(请求服务端设置 Access-Control-Allow-Origin 响应字段)
Origin:
http://www.example-social-network.com
Pragma 设置特殊实现字段,可能会对请求响应链有多种影响
Pragma: no-cache
Proxy-Authorization 为连接代理授权认证信息
Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Range 请求部分实体,设置请求实体的字节数范围,具体可以参见 HTTP/1.1 中的 Byte serving
Range: bytes=500-999
Referer 设置前一个页面的地址,并且前一个页面中的连接指向当前请求,意思就是如果当前请求是在 A 页面中发送的,那么 referer 就是 A 页面的 url 地址(轶事:这个单词正确的拼法应该是"referrer",但是在很多规范中都拼成了"referer",所以这个单词也就成为标准用法)
Referer:
http://en.wikipedia.org/wiki/Main_Page
TE 设置用户代理期望接受的传输编码格式,和响应头中的 Transfer-Encoding 字段一样
TE: trailers, deflate
Upgrade 请求服务端升级协议
Upgrade: HTTP/2.0, HTTPS/1.3, IRC/6.9, RTA/x11, websocket
User-Agent 用户代理的字符串值
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0
Via 通知服务器代理请求
Via: 1.0 fred, 1.1 example.com (Apache/1.1)
Warning 实体可能会发生的问题的通用警告
Warning: 199 Miscellaneous warning
常用非标准请求头字段
X-Requested-With 标识 Ajax 请求,大部分 js 框架发送请求时都会设置它为 XMLHttpRequest
X-Requested-With: XMLHttpRequest
DNT 请求 web 应用禁用用户追踪
DNT: 1 (Do Not Track Enabled) DNT: 0 (Do Not Track Disabled)
X-Forwarded-For 一个事实标准,用来标识客户端通过 HTTP 代理或者负载均衡器连接的 web 服务器的原始 IP 地址
X-Forwarded-For: client1, proxy1, proxy2 X-Forwarded-For: 129.78.138.66, 129.78.64.103
X-Forwarded-Host 一个事实标准,用来标识客户端在 HTTP 请求头中请求的原始 host,因为主机名或者反向代理的端口可能与处理请求的原始服务器不同
X-Forwarded-Host: en.wikipedia.org:8080 X-Forwarded-Host: en.wikipedia.org
X-Forwarded-Proto 一个事实标准,用来标识 HTTP 原始协议,因为反向代理或者负载均衡器和 web 服务器可能使用 http,但是请求到反向代理使用的是 https
X-Forwarded-Proto: https
Front-End-Https 微软应用程序和负载均衡器使用的非标准 header 字段 Front-End-Https: on X-Http-Method-Override 请求 web 应用时,使用 header 字段中给定的方法(通常是 put 或者 delete)覆盖请求中指定的方法(通常是 post),如果用户代理或者防火墙不支持直接使用 put 或者 delete 方法发送请求时,可以使用这个字段
X-HTTP-Method-Override: DELETE
X-ATT-DeviceId 允许更简单的解析用户代理在 AT&T 设备上的 MakeModel/Firmware
X-Att-Deviceid: GT-P7320/P7320XXLPG
X-Wap-Profile 设置描述当前连接设备的详细信息的 xml 文件在网络中的位置
x-wap-profile:
http://wap.samsungmobile.com/uaprof/SGH-I777.xml
Proxy-Connection 早起 HTTP 版本中的一个误称,现在使用标准的 connection 字段
Proxy-Connection: keep-alive
X-UIDH 服务端深度包检测插入的一个唯一 ID 标识 Verizon Wireless 的客户
X-UIDH: ...
X-Csrf-Token,X-CSRFToken,X-XSRF-TOKEN 防止跨站请求伪造
X-Csrf-Token: i8XNjC4b8KVok4uw5RftR38Wgp2BFwql
X-Request-ID,X-Correlation-ID 标识客户端和服务端的 HTTP 请求
X-Request-ID: f058ebd6-02f7-4d3f-942e-904344e8cde5
常用标准响应头字段
Access-Control-Allow-Origin 指定哪些站点可以参与跨站资源共享
Access-Control-Allow-Origin: *
Accept-Patch 指定服务器支持的补丁文档格式,适用于 http 的 patch 方法
Accept-Patch: text/example;charset=utf-8
Accept-Ranges 服务器通过 byte serving 支持的部分内容范围类型
Accept-Ranges: bytes
Age 对象在代理缓存中暂存的秒数
Age: 12
Allow 设置特定资源的有效行为,适用方法不被允许的 http 405 错误
Allow: GET, HEAD
Alt-Svc 服务器使用"Alt-Svc"(Alternative Servicesde 的缩写)头标识资源可以通过不同的网络位置或者不同的网络协议获取
Alt-Svc: h2="http2.example.com:443"; ma=7200
Cache-Control 告诉服务端到客户端所有的缓存机制是否可以缓存这个对象,单位是秒
Cache-Control: max-age=3600
Connection 设置当前连接和 hop-by-hop 协议请求字段列表的控制选项
Connection: close
Content-Disposition 告诉客户端弹出一个文件下载框,并且可以指定下载文件名
Content-Disposition: attachment; filename="fname.ext"
Content-Encoding 设置数据使用的编码类型
Content-Encoding: gzip
Content-Language 为封闭内容设置自然语言或者目标用户语言
Content-Language: en
Content-Length 响应体的字节长度
Content-Length: 348
Content-Location 设置返回数据的另一个位置
Content-Location: /index.htm
Content-MD5 设置基于 MD5 算法对响应体内容进行 Base64 二进制编码
Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ==
Content-Range 标识响应体内容属于完整消息体中的那一部分
Content-Range: bytes 21010-47021/47022
Content-Type 设置响应体的 MIME 类型
Content-Type: text/html; charset=utf-8
Date 设置消息发送的日期和时间
Date: Tue, 15 Nov 1994 08:12:31 GMT
ETag 特定版本资源的标识符,通常是消息摘要
ETag: "737060cd8c284d8af7ad3082f209582d"
Expires 设置响应体的过期时间
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Last-Modified 设置请求对象最后一次的修改日期
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
Link 设置与其他资源的类型关系
Link: ; rel="alternate"
Location 在重定向中或者创建新资源时使用
Location:
http://www.w3.org/pub/WWW/People.html
P3P 以 P3P:CP="your_compact_policy"的格式设置支持 P3P(Platform for Privacy Preferences Project)策略,大部分浏览器没有完全支持 P3P 策略,许多站点设置假的策略内容欺骗支持 P3P 策略的浏览器以获取第三方 cookie 的授权
P3P: CP="This is not a P3P policy! See
http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657for more info."
Pragma 设置特殊实现字段,可能会对请求响应链有多种影响
Pragma: no-cache
Proxy-Authenticate 设置访问代理的请求权限
Proxy-Authenticate: Basic
Public-Key-Pins 设置站点的授权 TLS 证书
Public-Key-Pins: max-age=2592000; pin-sha256="E9CZ9INDbd+2eRQozYqqbQ2yXLVKB9+xcprMF+44U1g=";
Refresh "重定向或者新资源创建时使用,在页面的头部有个扩展可以实现相似的功能,并且大部分浏览器都支持
<meta http-equiv="refresh" content="5; url=http://example.com/">
Refresh: 5; url=
http://www.w3.org/pub/WWW/People.html
Retry-After 如果实体暂时不可用,可以设置这个值让客户端重试,可以使用时间段(单位是秒)或者 HTTP 时间
Example 1: Retry-After: 120 Example 2: Retry-After: Fri, 07 Nov 2014 23:59:59 GMT
Server 服务器名称
Server: Apache/2.4.1 (Unix)
Set-Cookie 设置 HTTP Cookie
Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1
Status 设置 HTTP 响应状态
Status: 200 OK
Strict-Transport-Security 一种 HSTS 策略通知 HTTP 客户端缓存 HTTPS 策略多长时间以及是否应用到子域
Strict-Transport-Security: max-age=16070400; includeSubDomains
Trailer 标识给定的 header 字段将展示在后续的 chunked 编码的消息中
Trailer: Max-Forwards
Transfer-Encoding 设置传输实体的编码格式,目前支持的格式: chunked, compress, deflate, gzip, identity
Transfer-Encoding: chunked
TSV Tracking Status Value,在响应中设置给 DNT(do-not-track),可能的取值 "!" — under construction "?" — dynamic "G" — gateway to multiple parties "N" — not tracking "T" — tracking "C" — tracking with consent "P" — tracking only if consented "D" — disregarding DNT "U" — updated
TSV: ?
Upgrade 请求客户端升级协议
Upgrade: HTTP/2.0, HTTPS/1.3, IRC/6.9, RTA/x11, websocket
Vary 通知下级代理如何匹配未来的请求头已让其决定缓存的响应是否可用而不是重新从源主机请求新的
Example 1: Vary: * Example 2: Vary: Accept-Language
Via 通知客户端代理,通过其要发送什么响应
Via: 1.0 fred, 1.1 example.com (Apache/1.1)
Warning 实体可能会发生的问题的通用警告
Warning: 199 Miscellaneous warning
WWW-Authenticate 标识访问请求实体的身份验证方案
WWW-Authenticate: Basic
X-Frame-Options 点击劫持保护: deny frame 中不渲染 sameorigin 如果源不匹配不渲染 allow-from 允许指定位置访问 allowall 不标准,允许任意位置访问
X-Frame-Options: deny
常用非标准响应头字段
X-XSS-Protection 过滤跨站脚本
X-XSS-Protection: 1; mode=block
Content-Security-Policy, X-Content-Security-Policy,X-WebKit-CSP 定义内容安全策略
X-WebKit-CSP: default-src 'self'
X-Content-Type-Options 唯一的取值是"",阻止 IE 在响应中嗅探定义的内容格式以外的其他 MIME 格式
X-Content-Type-Options: nosniff
X-Powered-By 指定支持 web 应用的技术
X-Powered-By: PHP/5.4.0
X-UA-Compatible 推荐首选的渲染引擎来展示内容,通常向后兼容,也用于激活 IE 中内嵌 chrome 框架插件
<meta http-equiv="X-UA-Compatible" content="chrome=1" />
X-UA-Compatible: IE=EmulateIE7 X-UA-Compatible: IE=edge X-UA-Compatible: Chrome=1
X-Content-Duration 提供音视频的持续时间,单位是秒,只有 Gecko 内核浏览器支持
X-Content-Duration: 42.666
Upgrade-Insecure-Requests 标识服务器是否可以处理 HTTPS 协议
Upgrade-Insecure-Requests: 1
X-Request-ID,X-Correlation-ID 标识一个客户端和服务端的请求
X-Request-ID: f058ebd6-02f7-4d3f-942e-904344e8cde5
HTTP 和 HTTPS 区别
HTTP:
HTTP 为超文本传输协议,位于应用层。主要用于超媒体文本的底层协议,经常在浏览器和服务器之间传输数据。通信就是春文本的形式进行的。
特点:
HTTP 是无状态的,也就是说对客户端的请求状态没有进行存储,比如每次请求都需要登录。
HTTP 是无连接的,无连接也就是说每次连接都只处理一个请求。每次请求都是客户端发起请求,服务端相应请求,然后断开连接。期间通过三次握手建立连接,四次挥手断开连接。每次请求即使是多次请求同一个资源,服务端也无法判断是否是相同的请求,都需要重新响应请求。
所以为了保持服务端和客户端的会话连接,需要通过 cookie 和 session 来记录 http 状态。
HTTP 的特点是简单快速,只需要传送方法和路径就可以向服务端请求,而且支持传输任意类型的数据对象。
HTTPS:
https 是 http 的升级版,也就是 HTTP+TLS/SSL = HTTPS
SSL 是安全层,TLS 是传输层安全,是 SSL 的继承。使用 SSL 或者 TLS 可确保数据的安全性。
使用 HTTP 可能看到的传输数据是:“这是明文数据”
使用 HTTPS 可能看到:“283hd9saj9cdsncihquhs99ndso”。HTTPS 传输的不再是文本,而是二进制流,传输更加高效,而且加密处理更加安全。
区别:
加密方式:HTTS 是比 HTTP 更加安全的版本,使用 SSL/TLS 进行加密传输数据
连接方式:HTTP(三次握手)和 HTTPS(三次握手+数字证书)连接方式不一样
端口:HTTP 默认端口 80,HTTPS 默认端口 443
HTTP2 是什么?
HTTP/2 超文本传输协议第 2 版,是 HTTP/1.x 的扩展。所以 HTTP/2 没有改动 HTTP 的应用语义,仍然使用 HTTP 的请求方法、状态码和头字段等规则。
它主要修改了 HTTP 的报文传输格式,通过引入二进制分帧层实现性能的提升。
现有很多主流浏览器的 HTTPS/2 的实现都是基于 SSL/TLS 的,所以基于 SSL/TLS 的 HTTP/2 连接建立过程和 HTTPS 差不多。在建立连接过程中会携带标识期望使用 HTTP/2 协议,服务端同样方式回应。
https 的整个过程
1、客户端发起 HTTPS 请求并连接到服务器的 443 端口,此过程和 HTTP 请求一样,进行三次握手。
2、服务端向客户端发送数字证书,其中包含了公钥、证书颁发者和到期日期。你在比较流行的是加解密密钥对,即公钥和私钥。公钥用于加密,私钥用于解密。所以服务端会保留私钥然后发送公钥给客户端。
3、客户端收到证书后,会验证证书的有效性。验证通过后会生成一个随机的 pre-master key。再将密钥通过接收到的公钥加密后发送给服务端。
4、服务端收到后用保存的私钥进行解密得到 pre-master key
5、获得 pre-master key 之后,服务端和客户端就可以使用主密钥进行通信。
强缓存和协商缓存
强缓存
基本流程
当一个浏览器第一次访问一个网站的时候,向该网站的服务器发送请求。如果服务端觉得浏览器请求的资源应该被缓存下来时 比如图片,CSS 文件等不常更改的资源,没有必要在 HTTP 响应中频繁携带,就会在 HTTP 响应里面添加一个响应头 Cache-Control:max-age=1200(即缓存有效时间为 1200s)。这会让浏览器自动将该请求的资源缓存到本地。
下一次请求该资源时,浏览器先看本地缓存的资源有没有过期,没过期的话直接使用该资源,不发送请求,且返回 Status Code:200 OK,但是会添加上(from memory cache 或 from disk memory)的标识,表示该文件是从缓存中拿到的,没有向服务端发送请求。
如果过期了且没有协商缓存(可以先跳过这个协商缓存,下面会讲)就向服务端发送请求索要该资源,服务端依然是根据该资源的特性判断要不要缓存,即要不要加 Cache-Control 响应头。
整个过程都是由 服务端控制浏览器要不要缓存取决于 HTTP 响应头有没有设置 Cache-Control,且取值不为 no-store(no-store 表示不缓存)。
注意: (1)
强缓存不发送请求,直接从本地缓存读取资源并返回 Status Code: 200 OK; (2)from memory cache 表示资源是从内存当中获取的,浏览器关闭后该资源内存会被释放;from disk memory 表示资源是从硬盘中读取的,关掉浏览器资源依然在。
协商缓存(又名对比缓存)
基本流程
当一个浏览器第一次访问一个网站的时候,向该网站的服务器发送请求。服务器返回资源和资源的标识。浏览器会把该资源和该标识缓存到本地。
下一次请求该资源时,浏览器会把该资源标识带上,服务器就会对该标识对应的资源进行判断: (1)如果该资源发生了修改,已不是原来的版本,那么服务器就会返回最新的资源和新的资源标识,状态码为 200,表示请求成功。 (2)如果该资源距离上一次请求并没有发生改变,则返回304,告诉浏览器可以直接使用本地缓存的资源,响应时就无需携带资源。
协商缓存中的资源标识(2 种)
Last-Modified:资源上一次修改的时间
服务端可以根据资源上一次修改的时间判断出该资源是否为最新。
具体过程:浏览器第一次请求资源时,服务端会返回资源和资源标识 last-Modified; 当浏览器下一次请求该资源时,会带上这个标识,请求头键名为:If-Modified-Since,键值为第一次访问时服务端返回的那个修改时间标识; 该请求发送到服务端之后,服务端会检查该值跟所请求资源的最近修改时间是否为一致: (1)如果一致直接返回 304 (2)如果不一致返回 200 + 最新资源 + 最新的资源修改时间
ETag:资源对应的唯一字符串
服务端可以根据唯一的字符串是否发生变化判断该资源是否为最新。
具体过程:浏览器第一次请求资源时,服务端会返回资源和资源标识 ETag 字符串; 当浏览器下一次请求该资源时,会带上这个字符串,请求头的键名为:If-None-Match,键值为第一次访问时服务端返回的 ETag 字符串; 该请求发送到服务端之后,服务端会检查该值跟所请求资源的标识字符串是否一致: (1)如果一致说明文件内容没有发生变化,直接返回 304; (2)如果不一致返回 200 + 最新资源 + 最新的 ETag 字符串。
ETag 字符串不一致说明,在两次访问文件资源期间,对文件做了修改,访问了修改文件的接口,后端将最新修改的内容生成一个新的字符串,保存了起来。
Last-Modified 和 ETag 比较
我们已经了解了这两种不同的方式,那么我们要选择哪一种呢?
优先使用 ETag,原因如下:
Last-Modified 只精确到秒级;
Last-Modified 标识即使文件内容相同,但是只要修改时间发生变化,都会再次返回该资源,而 ETag 可以判断出文件内容是否相同,相同则直接返回 304,缓存策略更佳。
如果使用的是 Last-Modified ,比如文件 A 加上了一段文字并保存,然后又把这段文字删除后再保存。此时尽管资源的内容不变,但是资源的修改时间发生了变化,服务端依然会返回该资源,而不是返回 304。 如果使用的是 ETag 字符串,那么文件 A 的内容其实是没有发生变化的,浏览器依然会用本地的缓存。
总结
当浏览器请求一个资源时,浏览器会先判断本地有没有缓存;
没有缓存则直接发送请求,拿到最新的资源;如果有缓存,就判断是否过期;
如果没过期就直接用本地缓存的资源,如果过期了就再看有没有 Last-Modified 或 ETag;
没有的话就直接请求资源,有的话就带上该标识去往服务端,服务端会根据该资源的修改情况返回 200 或 304;
最后拿到数据,渲染页面。
追问:哪些字段用做强缓存?哪些字段用做协商缓存?
强缓存:Cache-Control(HTTP1.1), expires(HTTP1.0)
当cache-control和expires同时设置时,会忽略掉expires,使用cache-control。在Expires的指定时间内(客户端时间),都会从缓存中读取。
强缓存主要使用 Expires、Cache-Control 两个头字段,两者同时存在 Cache-Control 优先级更高。当命中强缓存的时候,客户端不会再求,直接从缓存中读取内容,并返回 HTTP 状态码 200。
协商缓存:etag/if-none-match(HTTP1.1),、last-modified/if-modified-since(HTTP1.0)
协商缓存主要有四个头字段,它们两两组合配合使用,If-Modified-Since 和 Last-Modified 一组,Etag 和 If-None-Match 一组,当同时存在的时候会以 Etag 和 If-None-Match 为主。当命中协商缓存的时候,服务器会返回 HTTP 状态码 304,让客户端直接从本地缓存里面读取文件。
追问:cache-control、expires、etag、last-modified 等字段的属性值是什么样的?
cache-control 可选值:
Cache-Control: public // 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。(例如:1.该响应没有max-age指令或Expires消息头;2. 该响应对应的请求方法是 POST 。)
Cache-Control: private // 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)。私有缓存可以缓存响应内容,比如:对应用户的本地浏览器。
Cache-control: no-cache //在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证 (协商缓存验证)。
Cache-control: no-store // 缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存。
Cache-Control: max-age=<seconds> //设置缓存存储的最大周期,超过这个时间缓存被认为过期 (单位秒)。与Expires相反,时间是相对于请求的时间。
Cache-Control: s-maxage=<seconds> //覆盖max-age或者Expires头,但是仅适用于共享缓存 (比如各个代理),私有缓存会忽略它。
Cache-Control: max-stale[=<seconds>] // 表明客户端愿意接收一个已经过期的资源。可以设置一个可选的秒数,表示响应不能已经过时超过该给定的时间。
Cache-Control: min-fresh=<seconds>// 表示客户端希望获取一个能在指定的秒数内保持其最新状态的响应。
Cache-Control: must-revalidate //一旦资源过期(比如已经超过max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求。
Cache-control: no-transform //不得对资源进行转换或转变。Content-Encoding、Content-Range、Content-Type等 HTTP 头不能由代理修改。例如,非透明代理或者如Google's Light Mode可能对图像格式进行转换,以便节省缓存空间或者减少缓慢链路上的流量。no-transform指令不允许这样做。
Cache-control: only-if-cached // 表明客户端只接受已缓存的响应,并且不要向原始服务器检查是否有更新的拷贝。
expires 可选值:
响应头包含日期/时间,即在此时候之后,响应过期。无效的日期,比如 0,代表着过去的日期,即该资源已经过期。
Expires: Wed, 21 Oct 2015 07:28:00 GMT
etag 可选值:
ETag: W/"<etag_value>" //'W/'(大小写敏感) 表示使用弱验证器。弱验证器很容易生成,但不利于比较。强验证器是比较的理想选择,但很难有效地生成。相同资源的两个弱Etag值可能语义等同,但不是每个字节都相同。
ETag: "<etag_value>" //实体标签唯一地表示所请求的资源。它们是位于双引号之间的 ASCII 字符串(如“675af34563dc-tr34”)。没有明确指定生成 ETag 值的方法。通常,使用内容的散列,最后修改时间戳的哈希值,或简单地使用版本号。例如,MDN 使用 wiki 内容的十六进制数字的哈希值。
last-modified 可选值:
Last-Modified: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT
Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
追问:这些字段都被存放在请求的哪个部分?
cache-control 请求头和相应头都可以使用,但是主要放在响应头中。
请求头:cache-control、if-modified-since、if-none-match
响应头:expires、 last-modified、 etag
注意为什么 cache-control 和 etag 没有配对字段?因为他俩主要用于强缓存,强缓存不走服务端,直接在浏览器中就判断了呀
追问:last-modified 和 expires 这些字段的时间有什么区别?
都是一个 GMT 时间
last-modified 只能精确到秒
追问:last-modify 和 expires 能共存吗?
可以,它与 Last-Modified/Etag 结合使用,用来控制请求文件的有效时间,当请求数据在有效期内,浏览器从缓存获得数据。Last-Modifed/Etag 能够节省一点宽带,但是还会发一个 HTTP 请求。
追问:如果不想让某个资源使用缓存,那么应该如何设计 http 缓存?
cache-control:no-store
追问:cache-control 中的 no-cache 和 no-store 的区别
no-cache 和 no-store 用作控制缓存,被服务器通过响应头 Cache-Control 传递给客户端
- no-store
永远都不要在客户端存储资源,永远都去原始服务器去获取资源。
- no-cache
可以在客户端存储资源,每次都必须去服务端做缓存校验,也就是说不要使用强缓存,来决定从服务端获取新的资源(200)还是使用客户端缓存(304)。也就是所谓的协商缓存。
相当于:
Cache-Control: max-age=0, must-revalidate
什么是启发式缓存?
如果一个可以缓存的请求没有设置 Expires 和 Cache-Control,但是响应头有设置 Last-Modified 信息,这种情况下浏览器会有一个默认的缓存策略:(Date - Last-Modified)*0.1,这就是启发式缓存。
目前看来,大部分浏览器都已经实现了,但是彼此也略有不同。
注:只有在服务端没有返回明确的缓存策略时才会激活浏览器的启发式缓存策略。
启发式缓存会引起什么问题吗??
考虑一个情况,假设你有一个文件没有设置缓存时间,在一个月前你更新了上个版本。这次发版后,你可能得等到 3 天后用户才看到新的内容了。如果这个资源还在 CDN 也缓存了,则问题会更严重。
所以,要给资源设置合理的缓存时间。不要不设置缓存,也不要设置过长时间的缓存。强缓存时间过长,则内容要很久才会覆盖新版本,缓存时间过短,服务器可能背不住。一般带 hash 的文件缓存时间可以长一点。
HTTP 状态码
1XX 表示通知信息, 如请求收到了或正在处理中, 需要请求者继续执行操作
2xx 表示成功,如接受或知道了。
3xx 表示重定向,表示要完成请求还必须采取进一步的行动。
4xx 表示客户端的差错,如请求中有错误的语法或不能完成。
5xx 表示服务器的差错,如服务器失效无法完成请求。
100 Continue 继续,客户端应该继续其请求
101 Switching Protocols 切换协议,服务端根据客户端的请求切换协议,只能切换到更高级的协议,例如,切换到 HTTP 的新版本协议
102 Processing 此代码表示服务器已收到并正在处理该请求,但当前没有响应可用。
103 Early Hints 此状态代码主要用于与 Link 链接头一起使用,以允许用户代理在服务器准备响应阶段时开始预加载 preloading 资源。
200 OK 表示客户端请求被服务端正常处理了。
201 Created 已创建。成功请求并且创建了新资源。这通常是在 POST 请求,或是某些 PUT 请求之后返回的响应。
202 Accepted 已接受。请求已经接收到,但还未响应,没有结果。意味着不会有一个异步的响应去表明当前请求的结果,预期另外的进程和服务去处理请求,或者批处理。
203 Non-Authoritative Information 非授权信息。服务器已成功处理了请求,但返回的实体头部元信息不是在原始服务器上有效的确定集合,而是来自本地或者第三方的拷贝。当前的信息可能是原始版本的子集或者超集。例如,包含资源的元数据可能导致原始服务器知道元信息的超集。使用此状态码不是必须的,而且只有在响应不使用此状态码便会返回200 OK的情况下才是合适的。
204 No Content 无内容。服务器成功处理内容,但是未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前的文档。对于该请求没有的内容可发送,但头部字段可能有用。用户代理可能会用此时请求头部信息来更新原来资源的头部缓存字段。
205 Reset Content 重置内容。服务器处理成功,用户终端(如浏览器)应该重置文档视图。可通过此状态码清除浏览器的表单域。
206 Partial Content 部分内容。服务器成功处理了部分 GET 请求。当从客户端发送Range范围标头以只请求资源的一部分时,将使用此响应代码。
207 Multi-Status 对于多个状态代码都可能合适的情况,传输有关多个资源的信息。
208 Already Reported 在 DAV 里面使用 <dav:propstat> 响应元素以避免重复枚举多个绑定的内部成员到同一个集合。
226 IM Used 服务器已经完成了对资源的 GET 请求,并且响应是对当前实例应用的一个或多个实例操作结果的表示。
300 Multiple Choices 多种选择。请求拥有多个可能的响应。用户代理或者用户应当从中选择一个。(没有标准化的方法来选择其中一个响应,但是建议使用指向可能性的 HTML 链接,以便用户可以选择。)
301 Moved Permanently 永久移动。请求的资源已被永久的移动到新的 URL,返回信息会包括新的 URL,浏览器会自动定位到新的 URL。今后任何新的请求都应该使用新的 URL 代替。
302 Found 临时移动,与 301 类似。此响应代码表示所请求资源的 URI 已暂时更改。未来可能会对 URI 进行进一步的改变。因此,客户机应该在将来的请求中使用这个相同的 URI。
303 See Other 表示请求对应的资源存在着另一个 URL,应使用 GET 方法定向获取请求资源
304 Not Modified 未修改。所请求的资源未修改,服务端返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源。
305 Use Proxy 使用代理。所请求的资源必须通过代理访问。
306 Unused 已经被废弃的 HTTP 状态码。此响应代码不再使用;它只是保留。它曾在 HTTP/1.1 规范的早期版本中使用过。
307 Temporary Redirect 临时重定向。服务器发送此响应,以指示客户端使用在前一个请求中使用的相同方法在另一个 URI 上获取所请求的资源。这与 302 Found HTTP 响应代码具有相同的语义,但用户代理 不能 更改所使用的 HTTP 方法:如果在第一个请求中使用了 POST,则在第二个请求中必须使用 POST
308 Permanent Redirect 这意味着资源现在永久位于由 Location: HTTP Response 标头指定的另一个 URI。这与 301 Moved Permanently HTTP 响应代码具有相同的语义,但用户代理不能更改所使用的 HTTP 方法:如果在第一个请求中使用 POST,则必须在第二个请求中使用 POST。
400 Bad Request 客户端包含语法错误,(例如,错误的请求语法、无效的请求消息帧或欺骗性的请求路由),服务器无法或不会处理请求
401 Unauthorized 请求要求用户的身份认证。
402 Payment Required 保留,将来使用
403 Forbidden 服务端理解客户端的请求,但是拒绝执行此请求。客户端没有访问内容的权限;也就是说,它是未经授权的,因此服务器拒绝提供请求的资源。与 401 Unauthorized 不同,服务器知道客户端的身份。
404 Not Found 服务器无法根据客户端请求找到资源。通过此代码,网站可以定制您所请求的资源无法找到的页面
405 Method Not Allowed 客户端请求中的方法被禁止。服务器知道请求方法,但目标资源不支持该方法。例如,API 可能不允许调用DELETE来删除资源。
406 Not Acceptable 服务器无法根据客户端请求的内容特性完成请求
407 Proxy Authentication Required 请求要求代理的身份认证,类似于 401 Unauthorized 但是认证需要由代理完成。
408 Request Time-out 服务器等待客户端发送的请求事件过长,超时
409 Conflict 服务端完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突
410 Gone 客户端请求的资源已经不存在。不同于 404,如果资源以前有现在被永久删除了可使用 410 代码,网站设计人员可通过 301 代码指定资源的新位置
411 Length Required 服务器无法处理客户端发送的不带 Content-Length 的请求信息
412 Precondition Failed 客户端在其头文件中指出了服务器不满足的先决条件。
413:Request Entity Too Large 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个 Retry-After 的响应信息。
414:Request-URI Too Large 请求的 URI 过长(URI 通常为网址),服务器无法处理
415:Unsupported Media Type 服务器无法处理请求附带的媒体格式。
416:Requested range not satisfiable 无法满足请求中 Range 标头字段指定的范围。该范围可能超出了目标 URI 数据的大小。
417:Expectation Failed 此响应代码表示服务器无法满足 Expect 请求标头字段所指示的期望。
418、421、422、423、424、425、426、428、429、431、451。。。
500:Internal Server Error 服务器内部错误,无法完成请求。
501:Not Implemented 服务器不支持请求的功能,无法完成请求。服务器不支持请求方法,因此无法处理。服务器需要支持的唯二方法(因此不能返回此代码)是 GET and HEAD.
502:Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应。
503:Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。常见原因是服务器因维护或重载而停机。请注意,与此响应一起,应发送解释问题的用户友好页面。这个响应应该用于临时条件和如果可能的话,HTTP 标头 Retry-After 字段应该包含恢复服务之前的估计时间。网站管理员还必须注意与此响应一起发送的与缓存相关的标头,因为这些临时条件响应通常不应被缓存。
504:Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求。
505:HTTP Version not supported 服务器不支持请求的 HTTP 协议的版本,无法完成处理。
506、507、508、510、511。。。
http2.0 性能优化方面有什么改进
1、二进制分帧层
2.0 把响应划分为了 2 个帧,采用二进制格式来传输数据,而不是 1.x 的文本格式。也就是说,一个 http 响应,划分为了两个帧来传输,并采用二进制来编码。

2、多路复用
HTTP2 让所有的通信都在一个 TCP 连接上完成,真正实现了请求的并发。HTTP2 建立一个 TCP 连接,一个连接上面可以有任意多个流(stream),消息分割成一个或多个帧在流里面传输。帧传输过去以后,再进行重组,形成一个完整的请求或响应。这使得所有的请求或响应都无法阻塞。

3、头部压缩
HTTP2 为此采用 HPACK 压缩格式来压缩首部
4、服务端推送
服务器端推送使得服务器可以预测客户端需要的资源,主动推送到客户端。
例如:客户端请求 index.html,服务器端能够额外推送 script.js 和 style.css。 实现原理就是客户端发出页面请求时,服务器端能够分析这个页面所依赖的其他资源,主动推送到客户端的缓存,当客户端收到原始网页的请求时,它需要的资源已经位于缓存。
什么是中间人攻击?
HTTPS 的实现原理:
大家可能都听说过 HTTPS 协议之所以是安全的是因为 HTTPS 协议会对传输的数据进行加密,而加密过程是使用了非对称加密实现。但其实,HTTPS 在内容传输的加密上使用的是对称加密,非对称加密只作用在证书验证阶段。
HTTPS 的整体过程分为证书验证和数据传输阶段,具体的交互过程如下:

① 证书验证阶段
- 浏览器发起 HTTPS 请求
- 服务端返回 HTTPS 证书
- 客户端验证证书是否合法,如果不合法则提示告警
② 数据传输阶段
- 当证书验证合法后,在本地生成随机数
- 通过公钥加密随机数,并把加密后的随机数传输到服务端
- 服务端通过私钥对随机数进行解密
- 服务端通过客户端传入的随机数构造对称加密算法,对返回结果内容进行加密后传输
HTTP 协议被认为不安全是因为传输过程容易被监听者勾线监听、伪造服务器,而 HTTPS 协议主要解决的便是网络传输的安全性问题。
首先我们假设不存在认证机构,任何人都可以制作证书,这带来的安全风险便是经典的“中间人攻击”问题。 “中间人攻击”的具体过程如下:

过程原理:
- 本地请求被劫持(如 DNS 劫持等),所有请求均发送到中间人的服务器
- 中间人服务器返回中间人自己的证书
- 客户端创建随机数,通过中间人证书的公钥对随机数加密后传送给中间人,然后凭随机数构造对称加密对传输内容进行加密传输
- 中间人因为拥有客户端的随机数,可以通过对称加密算法进行内容解密
- 中间人以客户端的请求内容再向正规网站发起请求
- 因为中间人与服务器的通信过程是合法的,正规网站通过建立的安全通道返回加密后的数据
- 中间人凭借与正规网站建立的对称加密算法对内容进行解密
- 中间人通过与客户端建立的对称加密算法对正规内容返回的数据进行加密传输
- 客户端通过与中间人建立的对称加密算法对返回结果数据进行解密
由于缺少对证书的验证,所以客户端虽然发起的是 HTTPS 请求,但客户端完全不知道自己的网络已被拦截,传输内容被中间人全部窃取。
针对 HTTPS 攻击主要有 SSL 劫持攻击和 SSL 剥离攻击两种。
SSL 劫持攻击是指攻击者劫持了客户端和服务器之间的连接,将服务器的合法证书替换为伪造的证书,从而获取客户端和服务器之间传递的信息。这种方式一般容易被用户发现,浏览器会明确的提示证书错误,但某些用户安全意识不强,可能会点击继续浏览,从而达到攻击目的。
SSL 剥离攻击是指攻击者劫持了客户端和服务器之间的连接,攻击者保持自己和服务器之间的 HTTPS 连接,但发送给客户端普通的 HTTP 连接,由于 HTTP 连接是明文传输的,即可获取客户端传输的所有明文数据。
https 怎样防止中间人攻击?通讯是对称加密还是非对称加密?
CA 认证机构认证证书。
通讯是对称加密。首先,非对称加密的加解密效率是非常低的,而 http 的应用场景中通常端与端之间存在大量的交互,非对称加密的效率是无法接受的;
另外,在 HTTPS 的场景中只有服务端保存了私钥,一对公私钥只能实现单向的加解密,所以 HTTPS 中内容传输加密采取的是对称加密,而不是非对称加密。
浏览器是如何确保 CA 证书的合法性?
1. 证书包含什么信息?
- 颁发机构信息
- 公钥
- 公司信息
- 域名
- 有效期
- 指纹
- ……
2. 证书的合法性依据是什么?
首先,权威机构是要有认证的,不是随便一个机构都有资格颁发证书,不然也不叫做权威机构。另外,证书的可信性基于信任制,权威机构需要对其颁发的证书进行信用背书,只要是权威机构生成的证书,我们就认为是合法的。所以权威机构会对申请者的信息进行审核,不同等级的权威机构对审核的要求也不一样,于是证书也分为免费的、便宜的和贵的。
3. 浏览器如何验证证书的合法性?
浏览器发起 HTTPS 请求时,服务器会返回网站的 SSL 证书,浏览器需要对证书做以下验证:
- 验证域名、有效期等信息是否正确。证书上都有包含这些信息,比较容易完成验证;
- 判断证书来源是否合法。每份签发证书都可以根据验证链查找到对应的根证书,操作系统、浏览器会在本地存储权威机构的根证书,利用本地根证书可以对对应机构签发证书完成来源验证;
- 判断证书是否被篡改。需要与 CA 服务器进行校验;
- 判断证书是否已吊销。通过 CRL(Certificate Revocation List 证书注销列表)和 OCSP(Online Certificate Status Protocol 在线证书状态协议)实现,其中 OCSP 可用于第 3 步中以减少与 CA 服务器的交互,提高验证效率

以上任意一步都满足的情况下浏览器才认为证书是合法的。
这里插一个我想了很久的但其实答案很简单的问题: 既然证书是公开的,如果要发起中间人攻击,我在官网上下载一份证书作为我的服务器证书,那客户端肯定会认同这个证书是合法的,如何避免这种证书冒用的情况? 其实这就是非加密对称中公私钥的用处,虽然中间人可以得到证书,但私钥是无法获取的,一份公钥是不可能推算出其对应的私钥,中间人即使拿到证书也无法伪装成合法服务端,因为无法对客户端传入的加密数据进行解密。
- 校验证书的颁发机构是否受客户端信任。
- 通过 CRL 或 OCSP 的方式校验证书是否被吊销。
- 对比系统时间,校验证书是否在有效期内。
- 通过校验对方是否存在证书的私钥,判断证书的网站域名是否与证书颁发的域名一致。
只有认证机构可以生成证书吗?
如果需要浏览器不提示安全风险,那只能使用认证机构签发的证书。但浏览器通常只是提示安全风险,并不限制网站不能访问,所以从技术上谁都可以生成证书,只要有证书就可以完成网站的 HTTPS 传输。例如早期的 12306 采用的便是手动安装私有证书的形式实现 HTTPS 访问。
为什么需要 CA 机构对证书签名
主要是为了解决证书的可信问题。如果没有权威机构对证书进行签名,客户端就无法知晓证书是否是伪造的,从而增加了中间人攻击的风险,https 就变得毫无意义。
HTTPS 一定安全吗?
不一定,本地随机数有可能会被窃取。
证书验证是采用非对称加密实现,但是传输过程是采用对称加密,而其中对称加密算法中重要的随机数是由本地生成并且存储于本地的,HTTPS 如何保证随机数不会被窃取?
其实 HTTPS 并不包含对随机数的安全保证,HTTPS 保证的只是传输过程安全,而随机数存储于本地,本地的安全属于另一安全范畴,应对的措施有安装杀毒软件、反木马、浏览器升级修复漏洞等。
用了 HTTPS 会被抓包吗?
HTTPS 的数据是加密的,常规下抓包工具代理请求后抓到的包内容是加密状态,无法直接查看。
但是,正如前文所说,浏览器只会提示安全风险,如果用户授权仍然可以继续访问网站,完成请求。因此,只要客户端是我们自己的终端,我们授权的情况下,便可以组建中间人网络,而抓包工具便是作为中间人的代理。通常 HTTPS 抓包工具的使用方法是会生成一个证书,用户需要手动把证书安装到客户端中,然后终端发起的所有请求通过该证书完成与抓包工具的交互,然后抓包工具再转发请求到服务器,最后把服务器返回的结果在控制台输出后再返回给终端,从而完成整个请求的闭环。
既然 HTTPS 不能防抓包,那 HTTPS 有什么意义? HTTPS 可以防止用户在不知情的情况下通信链路被监听,对于主动授信的抓包操作是不提供防护的,因为这个场景用户是已经对风险知情。要防止被抓包,需要采用应用级的安全防护,例如采用私有的对称加密,同时做好移动端的防反编译加固,防止本地算法被破解。
301、302、303、307、308 区别
301,Moved Permanently。永久重定向,该操作比较危险,需要谨慎操作:如果设置了 301,但是一段时间后又想取消,但是浏览器中已经有了缓存,还是会重定向。
302,Found。临时重定向,但是会在重定向的时候改变 method:把 POST 改成 GET,于是有了 307。
307,Temporary Redirect。临时重定向,在重定向时不会改变 method。
308,Permanent Redirect。永久重定向,在重定向时不会改变 method。
303 See Other 的定义
303 状态码表示服务器要将浏览器重定向到另一个资源,这个资源的 URI 会被写在响应 Header 的 Location 字段。从语义上讲,重定向到的资源并不是你所请求的资源,而是对你所请求资源的一些描述。
303 常用于将 POST 请求重定向到 GET 请求,比如你上传了一份个人信息,服务器发回一个 303 响应,将你导向一个“上传成功”页面。
不管原请求是什么方法,重定向请求的方法都是 GET(或 HEAD,不常用)。
Http 状态码 301 和 302 的应用场景分别是什么
301 表示永久重定向,302 表示临时重定向。
如果浏览器收到的是 301,则会缓存重定向的地址,之后不会再重新请求服务器,直接使用缓存的地址请求,这样可以减少请求次数。但如果浏览器收到的是 302,则不会缓存重定向地址,浏览器将来会继续以原有地址请求。
因此,301 适合地址永久转移的场景,比如域名变更;而 302 适合临时转移的场景,比如首页临时跳转到活动页
简述 TCP 连接的过程(淘系)
TCP 协议通过三次握手建立可靠的点对点连接,具体过程是:
首先服务器进入监听状态,然后即可处理连接
第一次握手:建立连接时,客户端发送 syn 包到服务器,并进入 SYN_SENT 状态,等待服务器确认。在发送的包中还会包含一个初始序列号 seq。此次握手的含义是客户端希望与服务器建立连接。
第二次握手:服务器收到 syn 包,然后回应给客户端一个 SYN+ACK 包,此时服务器进入 SYN_RCVD 状态。此次握手的含义是服务端回应客户端,表示已收到并同意客户端的连接请求。
第三次握手:客户端收到服务器的 SYN 包后,向服务器再次发送 ACK 包,并进入 ESTAB_LISHED 状态。
最后,服务端收到客户端的 ACK 包,于是也进入 ESTAB_LISHED 状态,至此,连接建立完成。
cookie 和 token 都存放在 header 中,为什么不会劫持 token?
由于浏览器会自动发送 cookie 到服务器,因此攻击者可以利用这种特点进行 csrf 攻击。
而通常 token 是不放到 cookie 中的,需要浏览器端使用 JS 自行保存到 localstorage 中,在请求时也需要手动的加入到请求头中,因此不容易引发 csrf 攻击。
介绍下如何实现 token 加密,jwt 原理
以最常见的 token 格式 jwt 为例, token 分为三段,分别是 header、payload、signature。 其中,header 标识签名算法和令牌类型;payload 标识主体信息,包含令牌过期时间、发布时间、发行者、主体内容等;signature 是使用特定的算法对前面两部分进行加密,得到的加密结果。
token 有防篡改的特点,如果攻击者改动了前面两个部分,就会导致和第三部分对应不上,使得 token 失效。而攻击者不知道加密秘钥,因此又无法修改第三部分的值。
所以,在秘钥不被泄露的前提下,一个验证通过的 token 是值得被信任的。
说下单点登录
SSO 一般都需要一个独立的认证中心(passport),子系统的登录均得通过 passport,子系统本身将不参与登录操作,当一个系统成功登录以后,passport 将会颁发一个令牌给各个子系统,子系统可以拿着令牌会获取各自的受保护资源,为了减少频繁认证,各个子系统在被 passport 授权以后,会建立一个局部会话,在一定时间内可以无需再次向 passport 发起认证。
具体流程是:
- 用户访问系统 1 的受保护资源,系统 1 发现用户未登录,跳转至 sso 认证中心,并将自己的地址作为参数
- sso 认证中心发现用户未登录,将用户引导至登录页面
- 用户输入用户名密码提交登录申请
- sso 认证中心校验用户信息,创建用户与 sso 认证中心之间的会话,称为全局会话,同时创建授权令牌
- sso 认证中心带着令牌跳转会最初的请求地址(系统 1)
- 系统 1 拿到令牌,去 sso 认证中心校验令牌是否有效
- sso 认证中心校验令牌,返回有效,注册系统 1
- 系统 1 使用该令牌创建与用户的会话,称为局部会话,返回受保护资源
- 用户访问系统 2 的受保护资源
- 系统 2 发现用户未登录,跳转至 sso 认证中心,并将自己的地址作为参数
- sso 认证中心发现用户已登录,跳转回系统 2 的地址,并附上令牌
- 系统 2 拿到令牌,去 sso 认证中心校验令牌是否有效
- sso 认证中心校验令牌,返回有效,注册系统 2
- 系统 2 使用该令牌创建与用户的局部会话,返回受保护资源
http1.1 是如何复用 tcp 连接的?(网易)
客户端请求服务器时,通过请求行告诉服务器使用的协议是 http1.1,同时在请求头中附带 connection:keep-alive(为保持兼容),告诉服务器这是一个长连接,后续请求可以重复使用这一次的 TCP 连接。
这样做的好处是减少了三次握手和四次挥手的次数,一定程度上提升了网络利用率。但由于 http1.1 不支持多路复用,响应顺序必须按照请求顺序抵达客户端,不能真正实现并行传输,因此在 http2.0 出现之前,实际项目中往往把静态资源,比如图片,分发到不同域名下的资源服务器,以便实现真正的并行传输。
文件上传如何做断点续传
客户端将文件的二进制内容进行分片,每片数据按顺序进行序号标识,上传每片数据时同时附带其序号。服务器接收到每片数据时,将其保存成一个临时文件,并记录每个文件的 hash 和序号。
若上传中止,将来再次上传时,可以向服务器索要已上传的分片序号,客户端仅需上传剩余分片即可。
当全部分片上传完成后,服务器按照分片的顺序组装成完整的文件,并删除分片文件。
介绍 SSL 和 TLS
它们都是用于保证传输安全的协议,介于传输层和应用层之间,TLS 是 SSL 的升级版。
它们的基本流程一致:
- 客户端向服务器端索要公钥,并使用数字证书验证公钥。
- 客户端使用公钥加密会话密钥,服务端用私钥解密会话密钥,于是得到一个双方都认可的会话密钥
- 传输的数据使用会话密钥加密,然后再传输,接收消息方使用会话密钥解密得到原始数据
身份验证过程中会涉及到密钥,对称加密,非对称加密,摘要的概念,请解释一下
- 密钥
密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
- 对称加密
对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有 DES、3DES、TDEA、Blowfish、RC5 和 IDEA。
- 非对称加密
非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。RSA
- 摘要
摘要算法又称哈希/散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用 16 进制的字符串表示)。算法不可逆。
什么是 websocket
websocket 协议 HTML5 带来的新协议,相对于 http,它是一个持久连接的协议,它利用 http 协议完成握手,然后通过 TCP 连接通道发送消息,使用 websocket 协议可以实现服务器主动推送消息。
首先,客户端若要发起 websocket 连接,首先必须向服务器发送 http 请求以完成握手,请求行中的 path 需要使用 ws:开头的地址,请求头中要分别加入 upgrade、connection、Sec-WebSocket-Key、Sec-WebSocket-Version 标记
然后,服务器收到请求后,发现这是一个 websocket 协议的握手请求,于是响应行中包含 Switching Protocols,同时响应头中包含 upgrade、connection、Sec-WebSocket-Accept 标记
当客户端收到响应后即可完成握手,随后使用建立的 TCP 连接直接发送和接收消息。
webSocket 与传统的 http 有什么优势
参考答案:
当页面中需要观察实时数据的变化(比如聊天、k 线图)时,过去我们往往使用两种方式完成:
第一种是短轮询,即客户端每隔一段时间就向服务器发送消息,询问有没有新的数据
第二种是长轮询,发起一次请求询问服务器,服务器可以将该请求挂起,等到有新消息时再进行响应。响应后,客户端立即又发起一次请求,重复整个流程。
无论是哪一种方式,都暴露了 http 协议的弱点,即响应必须在请求之后发生,服务器是被动的,无法主动推送消息。而让客户端不断的发起请求又白白的占用了资源。
websocket 的出现就是为了解决这个问题,它利用 http 协议完成握手之后,就可以与服务器建立持久的连接,服务器可以在任何需要的时候,主动推送消息给客户端,这样占用的资源最少,同时实时性也最高。
如何劫持 https 的请求,提供思路
https 有防篡改的特点,只要浏览器证书验证过程是正确的,很难在用户不察觉的情况下进行攻击。但若能够更改浏览器的证书验证过程,便有机会实现 https 中间人攻击。
所以,要劫持 https,首先要伪造一个证书,并且要想办法让用户信任这个证书,可以有多种方式,比如病毒、恶意软件、诱导等。一旦证书被信任后,就可以利用普通中间人攻击的方式,使用伪造的证书进行攻击。
前端如何实现即时通讯?
短轮询。即客户端每隔一段时间就向服务器发送消息,询问有没有新的数据
长轮询,发起一次请求询问服务器,服务器可以将该请求挂起,等到有新消息时再进行响应。响应后,客户端立即又发起一次请求,重复整个流程。
websocket,握手完毕后会建立持久性的连接通道,随后服务器可以在任何时候推送新消息给客户端
怎样创建长连接
post 和 get 区别
从 http 协议的角度来说,GET 和 POST 它们都只是请求行中的第一个单词,除了语义不同,其实没有本质的区别。
之所以在实际开发中会产生各种区别,主要是因为浏览器的默认行为造成的。
受浏览器的影响,在实际开发中,GET 和 POST 有以下区别:
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST 请求的传递信息量是没有限制的,适合传输大量数据。
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用 GET 请求,至少不应该放到 path 中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示。
- GET 请求的地址可以被保存为浏览器书签,POST 不可以
HTTP 劫持、DNS 劫持与 XSS
http 劫持是指攻击者在客户端和服务器之间同时建立了连接通道,通过某种方式,让客户端请求发送到自己的服务器,然后自己就拥有了控制响应内容的能力,从而给客户端展示错误的信息,比如在页面中加入一些广告内容。
DNS 劫持是指攻击者劫持了 DNS 服务器,获得了修改 DNS 解析记录的权限,从而导致客户端请求的域名被解析到了错误的 IP 地址,攻击者通过这种方式窃取用户资料或破坏原有正常服务。
XSS 是指跨站脚本攻击。攻击者利用站点的漏洞,在表单提交时,在表单内容中加入一些恶意脚本,当其他正常用户浏览页面,而页面中刚好出现攻击者的恶意脚本时,脚本被执行,从而使得页面遭到破坏,或者用户信息被窃取。
要防范 XSS 攻击,需要在服务器端过滤脚本代码,将一些危险的元素和属性去掉或对元素进行 HTML 实体编码。
图片上传有哪些步骤,header 会有什么?
1、获取图片。通过<input type="file" accept="image/jpg, image/jpeg, image/png"> 获取图片文件、包括文件名、文件类型等信息
2、如果需要预览图片,常用的方法有两个,分别是 URL.createObjectURL() 和 FileReader 。
URL.createObjectURL() 静态方法会创建一个 DOMString,其中包含一个表示参数中给出的对象的 URL。这个 URL 的生命周期和创建它的窗口中的 document 绑定。这个新的 URL 对象表示指定的 File 对象或 Blob 对象。返回如:blob:http://localhost:3000/5d8033c6-95a8-427b-b29d-7812238b058b
FileReader 对象允许 Web 应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用 File 或 Blob 对象指定要读取的文件或数据。同理的,我们也可以通过 input.files[0] 获取到当前选中的图片的 File 对象。
const file = e.target.files![0];
const reader = new FileReader();
reader.addEventListener('load', function () {
console.log(reader.result);
}, false);
if (file) {
reader.readAsDataURL(file);
}
// 返回的是base64的图片
3、上传。把 form 标签的enctype设置为multipart/form-data,同时method必须为post方法。
multipart/form-data 表示:multipart 互联网上的混合资源,就是资源由多种元素组成,form-data 表示可以使用 HTML Forms 和 POST 方法上传文件,具体的定义可以参考 RFC 7578。
multipart/form-data 结构
看下 http 请求的消息体
- 请求头:
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryDCntfiXcSkPhS4PN 表示本次请求要上传文件,其中 boundary 表示分隔符,如果要上传多个表单项,就要使用 boundary 分割,每个表单项由———XXX 开始,以———XXX 结尾。
- 消息体- Form Data 部分
每一个表单项又由Content-Type和Content-Disposition组成。
Content-Disposition: form-data 为固定值,表示一个表单元素,name 表示表单元素的 名称,回车换行后面就是name的值,如果是上传文件就是文件的二进制内容。
Content-Type:表示当前的内容的 MIME 类型,是图片还是文本还是二进制数据。
简单请求和非简单请求
简单请求满足以下条件
- 请求方式为以下之一:HEAD、GET、POST
- 除了被用户代理自动设置的首部字段(例如
Connection,User-Agent)和在 Fetch 规范中定义为 禁用首部名称 的其他首部,允许人为设置的字段为 Fetch 规范定义的 对 CORS 安全的首部字段集合。该集合为::Accept、Accept-Language、Content-Language、Content-Type - Content-Type(仅限于 text/plain、multipart/form-data、application/x-www-form-urlencoded)
- 请求中的任意 XMLHttpRequest 对象均没有注册任何事件监听器;XMLHttpRequest 对象可以使用 XMLHttpRequest.upload 属性访问。
- 请求中没有使用 ReadableStream 对象。
非简单请求:非简单请求是那种对服务器有特殊要求的请求
- 使用了下面任一 HTTP 方法,PUT/DELETE/CONNECT/OPTIONS/TRACE/PATCH
- 人为设置了以下集合之外首部字段,即简单请求外的字段 - Content-Type 的值不属于下列之一,即 application/x-www-form-urlencoded、multipart/form-data、text/plain
cookie/sessionStorage/localStorage 的区别
cookie、sessionStorage、localStorage 都是保存本地数据的方式
其中,cookie 兼容性较好,所有浏览器均支持。浏览器针对 cookie 会有一些默认行为,比如当响应头中出现 set-cookie 字段时,浏览器会自动保存 cookie 的值;再比如,浏览器发送请求时,会附带匹配的 cookie 到请求头中。这些默认行为,使得 cookie 长期以来担任着维持登录状态的责任。与此同时,也正是因为浏览器的默认行为,给了恶意攻击者可乘之机,CSRF 攻击就是一个典型的利用 cookie 的攻击方式。虽然 cookie 不断的改进,但前端仍然需要另一种更加安全的保存数据的方式。
HTML5 新增了 sessionStorage 和 localStorage,前者用于保存会话级别的数据,后者用于更持久的保存数据。浏览器针对它们没有任何默认行为,这样一来,就把保存数据、读取数据的工作交给了前端开发者,这就让恶意攻击者难以针对登录状态进行攻击。
cookie 的大小是有限制的,一般浏览器会限制同一个域下的 cookie 总量为 4M,而 sessionStorage 和 localStorage 则没有限制
cookie 会与 domain、path 关联,而 sessionStorage 和 localStorage 只与 domain 关联
post 请求什么时候用 form data 什么时候用 request payload
form data 适合传递简单的键值对信息,由于传递的信息比较扁平,难以传递深层次嵌套的数据
request payload 适合传递任意格式的数据,包括单个数字、布尔、深层次嵌套的对象、数组等,但 request payload 不适合传递文件数据
在前后端分离的项目中,对于非文件数据的传递,都推荐使用 request payload 的形式,以传递最明确的数据类型和数据结构,而对于文件上传,则推荐使用传统的 form data
http 常见请求方法有哪些?
- GET,表示向服务器获取资源
- POST,表示向服务器提交信息,通常用于产生新的数据,比如注册
- PUT,表示希望修改服务器的数据,通常用于修改
- DELETE,表示希望删除服务器的数据
- OPTIONS,发生在跨域的预检请求中,表示客户端向服务器申请跨域提交
- TRACE,回显服务器收到的请求,主要用于测试和诊断
- CONNECT,用于建立连接管道,通常在代理场景中使用,网页中很少用到
列举优化网络性能方法
- 优化打包体积
利用一些工具压缩、混淆最终打包代码,减少包体积
- 多目标打包
利用一些打包插件,针对不同的浏览器打包出不同的兼容性版本,这样一来,每个版本中的兼容性代码就会大大减少,从而减少包体积
- 压缩
现代浏览器普遍支持压缩格式,因此服务端的各种文件可以压缩后再响应给客户端,只要解压时间小于优化的传输时间,压缩就是可行的
- CDN
利用 CDN 可以大幅缩减静态资源的访问时间,特别是对于公共库的访问,可以使用知名的 CDN 资源,这样可以实现跨越站点的缓存
- 缓存
对于除 HTML 外的所有静态资源均可以开启协商缓存,利用构建工具打包产生的文件 hash 值来置换缓存
- http2
开启 http2 后,利用其多路复用、头部压缩等特点,充分利用带宽传递大量的文件数据
- 雪碧图
对于不使用 HTTP2 的场景,可以将多个图片合并为雪碧图,以达到减少文件的目的
- defer、async
通过 defer 和 async 属性,可以让页面尽早加载 js 文件
- prefetch、preload
通过 prefetch 属性,可以让页面在空闲时预先下载其他页面可能要用到的资源
通过 preload 属性,可以让页面预先下载本页面可能要用到的资源
- 多个静态资源域
对于不使用 HTTP2 的场景,将相对独立的静态资源分到多个域中保存,可以让浏览器同时开启多个 TCP 连接,并行下载
跨域如何带上 cookie
1.在客户端将 withCredentials 设置为 true
// 当发送跨域请求时,携带cookie信息
xhr.withCredentials = true;
2.res.header('Access-Control-Allow-Credentials', true);
// 拦截所有请求
app.use((req, res, next) => {
// 1.允许哪些客户端访问我
// * 代表允许所有的客户端访问我
// 注意:如果跨域请求中涉及到cookie信息传递,值不可以为*号 比如是具体的域名信息
res.header("Access-Control-Allow-Origin", "http://localhost:3000");
// 2.允许客户端使用哪些请求方法访问我
res.header("Access-Control-Allow-Methods", "get,post");
// 允许客户端发送跨域请求时携带cookie信息
res.header("Access-Control-Allow-Credentials", true);
next();
});
http3.0 做了哪些改进?
QUIC 协议
HTTP/3 基于 UDP 协议实现了类似于 TCP 的多路复用数据流、传输可靠性等功能,这套功能被称为 QUIC 协议。
- 流量控制、传输可靠性功能:QUIC 在 UDP 的基础上增加了一层来保证数据传输可靠性,它提供了数据包重传、拥塞控制、以及其他一些 TCP 中的特性。
- TLS 加密功能:目前 QUIC 使用 TLS1.3,减少了握手所花费的 RTT 数。
- 多路复用:同一物理连接上可以有多个独立的逻辑数据流,实现了数据流的单独传输,解决了 TCP 的队头阻塞问题。
- 快速握手:由于基于 UDP,可以实现使用 0 ~ 1 个 RTT 来建立连接。
HTTP/3.0 的挑战
- 服务器和浏览器端都没有对 HTTP/3 提供比较完整的支持。
- 系统内核对 UDP 的优化远达不到 TCP 的优化程度。
- 设备僵化问题,这些设备对 UDP 的优化程度远低于 TCP,据统计使用 QUIC 协议时,大约有 3% ~ 7%的丢包率。
鉴权有了解么,jwt 如何实现踢人,session 和 jwt 鉴权的区别
基于 session 的认证流程
用户在浏览器中输入用户名和密码,服务器通过密码校验后生成一个 session 并保存到数据库
服务器为用户生成一个 sessionId,并将具有 sesssionId 的 cookie 放置在用户浏览器中,在后续的请求中都将带有这个 cookie 信息进行访问
服务器获取 cookie,通过获取 cookie 中的 sessionId 查找数据库判断当前请求是否有效
基于 JWT 的认证流程
用户在浏览器中输入用户名和密码,服务器通过密码校验后生成一个 token 并保存到数据库
前端获取到 token,存储到 cookie 或者 local storage 中,在后续的请求中都将带有这个 token 信息进行访问
服务器获取 token 值,通过查找数据库判断当前 token 是否有效
优缺点 JWT 保存在客户端,在分布式环境下不需要做额外工作。而 session 因为保存在服务端,分布式环境下需要实现多机数据共享 session 一般需要结合 Cookie 实现认证,所以需要浏览器支持 cookie,因此移动端无法使用 session 认证方案
安全性 JWT 的 payload 使用的是 base64 编码的,因此在 JWT 中不能存储敏感数据。而 session 的信息是存在服务端的,相对来说更安全
性能 经过编码之后 JWT 将非常长,cookie 的限制大小一般是 4k,cookie 很可能放不下,所以 JWT 一般放在 local storage 里面。并且用户在系统中的每一次 http 请求都会把 JWT 携带在 Header 里面,HTTP 请求的 Header 可能比 Body 还要大。而 sessionId 只是很短的一个字符串,因此使用 JWT 的 HTTP 请求比使用 session 的开销大得多
一次性 无状态是 JWT 的特点,但也导致了这个问题,JWT 是一次性的。想修改里面的内容,就必须签发一个新的 JWT
无法废弃 一旦签发一个 JWT,在到期之前就会始终有效,无法中途废弃。若想废弃,一种常用的处理手段是结合 redis
续签 如果使用 JWT 做会话管理,传统的 cookie 续签方案一般都是框架自带的,session 有效期 30 分钟,30 分钟内如果有访问,有效期被刷新至 30 分钟。一样的道理,要改变 JWT 的有效时间,就要签发新的 JWT。
最简单的一种方式是每次请求刷新 JWT,即每个 HTTP 请求都返回一个新的 JWT。这个方法不仅暴力不优雅,而且每次请求都要做 JWT 的加密解密,会带来性能问题。另一种方法是在 redis 中单独为每个 JWT 设置过期时间,每次访问时刷新 JWT 的过期时间
选择 JWT 或 session JWT 有很多缺点,但是在分布式环境下不需要像 session 一样额外实现多机数据共享,虽然 seesion 的多机数据共享可以通过粘性 session、session 共享、session 复制、持久化 session、terracoa 实现 seesion 复制等多种成熟的方案来解决这个问题。但是 JWT 不需要额外的工作,使用 JWT 不香吗?并且 JWT 一次性的缺点可以结合 redis 进行弥补
DNS 解析过程
DNS 域名解析是指把域名解析成 IP 地址的过程。
在具体的实现上,域名解析是由多个层级的服务器共同完成的。在查询域名时,客户端会先检查自身的 DNS 映射表,若找不到解析记录,则使用用户配置的 DNS 服务器,若目标 DNS 服务器中找不到记录,则继续往上一个层级寻找,直到到达根域名服务器,根域名服务器会根据域名的类型,将解析任务分发到对应的子域名服务器依次查找,直到找到解析记录为止。
浏览器
从输入一个 url 到完成渲染的全过程(在浏览器地址栏输入地址,并按下回车键后,发生了哪些事情?)
先梳理下主干流程:
1. 从浏览器接收url到开启网络请求线程(这一部分可以展开浏览器的机制以及进程与线程之间的关系)
2. 开启网络线程到发出一个完整的http请求(这一部分涉及到dns查询,tcp/ip请求,五层因特网协议栈等知识)
3. 从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
4. 后台和前台的http交互(这一部分包括http头部、响应码、报文结构、cookie等知识,可以提下静态资源的cookie优化,以及编码解码,如gzip压缩等)
5. 单独拎出来的缓存问题,http的缓存(这部分包括http缓存头部,etag,catch-control等)
6. 浏览器接收到http数据包后的解析流程(解析html-词法分析然后解析成dom树、解析css生成css规则树、合并成render树,然后layout、painting渲染、复合图层的合成、GPU绘制、外链资源的处理、loaded和domcontentloaded等)
7. CSS的可视化格式模型(元素的渲染规则,如包含块,控制框,BFC,IFC等概念)
8. JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
9. 其它(可以拓展不同的知识模块,如跨域,web安全,hybrid模式等等内容)
从浏览器接收 url 到开启网络请求线程
这一部分展开的内容是:浏览器进程/线程模型,JS 的运行机制
多进程的浏览器
浏览器是多进程的,有一个主控进程,以及每一个 tab 页面都会新开一个进程(某些情况下多个 tab 会合并进程)
进程可能包括主控进程,插件进程,GPU,tab 页(浏览器内核)等等
- Browser 进程:浏览器的主进程(负责协调、主控),只有一个
- 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
- GPU 进程:最多一个,用于 3D 绘制
- 浏览器渲染进程(内核):默认每个 Tab 页面一个进程,互不影响,控制页面渲染,脚本执行,事件处理等(有时候会优化,如多个空白 tab 会合并成一个进程)
如下图:
多线程的浏览器内核
每一个 tab 页面可以看作是浏览器内核进程,然后这个进程是多线程的,它有几大类子线程
- GUI 线程
- JS 引擎线程
- 事件触发线程
- 定时器线程
- 网络请求线程
可以看到,里面的 JS 引擎是内核进程中的一个线程,这也是为什么常说 JS 引擎是单线程的
解析 URL
输入 URL 后,会进行解析(URL 的本质就是统一资源定位符)
URL 一般包括几大部分:
protocol,协议头,譬如有 http,ftp 等host,主机域名或 IP 地址port,端口号path,目录路径query,即查询参数fragment,即#后的 hash 值,一般用来定位到某个位置
网络请求都是单独的线程
每次网络请求时都需要开辟单独的线程进行,譬如如果 URL 解析到 http 协议,就会新建一个网络线程去处理资源下载
因此浏览器会根据解析出得协议,开辟一个网络线程,前往请求资源(这里,暂时理解为是浏览器内核开辟的,如有错误,后续修复)
开启网络线程到发出一个完整的 http 请求
这一部分主要内容包括:dns查询,tcp/ip请求构建,五层因特网协议栈等等
仍然是先梳理主干,有些详细的过程不展开(因为展开的话内容过多)
DNS 查询得到 IP
如果输入的是域名,需要进行 dns 解析成 IP,大致流程:
- 如果浏览器有缓存,直接使用浏览器缓存,否则使用本机缓存,再没有的话就是用 host
- 如果本地没有,就向 dns 域名服务器查询(当然,中间可能还会经过路由,也有缓存等),查询到对应的 IP
注意,域名查询时有可能是经过了 CDN 调度器的(如果有 cdn 存储功能的话)
而且,需要知道 dns 解析是很耗时的,因此如果解析域名过多,会让首屏加载变得过慢,可以考虑dns-prefetch优化
这一块可以深入展开,具体请去网上搜索,这里就不占篇幅了(网上可以看到很详细的解答)
tcp/ip 请求
http 的本质就是tcp/ip请求
需要了解 3 次握手规则建立连接以及断开连接时的四次挥手
tcp 将 http 长报文划分为短报文,通过三次握手与服务端建立连接,进行可靠传输
三次握手的步骤:(抽象派)
客户端:hello,你是server么?
服务端:hello,我是server,你是client么
客户端:yes,我是client
建立连接成功后,接下来就正式传输数据
然后,待到断开连接时,需要进行四次挥手(因为是全双工的,所以需要四次挥手)
四次挥手的步骤:(抽象派)
主动方:我已经关闭了向你那边的主动通道了,只能被动接收了
被动方:收到通道关闭的信息
被动方:那我也告诉你,我这边向你的主动通道也关闭了
主动方:最后收到数据,之后双方无法通信
tcp/ip 的并发限制
浏览器对同一域名下并发的 tcp 连接是有限制的(2-10 个不等)
而且在 http1.0 中往往一个资源下载就需要对应一个 tcp/ip 请求
所以针对这个瓶颈,又出现了很多的资源优化方案
get 和 post 的区别
get 和 post 虽然本质都是 tcp/ip,但两者除了在 http 层面外,在 tcp/ip 层面也有区别。
get 会产生一个 tcp 数据包,post 两个
具体就是:
- get 请求时,浏览器会把
headers和data一起发送出去,服务器响应 200(返回数据), - post 请求时,浏览器先发送
headers,服务器响应100 continue, 浏览器再发送data,服务器响应 200(返回数据)。
再说一点,这里的区别是specification(规范)层面,而不是implementation(对规范的实现)
五层因特网协议栈
其实这个概念挺难记全的,记不全没关系,但是要有一个整体概念
其实就是一个概念: 从客户端发出 http 请求到服务器接收,中间会经过一系列的流程。
简括就是:
从应用层的发送 http 请求,到传输层通过三次握手建立 tcp/ip 连接,再到网络层的 ip 寻址,再到数据链路层的封装成帧,最后到物理层的利用物理介质传输。
当然,服务端的接收就是反过来的步骤
五层因特网协议栈其实就是:
1.应用层(dns,http) DNS解析成IP并发送http请求
2.传输层(tcp,udp) 建立tcp连接(三次握手)
3.网络层(IP,ARP) IP寻址
4.数据链路层(PPP) 封装成帧
5.物理层(利用物理介质传输比特流) 物理传输(然后传输的时候通过双绞线,电磁波等各种介质)
当然,其实也有一个完整的 OSI 七层框架,与之相比,多了会话层、表示层。
OSI 七层框架:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层
表示层:主要处理两个通信系统中交换信息的表示方式,包括数据格式交换,数据加密与解密,数据压缩与终端类型转换等
会话层:它具体管理不同用户和进程之间的对话,如控制登陆和注销过程
从服务器接收到请求到对应后台接收到请求
服务端在接收到请求时,内部会进行很多的处理
这里由于不是专业的后端分析,所以只是简单的介绍下,不深入
负载均衡
对于大型的项目,由于并发访问量很大,所以往往一台服务器是吃不消的,所以一般会有若干台服务器组成一个集群,然后配合反向代理实现负载均衡
当然了,负载均衡不止这一种实现方式,这里不深入...
简单的说:
用户发起的请求都指向调度服务器(反向代理服务器,譬如安装了 nginx 控制负载均衡),然后调度服务器根据实际的调度算法,分配不同的请求给对应集群中的服务器执行,然后调度器等待实际服务器的 HTTP 响应,并将它反馈给用户
后台的处理
一般后台都是部署到容器中的,所以一般为:
- 先是容器接受到请求(如 tomcat 容器)
- 然后对应容器中的后台程序接收到请求(如 java 程序)
- 然后就是后台会有自己的统一处理,处理完后响应响应结果
概括下:
- 一般有的后端是有统一的验证的,如安全拦截,跨域验证
- 如果这一步不符合规则,就直接返回了相应的 http 报文(如拒绝请求等)
- 然后当验证通过后,才会进入实际的后台代码,此时是程序接收到请求,然后执行(譬如查询数据库,大量计算等等)
- 等程序执行完毕后,就会返回一个 http 响应包(一般这一步也会经过多层封装)
- 然后就是将这个包从后端发送到前端,完成交互
后台和前台的 http 交互
前后端交互时,http 报文作为信息的载体
所以 http 是一块很重要的内容,这一部分重点介绍它
http 报文结构
报文一般包括了:通用头部,请求/响应头部,请求/响应体
通用头部
这也是开发人员见过的最多的信息,包括如下:
Request Url: 请求的web服务器地址
Request Method: 请求方式
(Get、POST、OPTIONS、PUT、HEAD、DELETE、CONNECT、TRACE)
Status Code: 请求的返回状态码,如200代表成功
Remote Address: 请求的远程服务器地址(会转为IP)
譬如,在跨域拒绝时,可能是 method 为options,状态码为404/405等(当然,实际上可能的组合有很多)
其中,Method 的话一般分为两批次:
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
以及几种Additional Request Methods:PUT、DELETE、LINK、UNLINK
HTTP1.1定义了八种请求方法:GET、POST、HEAD、OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP 1.0定义参考:tools.ietf.org/html/rfc194…
HTTP 1.1定义参考:tools.ietf.org/html/rfc261…
这里面最常用到的就是状态码,很多时候都是通过状态码来判断,如(列举几个最常见的):
200——表明该请求被成功地完成,所请求的资源发送回客户端
304——自从上次请求后,请求的网页未修改过,请客户端使用本地缓存
400——客户端请求有错(譬如可以是安全模块拦截)
401——请求未经授权
403——禁止访问(譬如可以是未登录时禁止)
404——资源未找到
500——服务器内部错误
503——服务不可用
...
再列举下大致不同范围状态的意义
1xx——指示信息,表示请求已接收,继续处理
2xx——成功,表示请求已被成功接收、理解、接受
3xx——重定向,要完成请求必须进行更进一步的操作
4xx——客户端错误,请求有语法错误或请求无法实现
5xx——服务器端错误,服务器未能实现合法的请求
总之,当请求出错时,状态码能帮助快速定位问题,完整版本的状态可以自行去互联网搜索
请求/响应头部
请求和响应头部也是分析时常用到的
常用的请求头部(部分):
Accept: 接收类型,表示浏览器支持的MIME类型
(对标服务端返回的Content-Type)
Accept-Encoding:浏览器支持的压缩类型,如gzip等,超出类型不能接收
Content-Type:客户端发送出去实体内容的类型
Cache-Control: 指定请求和响应遵循的缓存机制,如no-cache
If-Modified-Since:对应服务端的Last-Modified,用来匹配看文件是否变动,只能精确到1s之内,http1.0中
Expires:缓存控制,在这个时间内不会请求,直接使用缓存,http1.0,而且是服务端时间
Max-age:代表资源在本地缓存多少秒,有效时间内不会请求,而是使用缓存,http1.1中
If-None-Match:对应服务端的ETag,用来匹配文件内容是否改变(非常精确),http1.1中
Cookie: 有cookie并且同域访问时会自动带上
Connection: 当浏览器与服务器通信时对于长连接如何进行处理,如keep-alive
Host:请求的服务器URL
Origin:最初的请求是从哪里发起的(只会精确到端口),Origin比Referer更尊重隐私
Referer:该页面的来源URL(适用于所有类型的请求,会精确到详细页面地址,csrf拦截常用到这个字段)
User-Agent:用户客户端的一些必要信息,如UA头部等
常用的响应头部(部分):
Access-Control-Allow-Headers: 服务器端允许的请求Headers
Access-Control-Allow-Methods: 服务器端允许的请求方法
Access-Control-Allow-Origin: 服务器端允许的请求Origin头部(譬如为*)
Content-Type:服务端返回的实体内容的类型
Date:数据从服务器发送的时间
Cache-Control:告诉浏览器或其他客户,什么环境可以安全的缓存文档
Last-Modified:请求资源的最后修改时间
Expires:应该在什么时候认为文档已经过期,从而不再缓存它
Max-age:客户端的本地资源应该缓存多少秒,开启了Cache-Control后有效
ETag:请求变量的实体标签的当前值
Set-Cookie:设置和页面关联的cookie,服务器通过这个头部把cookie传给客户端
Keep-Alive:如果客户端有keep-alive,服务端也会有响应(如timeout=38)
Server:服务器的一些相关信息
一般来说,请求头部和响应头部是匹配分析的。
譬如,请求头部的Accept要和响应头部的Content-Type匹配,否则会报错
譬如,跨域请求时,请求头部的Origin要匹配响应头部的Access-Control-Allow-Origin,否则会报跨域错误
譬如,在使用缓存时,请求头部的If-Modified-Since、If-None-Match分别和响应头部的Last-Modified、ETag对应
还有很多的分析方法,这里不一一赘述
请求/响应实体
http 请求时,除了头部,还有消息实体,一般来说
请求实体中会将一些需要的参数都放入进入(用于 post 请求)。
譬如实体中可以放参数的序列化形式(a=1&b=2这种),或者直接放表单对象(Form Data对象,上传时可以夹杂参数以及文件),等等
而一般响应实体中,就是放服务端需要传给客户端的内容
一般现在的接口请求时,实体中就是对于的信息的 json 格式,而像页面请求这种,里面就是直接放了一个 html 字符串,然后浏览器自己解析并渲染。
CRLF
CRLF(Carriage-Return Line-Feed),意思是回车换行,一般作为分隔符存在
请求头和实体消息之间有一个 CRLF 分隔,响应头部和响应实体之间用一个 CRLF 分隔
一般来说(分隔符类别):
CRLF->Windows-style
LF->Unix Style
CR->Mac Style
如下图是对某请求的 http 报文结构的简要分析
cookie 以及优化
cookie 是浏览器的一种本地存储方式,一般用来帮助客户端和服务端通信的,常用来进行身份校验,结合服务端的 session 使用。
场景如下(简述):
在登陆页面,用户登陆了
此时,服务端会生成一个session,session中有对于用户的信息(如用户名、密码等)
然后会有一个sessionid(相当于是服务端的这个session对应的key)
然后服务端在登录页面中写入cookie,值就是:jsessionid=xxx
然后浏览器本地就有这个cookie了,以后访问同域名下的页面时,自动带上cookie,自动检验,在有效时间内无需二次登陆。
上述就是 cookie 的常用场景简述(当然了,实际情况下得考虑更多因素)
一般来说,cookie 是不允许存放敏感信息的(千万不要明文存储用户名、密码),因为非常不安全,如果一定要强行存储,首先,一定要在 cookie 中设置httponly(这样就无法通过 js 操作了),另外可以考虑 rsa 等非对称加密(因为实际上,浏览器本地也是容易被攻克的,并不安全)
另外,由于在同域名的资源请求时,浏览器会默认带上本地的 cookie,针对这种情况,在某些场景下是需要优化的。
譬如以下场景:
客户端在域名A下有cookie(这个可以是登陆时由服务端写入的)
然后在域名A下有一个页面,页面中有很多依赖的静态资源(都是域名A的,譬如有20个静态资源)
此时就有一个问题,页面加载,请求这些静态资源时,浏览器会默认带上cookie
也就是说,这20个静态资源的http请求,每一个都得带上cookie,而实际上静态资源并不需要cookie验证
此时就造成了较为严重的浪费,而且也降低了访问速度(因为内容更多了)
当然了,针对这种场景,是有优化方案的(多域名拆分)。具体做法就是:
- 将静态资源分组,分别放到不同的域名下(如
static.base.com) - 而
page.base.com(页面所在域名)下请求时,是不会带上static.base.com域名的 cookie 的,所以就避免了浪费
说到了多域名拆分,这里再提一个问题,那就是:
- 在移动端,如果请求的域名数过多,会降低请求速度(因为域名整套解析流程是很耗费时间的,而且移动端一般带宽都比不上 pc)
- 此时就需要用到一种优化方案:
dns-prefetch(让浏览器空闲时提前解析 dns 域名,不过也请合理使用,勿滥用)
关于 cookie 的交互,可以看下图总结
gzip 压缩
首先,明确gzip是一种压缩格式,需要浏览器支持才有效(不过一般现在浏览器都支持), 而且 gzip 压缩效率很好(高达 70%左右)
然后 gzip 一般是由apache、tomcat等 web 服务器开启
当然服务器除了 gzip 外,也还会有其它压缩格式(如 deflate,没有 gzip 高效,且不流行)
所以一般只需要在服务器上开启了 gzip 压缩,然后之后的请求就都是基于 gzip 压缩格式的, 非常方便。
长连接与短连接
首先看tcp/ip层面的定义:
- 长连接:一个 tcp/ip 连接上可以连续发送多个数据包,在 tcp 连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持(类似于心跳包)
- 短连接:通信双方有数据交互时,就建立一个 tcp 连接,数据发送完成后,则断开此 tcp 连接
然后在 http 层面:
http1.0中,默认使用的是短连接,也就是说,浏览器没进行一次 http 操作,就建立一次连接,任务结束就中断连接,譬如每一个静态资源请求时都是一个单独的连接- http1.1 起,默认使用长连接,使用长连接会有这一行
Connection: keep-alive,在长连接的情况下,当一个网页打开完成后,客户端和服务端之间用于传输 http 的 tcp 连接不会关闭,如果客户端再次访问这个服务器的页面,会继续使用这一条已经建立的连接
注意: keep-alive 不会永远保持,它有一个持续时间,一般在服务器中配置(如 apache),另外长连接需要客户端和服务器都支持时才有效
http 2.0
http2.0 不是 https,它相当于是 http 的下一代规范(譬如 https 的请求可以是 http2.0 规范的)
然后简述下 http2.0 与 http1.1 的显著不同点:
- http1.1 中,每请求一个资源,都是需要开启一个 tcp/ip 连接的,所以对应的结果是,每一个资源对应一个 tcp/ip 请求,由于 tcp/ip 本身有并发数限制,所以当资源一多,速度就显著慢下来
- http2.0 中,一个 tcp/ip 请求可以请求多个资源,也就是说,只要一次 tcp/ip 请求,就可以请求若干个资源,分割成更小的帧请求,速度明显提升。
所以,如果 http2.0 全面应用,很多 http1.1 中的优化方案就无需用到了(譬如打包成精灵图,静态资源多域名拆分等)
然后简述下 http2.0 的一些特性:
- 多路复用(即一个 tcp/ip 连接可以请求多个资源)
- 首部压缩(http 头部压缩,减少体积)
- 二进制分帧(在应用层跟传送层之间增加了一个二进制分帧层,改进传输性能,实现低延迟和高吞吐量)
- 服务器端推送(服务端可以对客户端的一个请求发出多个响应,可以主动通知客户端)
- 请求优先级(如果流被赋予了优先级,它就会基于这个优先级来处理,由服务器决定需要多少资源来处理该请求。)
https
https 就是安全版本的 http,譬如一些支付等操作基本都是基于 https 的,因为 http 请求的安全系数太低了。
简单来看,https 与 http 的区别就是: 在请求前,会建立 ssl 链接,确保接下来的通信都是加密的,无法被轻易截取分析
一般来说,如果要将网站升级成 https,需要后端支持(后端需要申请证书等),然后 https 的开销也比 http 要大(因为需要额外建立安全链接以及加密等),所以一般来说 http2.0 配合 https 的体验更佳(因为 http2.0 更快了)
一般来说,主要关注的就是 SSL/TLS 的握手流程,如下(简述):
1. 浏览器请求建立SSL链接,并向服务端发送一个随机数–Client random和客户端支持的加密方法,比如RSA加密,此时是明文传输。
2. 服务端从中选出一组加密算法与Hash算法,回复一个随机数–Server random,并将自己的身份信息以证书的形式发回给浏览器
(证书里包含了网站地址,非对称加密的公钥,以及证书颁发机构等信息)
3. 浏览器收到服务端的证书后
- 验证证书的合法性(颁发机构是否合法,证书中包含的网址是否和正在访问的一样),如果证书信任,则浏览器会显示一个小锁头,否则会有提示
- 用户接收证书后(不管信不信任),浏览会生产新的随机数–Premaster secret,然后证书中的公钥以及指定的加密方法加密`Premaster secret`,发送给服务器。
- 利用Client random、Server random和Premaster secret通过一定的算法生成HTTP链接数据传输的对称加密key-`session key`
- 使用约定好的HASH算法计算握手消息,并使用生成的`session key`对消息进行加密,最后将之前生成的所有信息发送给服务端。
4. 服务端收到浏览器的回复
- 利用已知的加解密方式与自己的私钥进行解密,获取`Premaster secret`
- 和浏览器相同规则生成`session key`
- 使用`session key`解密浏览器发来的握手消息,并验证Hash是否与浏览器发来的一致
- 使用`session key`加密一段握手消息,发送给浏览器
5. 浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,
之后所有的 https 通信数据将由之前浏览器生成的session key并利用对称加密算法进行加密
这里放一张图(来源:阮一峰-图解 SSL/TLS 协议)
单独拎出来的缓存问题,http 的缓存
前后端的 http 交互中,使用缓存能很大程度上的提升效率,而且基本上对性能有要求的前端项目都是必用缓存的
强缓存与弱缓存
缓存可以简单的划分成两种类型:强缓存(200 from cache)与协商缓存(304)
区别简述如下:
- 强缓存(
200 from cache)时,浏览器如果判断本地缓存未过期,就直接使用,无需发起 http 请求 - 协商缓存(
304)时,浏览器会向服务端发起 http 请求,然后服务端告诉浏览器文件未改变,让浏览器使用本地缓存
对于协商缓存,使用Ctrl + F5强制刷新可以使得缓存无效
但是对于强缓存,在未过期时,必须更新资源路径才能发起新的请求(更改了路径相当于是另一个资源了,这也是前端工程化中常用到的技巧)
缓存头部简述
上述提到了强缓存和协商缓存,那它们是怎么区分的呢?
答案是通过不同的 http 头部控制
先看下这几个头部:
If-None-Match/E-tag、If-Modified-Since/Last-Modified、Cache-Control/Max-Age、Pragma/Expires
这些就是缓存中常用到的头部,这里不展开。仅列举下大致使用。
属于强缓存控制的:
(http1.1)Cache-Control/Max-Age
(http1.0)Pragma/Expires
注意:Max-Age不是一个头部,它是Cache-Control头部的值
属于协商缓存控制的:
(http1.1)If-None-Match/E-tag
(http1.0)If-Modified-Since/Last-Modified
可以看到,上述有提到http1.1和http1.0,这些不同的头部是属于不同 http 时期的
再提一点,其实 HTML 页面中也有一个 meta 标签可以控制缓存方案-Pragma
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
不过,这种方案还是比较少用到,因为支持情况不佳,譬如缓存代理服务器肯定不支持,所以不推荐
头部的区别
首先明确,http 的发展是从 http1.0 到 http1.1
而在 http1.1 中,出了一些新内容,弥补了 http1.0 的不足。
http1.0 中的缓存控制:
Pragma:严格来说,它不属于专门的缓存控制头部,但是它设置no-cache时可以让本地强缓存失效(属于编译控制,来实现特定的指令,主要是因为兼容 http1.0,所以以前又被大量应用)Expires:服务端配置的,属于强缓存,用来控制在规定的时间之前,浏览器不会发出请求,而是直接使用本地缓存,注意,Expires 一般对应服务器端时间,如Expires:Fri, 30 Oct 1998 14:19:41If-Modified-Since/Last-Modified:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-Modified-Since,而服务端的是Last-Modified,它的作用是,在发起请求时,如果If-Modified-Since和Last-Modified匹配,那么代表服务器资源并未改变,因此服务端不会返回资源实体,而是只返回头部,通知浏览器可以使用本地缓存。Last-Modified,顾名思义,指的是文件最后的修改时间,而且只能精确到1s以内
http1.1 中的缓存控制:
Cache-Control:缓存控制头部,有 no-cache、max-age 等多种取值Max-Age:服务端配置的,用来控制强缓存,在规定的时间之内,浏览器无需发出请求,直接使用本地缓存,注意,Max-Age 是 Cache-Control 头部的值,不是独立的头部,譬如Cache-Control: max-age=3600,而且它值得是绝对时间,由浏览器自己计算If-None-Match/E-tag:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-None-Match,而服务端的是E-tag,同样,发出请求后,如果If-None-Match和E-tag匹配,则代表内容未变,通知浏览器使用本地缓存,和 Last-Modified 不同,E-tag 更精确,它是类似于指纹一样的东西,基于FileEtag INode Mtime Size生成,也就是说,只要文件变,指纹就会变,而且没有 1s 精确度的限制。
Max-Age 相比 Expires?
Expires使用的是服务器端的时间
但是有时候会有这样一种情况-客户端时间和服务端不同步
那这样,可能就会出问题了,造成了浏览器本地的缓存无用或者一直无法过期
所以一般 http1.1 后不推荐使用Expires
而Max-Age使用的是客户端本地时间的计算,因此不会有这个问题
因此推荐使用Max-Age。
注意,如果同时启用了Cache-Control与Expires,Cache-Control优先级高。
E-tag 相比 Last-Modified?
Last-Modified:
- 表明服务端的文件最后何时改变的
- 它有一个缺陷就是只能精确到 1s,
- 然后还有一个问题就是有的服务端的文件会周期性的改变,导致缓存失效
而E-tag:
- 是一种指纹机制,代表文件相关指纹
- 只有文件变才会变,也只要文件变就会变,
- 也没有精确时间的限制,只要文件一遍,立马 E-tag 就不一样了
如果同时带有E-tag和Last-Modified,服务端会优先检查E-tag
各大缓存头部的整体关系如下图
解析页面流程
前面有提到 http 交互,那么接下来就是浏览器获取到 html,然后解析,渲染
这部分很多都参考了网上资源,特别是图片,参考了来源中的文章
流程简述
浏览器内核拿到内容后,渲染步骤大致可以分为以下几步:
1. 解析 HTML,构建 DOM 树
2. 解析 CSS,生成 CSS 规则树
3. 合并 DOM 树和 CSS 规则,生成 render 树
4. 布局 render 树(Layout/reflow),负责各元素尺寸、位置的计算
5. 绘制 render 树(paint),绘制页面像素信息
6. 浏览器会将各层的信息发送给 GPU,GPU 会将各层合成(composite),显示在屏幕上
如下图:
HTML 解析,构建 DOM
整个渲染步骤中,HTML 解析是第一步。
简单的理解,这一步的流程是这样的:浏览器解析 HTML,构建 DOM 树。
但实际上,在分析整体构建时,却不能一笔带过,得稍微展开。
解析 HTML 到构建出 DOM 当然过程可以简述如下:
Bytes → characters → tokens → nodes → DOM
譬如假设有这样一个 HTML 页面:(以下部分的内容出自参考来源,修改了下格式)
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
浏览器的处理如下:
列举其中的一些重点过程:
1. Conversion转换:浏览器将获得的HTML内容(Bytes)基于他的编码转换为单个字符
2. Tokenizing分词:浏览器按照HTML规范标准将这些字符转换为不同的标记token。每个token都有自己独特的含义以及规则集
3. Lexing词法分析:分词的结果是得到一堆的token,此时把他们转换为对象,这些对象分别定义他们的属性和规则
4. DOM构建:因为HTML标记定义的就是不同标签之间的关系,这个关系就像是一个树形结构一样
例如:body对象的父节点就是HTML对象,然后段略p对象的父节点就是body对象
最后的 DOM 树如下:
生成 CSS 规则
同理,CSS 规则树的生成也是类似。简述为:
Bytes → characters → tokens → nodes → CSSOM
譬如style.css内容如下:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
那么最终的 CSSOM 树就是:
构建渲染树
当 DOM 树和 CSSOM 都有了后,就要开始构建渲染树了
一般来说,渲染树和 DOM 树相对应的,但不是严格意义上的一一对应
因为有一些不可见的 DOM 元素不会插入到渲染树中,如 head 这种不可见的标签或者display: none等
整体来说可以看图:
渲染
有了 render 树,接下来就是开始渲染,基本流程如下:
图中重要的四个步骤就是:
1. 计算 CSS 样式
2. 构建渲染树
3. 布局,主要定位坐标和大小,是否换行,各种 position overflow z-index 属性
4. 绘制,将图像绘制出来
然后,图中的线与箭头代表通过 js 动态修改了 DOM 或 CSS,导致了重新布局(Layout)或渲染(Repaint)
这里 Layout 和 Repaint 的概念是有区别的:
- Layout,也称为 Reflow,即回流。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树
- Repaint,即重绘。意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就可以了
回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流, 所以优化方案中一般都包括,尽量避免回流。
什么会引起回流?
1.页面渲染初始化
2.DOM结构改变,比如删除了某个节点
3.render树变化,比如减少了padding
4.窗口resize
5.最复杂的一种:获取某些属性,引发回流,
很多浏览器会对回流做优化,会等到数量足够时做一次批处理回流,
但是除了render树的直接变化,当获取一些属性时,浏览器为了获得正确的值也会触发回流,这样使得浏览器优化无效,包括
(1)offset(Top/Left/Width/Height)
(2) scroll(Top/Left/Width/Height)
(3) cilent(Top/Left/Width/Height)
(4) width,height
(5) 调用了getComputedStyle()或者IE的currentStyle
回流一定伴随着重绘,重绘却可以单独出现
所以一般会有一些优化方案,如:
- 减少逐项更改样式,最好一次性更改 style,或者将样式定义为 class 并一次性更新
- 避免循环操作 dom,创建一个 documentFragment 或 div,在它上面应用所有 DOM 操作,最后再把它添加到 window.document
- 避免多次读取 offset 等属性。无法避免则将它们缓存到变量
- 将复杂的元素绝对定位或固定定位,使得它脱离文档流,否则回流代价会很高
注意:改变字体大小会引发回流
再来看一个示例:
var s = document.body.style;
s.padding = "2px"; // 回流+重绘
s.border = "1px solid red"; // 再一次 回流+重绘
s.color = "blue"; // 再一次重绘
s.backgroundColor = "#ccc"; // 再一次 重绘
s.fontSize = "14px"; // 再一次 回流+重绘
// 添加node,再一次 回流+重绘
document.body.appendChild(document.createTextNode('abc!'));
简单层与复合层
上述中的渲染中止步于绘制,但实际上绘制这一步也没有这么简单,它可以结合复合层和简单层的概念来讲。
这里不展开,进简单介绍下:
- 可以认为默认只有一个复合图层,所有的 DOM 节点都是在这个复合图层下的
- 如果开启了硬件加速功能,可以将某个节点变成复合图层
- 复合图层之间的绘制互不干扰,由 GPU 直接控制
- 而简单图层中,就算是 absolute 等布局,变化时不影响整体的回流,但是由于在同一个图层中,仍然是会影响绘制的,因此做动画时性能仍然很低。而复合层是独立的,所以一般做动画推荐使用硬件加速
更多参考:
Chrome 中的调试
Chrome 的开发者工具中,Performance 中可以看到详细的渲染过程:
资源外链的下载
上面介绍了 html 解析,渲染流程。但实际上,在解析 html 时,会遇到一些资源连接,此时就需要进行单独处理了
简单起见,这里将遇到的静态资源分为一下几大类(未列举所有):
- CSS 样式资源
- JS 脚本资源
- img 图片类资源
遇到外链时的处理
当遇到上述的外链时,会单独开启一个下载线程去下载资源(http1.1 中是每一个资源的下载都要开启一个 http 请求,对应一个 tcp/ip 链接)
遇到 CSS 样式资源
CSS 资源的处理有几个特点:
- CSS 下载时异步,不会阻塞浏览器构建 DOM 树
- 但是会阻塞渲染,也就是在构建 render 时,会等到 css 下载解析完毕后才进行(这点与浏览器优化有关,防止 css 规则不断改变,避免了重复的构建)
- 有例外,
media query声明的 CSS 是不会阻塞渲染的
遇到 JS 脚本资源
JS 脚本资源的处理有几个特点:
- 阻塞浏览器的解析,也就是说发现一个外链脚本时,需等待脚本下载完成并执行后才会继续解析 HTML
- 浏览器的优化,一般现代浏览器有优化,在脚本阻塞时,也会继续下载其它资源(当然有并发上限),但是虽然脚本可以并行下载,解析过程仍然是阻塞的,也就是说必须这个脚本执行完毕后才会接下来的解析,并行下载只是一种优化而已
- defer 与 async,普通的脚本是会阻塞浏览器解析的,但是可以加上 defer 或 async 属性,这样脚本就变成异步了,可以等到解析完毕后再执行
注意,defer 和 async 是有区别的: defer 是延迟执行,而 async 是异步执行。
简单的说(不展开):
async是异步执行,异步下载完毕后就会执行,不确保执行顺序,一定在onload前,但不确定在DOMContentLoaded事件的前或后defer是延迟执行,在浏览器看起来的效果像是将脚本放在了body后面一样(虽然按规范应该是在DOMContentLoaded事件前,但实际上不同浏览器的优化效果不一样,也有可能在它后面)
遇到 img 图片类资源
遇到图片等资源时,直接就是异步下载,不会阻塞解析,下载完毕后直接用图片替换原有 src 的地方
loaded 和 domcontentloaded
简单的对比:
- DOMContentLoaded 事件触发时,仅当 DOM 加载完成,不包括样式表,图片(譬如如果有 async 加载的脚本就不一定完成)
- load 事件触发时,页面上所有的 DOM,样式表,脚本,图片都已经加载完成了
CSS 的可视化格式模型
这一部分内容很多参考《精通 CSS-高级 Web 标准解决方案》以及参考来源
前面提到了整体的渲染概念,但实际上文档树中的元素是按什么渲染规则渲染的,是可以进一步展开的,此部分内容即: CSS 的可视化格式模型
先了解:
- CSS 中规定每一个元素都有自己的盒子模型(相当于规定了这个元素如何显示)
- 然后可视化格式模型则是把这些盒子按照规则摆放到页面上,也就是如何布局
- 换句话说,盒子模型规定了怎么在页面里摆放盒子,盒子的相互作用等等
说到底: CSS 的可视化格式模型就是规定了浏览器在页面中如何处理文档树
关键字:
包含块(Containing Block)
控制框(Controlling Box)
BFC(Block Formatting Context)
IFC(Inline Formatting Context)
定位体系
浮动
...
另外,CSS 有三种定位机制:普通流,浮动,绝对定位,如无特别提及,下文中都是针对普通流中的
包含块(Containing Block)
一个元素的 box 的定位和尺寸,会与某一矩形框有关,这个框就称之为包含块。
元素会为它的子孙元素创建包含块,但是,并不是说元素的包含块就是它的父元素,元素的包含块与它的祖先元素的样式等有关系
譬如:
- 根元素是最顶端的元素,它没有父节点,它的包含块就是初始包含块
- static 和 relative 的包含块由它最近的块级、单元格或者行内块祖先元素的内容框(content)创建
- fixed 的包含块是当前可视窗口
- absolute 的包含块由它最近的 position 属性为
absolute、relative或者fixed的祖先元素创建- 如果其祖先元素是行内元素,则包含块取决于其祖先元素的
direction特性 - 如果祖先元素不是行内元素,那么包含块的区域应该是祖先元素的内边距边界
- 如果其祖先元素是行内元素,则包含块取决于其祖先元素的
控制框(Controlling Box)
块级元素和块框以及行内元素和行框的相关概念
块框:
- 块级元素会生成一个块框(
Block Box),块框会占据一整行,用来包含子 box 和生成的内容 - 块框同时也是一个块包含框(
Containing Box),里面要么只包含块框,要么只包含行内框(不能混杂),如果块框内部有块级元素也有行内元素,那么行内元素会被匿名块框包围
关于匿名块框的生成,示例:
<DIV>
Some text
<P>More text
</DIV>
div生成了一个块框,包含了另一个块框p以及文本内容Some text,此时Some text文本会被强制加到一个匿名的块框里面,被div生成的块框包含(其实这个就是IFC中提到的行框,包含这些行内框的这一行匿名块形成的框,行框和行内框不同)
换句话说:
如果一个块框在其中包含另外一个块框,那么我们强迫它只能包含块框,因此其它文本内容生成出来的都是匿名块框(而不是匿名行内框)
行内框:
- 一个行内元素生成一个行内框
- 行内元素能排在一行,允许左右有其它元素
关于匿名行内框的生成,示例:
<P>Some <EM>emphasized</EM> text</P>
P元素生成一个块框,其中有几个行内框(如EM),以及文本Some,text,此时会专门为这些文本生成匿名行内框
display 属性的影响
display的几个属性也可以影响不同框的生成:
block,元素生成一个块框inline,元素产生一个或多个的行内框inline-block,元素产生一个行内级块框,行内块框的内部会被当作块块来格式化,而此元素本身会被当作行内级框来格式化(这也是为什么会产生BFC)none,不生成框,不再格式化结构中,当然了,另一个visibility: hidden则会产生一个不可见的框
总结:
- 如果一个框里,有一个块级元素,那么这个框里的内容都会被当作块框来进行格式化,因为只要出现了块级元素,就会将里面的内容分块几块,每一块独占一行(出现行内可以用匿名块框解决)
- 如果一个框里,没有任何块级元素,那么这个框里的内容会被当成行内框来格式化,因为里面的内容是按照顺序成行的排列
BFC(Block Formatting Context)
FC(格式上下文)?
FC 即格式上下文,它定义框内部的元素渲染规则,比较抽象,譬如
FC像是一个大箱子,里面装有很多元素
箱子可以隔开里面的元素和外面的元素(所以外部并不会影响FC内部的渲染)
内部的规则可以是:如何定位,宽高计算,margin折叠等等
不同类型的框参与的 FC 类型不同,譬如块级框对应 BFC,行内框对应 IFC
注意,并不是说所有的框都会产生 FC,而是符合特定条件才会产生,只有产生了对应的 FC 后才会应用对应渲染规则
BFC 规则:
在块格式化上下文中
每一个元素左外边与包含块的左边相接触(对于从右到左的格式化,右外边接触右边)
即使存在浮动也是如此(所以浮动元素正常会直接贴近它的包含块的左边,与普通元素重合)
除非这个元素也创建了一个新的BFC
总结几点 BFC 特点:
- 内部
box在垂直方向,一个接一个的放置 - box 的垂直方向由
margin决定,属于同一个 BFC 的两个 box 间的 margin 会重叠 - BFC 区域不会与
float box重叠(可用于排版) - BFC 就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此
- 计算 BFC 的高度时,浮动元素也参与计算(不会浮动坍塌)
如何触发 BFC?
- 根元素
float属性不为noneposition为absolute或fixeddisplay为inline-block,flex,inline-flex,table,table-cell,table-captionoverflow不为visible
这里提下,display: table,它本身不产生 BFC,但是它会产生匿名框(包含display: table-cell的框),而这个匿名框产生 BFC
更多请自行网上搜索
IFC(Inline Formatting Context)
IFC 即行内框产生的格式上下文
IFC 规则
在行内格式化上下文中
框一个接一个地水平排列,起点是包含块的顶部。
水平方向上的 margin,border 和 padding 在框之间得到保留
框在垂直方向上可以以不同的方式对齐:它们的顶部或底部对齐,或根据其中文字的基线对齐
行框
包含那些框的长方形区域,会形成一行,叫做行框
行框的宽度由它的包含块和其中的浮动元素决定,高度的确定由行高度计算规则决定
行框的规则:
如果几个行内框在水平方向无法放入一个行框内,它们可以分配在两个或多个垂直堆叠的行框中(即行内框的分割)
行框在堆叠时没有垂直方向上的分割且永不重叠
行框的高度总是足够容纳所包含的所有框。不过,它可能高于它包含的最高的框(例如,框对齐会引起基线对齐)
行框的左边接触到其包含块的左边,右边接触到其包含块的右边。
结合补充下 IFC 规则:
浮动元素可能会处于包含块边缘和行框边缘之间
尽管在相同的行内格式化上下文中的行框通常拥有相同的宽度(包含块的宽度),它们可能会因浮动元素缩短了可用宽度,而在宽度上发生变化
同一行内格式化上下文中的行框通常高度不一样(如,一行包含了一个高的图形,而其它行只包含文本)
当一行中行内框宽度的总和小于包含它们的行框的宽,它们在水平方向上的对齐,取决于 `text-align` 特性
空的行内框应该被忽略
即不包含文本,保留空白符,margin/padding/border非0的行内元素,
以及其他常规流中的内容(比如,图片,inline blocks 和 inline tables),
并且不是以换行结束的行框,
必须被当作零高度行框对待
总结:
- 行内元素总是会应用 IFC 渲染规则
- 行内元素会应用 IFC 规则渲染,譬如
text-align可以用来居中等 - 块框内部,对于文本这类的匿名元素,会产生匿名行框包围,而行框内部就应用 IFC 渲染规则
- 行内框内部,对于那些行内元素,一样应用 IFC 渲染规则
- 另外,
inline-block,会在元素外层产生 IFC(所以这个元素是可以通过text-align水平居中的),当然,它内部则按照 BFC 规则渲染
相比 BFC 规则来说,IFC 可能更加抽象(因为没有那么条理清晰的规则和触发条件)
但总的来说,它就是行内元素自身如何显示以及在框内如何摆放的渲染规则,这样描述应该更容易理解
其它
当然还有有一些其它内容:
- 譬如常规流,浮动,绝对定位等区别
- 譬如浮动元素不包含在常规流中
- 譬如相对定位,绝对定位,
Fixed定位等区别 - 譬如
z-index的分层显示机制等
这里不一一展开,更多请参考:
JS 引擎解析过程
前面有提到遇到 JS 脚本时,会等到它的执行,实际上是需要引擎解析的,这里展开描述(介绍主干流程)
JS 的解释阶段
首先得明确: JS 是解释型语言,所以它无需提前编译,而是由解释器实时运行
引擎对 JS 的处理过程可以简述如下:
1. 读取代码,进行词法分析(Lexical analysis),然后将代码分解成词元(token)
2. 对词元进行语法分析(parsing),然后将代码整理成语法树(syntax tree)
3. 使用翻译器(translator),将代码转为字节码(bytecode)
4. 使用字节码解释器(bytecode interpreter),将字节码转为机器码
最终计算机执行的就是机器码。
为了提高运行速度,现代浏览器一般采用即时编译(JIT-Just In Time compiler)
即字节码只在运行时编译,用到哪一行就编译哪一行,并且把编译结果缓存(inline cache)
这样整个程序的运行速度能得到显著提升。
而且,不同浏览器策略可能还不同,有的浏览器就省略了字节码的翻译步骤,直接转为机器码(如 chrome 的 v8)
总结起来可以认为是: 核心的JIT编译器将源码编译成机器码运行
JS 的预处理阶段
上述将的是解释器的整体过程,这里再提下在正式执行 JS 前,还会有一个预处理阶段 (譬如变量提升,分号补全等)
预处理阶段会做一些事情,确保 JS 可以正确执行,这里仅提部分:
分号补全
JS 执行是需要分号的,但为什么以下语句却可以正常运行呢?
console.log('a')
console.log('b')
原因就是 JS 解释器有一个Semicolon Insertion规则,它会按照一定规则,在适当的位置补充分号
譬如列举几条自动加分号的规则:
- 当有换行符(包括含有换行符的多行注释),并且下一个
token没法跟前面的语法匹配时,会自动补分号。 - 当有
}时,如果缺少分号,会补分号。 - 程序源代码结束时,如果缺少分号,会补分号。
于是,上述的代码就变成了
console.log('a');
console.log('b');
所以可以正常运行
当然了,这里有一个经典的例子:
function b() {
return
{
a: 'a'
};
}
由于分号补全机制,所以它变成了:
function b() {
return;
{
a: 'a'
};
}
所以运行后是undefined
变量提升
一般包括函数提升和变量提升
譬如:
a = 1;
b();
function b() {
console.log('b');
}
var a;
经过变量提升后,就变成:
function b() {
console.log('b');
}
var a;
a = 1;
b();
这里没有展开,其实展开也可以牵涉到很多内容的
譬如可以提下变量声明,函数声明,形参,实参的优先级顺序,以及 es6 中 let 有关的临时死区等
JS 的执行阶段
此阶段的内容中的图片来源:深入理解 JavaScript 系列(10):JavaScript 核心(晋级高手必读篇)
解释器解释完语法规则后,就开始执行,然后整个执行流程中大致包含以下概念:
- 执行上下文,执行堆栈概念(如全局上下文,当前活动上下文)
- VO(变量对象)和 AO(活动对象)
- 作用域链
- this 机制等
这些概念如果深入讲解的话内容过多,因此这里仅提及部分特性
执行上下文简单解释
- JS 有
执行上下文) - 浏览器首次载入脚本,它将创建
全局执行上下文,并压入执行栈栈顶(不可被弹出) - 然后每进入其它作用域就创建对应的执行上下文并把它压入执行栈的顶部
- 一旦对应的上下文执行完毕,就从栈顶弹出,并将上下文控制权交给当前的栈。
- 这样依次执行(最终都会回到全局执行上下文)
譬如,如果程序执行完毕,被弹出执行栈,然后有没有被引用(没有形成闭包),那么这个函数中用到的内存就会被垃圾处理器自动回收
然后执行上下文与 VO,作用域链,this 的关系是:
每一个执行上下文,都有三个重要属性:
- 变量对象(
Variable object,VO) - 作用域链(
Scope chain) this
VO 与 AO
VO 是执行上下文的属性(抽象概念),但是只有全局上下文的变量对象允许通过 VO 的属性名称来间接访问(因为在全局上下文里,全局对象自身就是变量对象)
AO(activation object),当函数被调用者激活,AO 就被创建了
可以理解为:
- 在函数上下文中:
VO === AO - 在全局上下文中:
VO === this === global
总的来说,VO 中会存放一些变量信息(如声明的变量,函数,arguments参数等等)
作用域链
它是执行上下文中的一个属性,原理和原型链很相似,作用很重要。
譬如流程简述:
在函数上下文中,查找一个变量foo
如果函数的VO中找到了,就直接使用
否则去它的父级作用域链中(__parent__)找
如果父级中没找到,继续往上找
直到全局上下文中也没找到就报错
this 指针
这也是 JS 的核心知识之一,由于内容过多,这里就不展开,仅提及部分
注意:this 是执行上下文环境的一个属性,而不是某个变量对象的属性
因此:
- this 是没有一个类似搜寻变量的过程
- 当代码中使用了 this,这个 this 的值就直接从执行的上下文中获取了,而不会从作用域链中搜寻
- this 的值只取决中进入上下文时的情况
所以经典的例子:
var baz = 200;
var bar = {
baz: 100,
foo: function() {
console.log(this.baz);
}
};
var foo = bar.foo;
// 进入环境:global
foo(); // 200,严格模式中会报错,Cannot read property 'baz' of undefined
// 进入环境:global bar
bar.foo(); // 100
就要明白了上面 this 的介绍,上述例子很好理解
更多参考:
深入理解 JavaScript 系列(13):This? Yes,this!
回收机制
JS 有垃圾处理器,所以无需手动回收内存,而是由垃圾处理器自动处理。
一般来说,垃圾处理器有自己的回收策略。
譬如对于那些执行完毕的函数,如果没有外部引用(被引用的话会形成闭包),则会回收。(当然一般会把回收动作切割到不同的时间段执行,防止影响性能)
常用的两种垃圾回收规则是:
- 标记清除
- 引用计数
Javascript 引擎基础 GC 方案是(simple GC):mark and sweep(标记清除),简单解释如下:
- 遍历所有可访问的对象。
- 回收已不可访问的对象。
譬如:(出自 javascript 高程)
当变量进入环境时,例如,在函数中声明一个变量,就将这个变量标记为“进入环境”。
从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。
而当变量离开环境时,则将其标记为“离开环境”。
垃圾回收器在运行的时候会给存储在内存中的所有变量都加上标记(当然,可以使用任何标记方式)。
然后,它会去掉环境中的变量以及被环境中的变量引用的变量的标记(闭包,也就是说在环境中的以及相关引用的变量会被去除标记)。
而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。
最后,垃圾回收器完成内存清除工作,销毁那些带标记的值并回收它们所占用的内存空间。
关于引用计数,简单点理解:
跟踪记录每个值被引用的次数,当一个值被引用时,次数+1,减持时-1,下次垃圾回收器会回收次数为0的值的内存(当然了,容易出循环引用的 bug)
GC 的缺陷
和其他语言一样,javascript 的 GC 策略也无法避免一个问题: GC 时,停止响应其他操作
这是为了安全考虑。
而 Javascript 的 GC 在100ms甚至以上
对一般的应用还好,但对于 JS 游戏,动画对连贯性要求比较高的应用,就麻烦了。
这就是引擎需要优化的点: 避免 GC 造成的长时间停止响应。
GC 优化策略
这里介绍常用到的:分代回收(Generation GC)
目的是通过区分“临时”与“持久”对象:
- 多回收“临时对象”区(
young generation) - 少回收“持久对象”区(
tenured generation) - 减少每次需遍历的对象,从而减少每次 GC 的耗时。
像 node v8 引擎就是采用的分代回收(和 java 一样,作者是 java 虚拟机作者。)
更多可以参考:
其它
可以提到跨域
譬如发出网络请求时,会用 AJAX,如果接口跨域,就会遇到跨域问题
可以参考:
可以提到 web 安全
譬如浏览器在解析 HTML 时,有XSSAuditor,可以延伸到 web 安全相关领域
可以参考:
AJAX 请求真的不安全么?谈谈 Web 安全与 AJAX 的关系。
更多
如可以提到viewport概念,讲讲物理像素,逻辑像素,CSS 像素等概念
如熟悉 Hybrid 开发的话可以提及一下 Hybrid 相关内容以及优化
...
总结
上述这么多内容,目的是:梳理出自己的知识体系
本文由于是前端向,所以知识梳理时有重点,很多其它的知识点都简述或略去了,重点介绍的模块总结:
- 浏览器的进程/线程模型、JS 运行机制(这一块的详细介绍链接到了另一篇文章)
- http 规范(包括报文结构,头部,优化,http2.0,https 等)
- http 缓存(单独列出来,因为它很重要)
- 页面解析流程(HTML 解析,构建 DOM,生成 CSS 规则,构建渲染树,渲染流程,复合层的合成,外链的处理等)
- JS 引擎解析过程(包括解释阶段,预处理阶段,执行阶段,包括执行上下文、VO、作用域链、this、回收机制等)
- 跨域相关,web 安全单独链接到了具体文章,其它如 CSS 盒模型,viewport 等仅是提及概念
关于本文的价值?
本文是个人阶段性梳理知识体系的成果,然后加以修缮后发布成文章,因此并不确保适用于所有人员
但是,个人认为本文还是有一定参考价值的
怎样实现跨页面通信
1、LocalStorage
浏览器提供了一个事件 storage,当 localStorage 中的数据发生变化时,会触发这个事件,我们可以通过这个事件来监听数据的变化,从而实现跨页面通信。
2、SharedWorker
SharedWorker是可以在多个页面之间共享的Worker,它的特点是:
- 可以在多个页面之间共享
- 可以在多个页面之间通信
- 可以在多个页面之间共享数据
使用的时候只需要在页面中引入SharedWorker的脚本即可,然后通过new SharedWorker来创建一个SharedWorker实例,这个实例提供了一些方法,例如:
// 创建一个 SharedWorker 实例
const worker = new SharedWorker("worker.js");
// 向 SharedWorker 发送消息
worker.port.postMessage("hello");
// 监听 SharedWorker 的消息
worker.port.onmessage = function (e) {
console.log(e.data);
};
这里的worker.js就是我们的SharedWorker脚本,它提供了一些方法,例如:
// 监听 SharedWorker 的消息
onconnect = function (e) {
const port = e.ports[0];
port.onmessage = function (e) {
console.log(e.data);
// 向 port 发送消息
port.postMessage("world");
};
};
3、BroadcastChannel
使用的时候不需要任何的配置或者脚本,只需要通过new BroadcastChannel来创建一个BroadcastChannel实例,然后通过postMessage来向频道中发送消息,通过onmessage来监听频道中的消息;
// 创建一个 BroadcastChannel 实例
const channel = new BroadcastChannel("channel");
// 向频道中发送消息
channel.postMessage("hello");
// 监听频道中的消息
channel.onmessage = function (e) {
console.log(e.data);
};
4、window.open + window.opener
当我们使用window.open打开页面时,方法会返回一个被打开页面window的引用。而在未显示指定noopener时,被打开的页面可以通过window.opener获取到打开它的页面的引用 —— 通过这种方式我们就将这些页面建立起了联系(一种树形结构)。
5、IndexDB、Cookie
6、Service Worker
总结
今天和大家分享了一下跨页面通信的各种方式。
对于同源页面,常见的方式包括:
- 广播模式:Broadcast Channe / Service Worker / LocalStorage + StorageEvent
- 共享存储模式:Shared Worker / IndexedDB / cookie
- 口口相传模式:window.open + window.opener
- 基于服务端:Websocket / Comet / SSE 等
而对于非同源页面,则可以通过嵌入同源 iframe 作为“桥”,将非同源页面通信转换为同源页面通信。
怎样实现跨域
1.jsonp
- JSONP 原理
利用 <script> 标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的 JSON 数据。JSONP 请求一定需要对方的服务器做支持才可以。
- JSONP 和 AJAX 对比
JSONP 和 AJAX 相同,都是客户端向服务器端发送请求,从服务器端获取数据的方式。但 AJAX 属于同源策略,JSONP 属于非同源策略(跨域请求)
- JSONP 优缺点
JSONP 优点是简单兼容性好,可用于解决主流浏览器的跨域数据访问的问题。缺点是仅支持 get 方法具有局限性,不安全可能会遭受 XSS 攻击。
- JSONP 的实现流程
- 声明一个回调函数,其函数名(如 show)当做参数值,要传递给跨域请求数据的服务器,函数形参为要获取目标数据(服务器返回的 data)。
- 创建一个
<script>标签,把那个跨域的 API 数据接口地址,赋值给 script 的 src,还要在这个地址中向服务器传递该函数名(可以通过问号传参:?callback=show)。 - 服务器接收到请求后,需要进行特殊的处理:把传递进来的函数名和它需要给你的数据拼接成一个字符串,例如:传递进去的函数名是 show,它准备好的数据是
show('我不爱你')。 - 最后服务器把准备的数据通过 HTTP 协议返回给客户端,客户端再调用执行之前声明的回调函数(show),对返回的数据进行操作。
在开发中可能会遇到多个 JSONP 请求的回调函数名是相同的,这时候就需要自己封装一个 JSONP 函数。
// index.html
function jsonp({ url, params, callback }) {
return new Promise((resolve, reject) => {
let script = document.createElement("script");
window[callback] = function (data) {
resolve(data);
document.body.removeChild(script);
};
params = { ...params, callback }; // wd=b&callback=show
let arrs = [];
for (let key in params) {
arrs.push(`${key}=${params[key]}`);
}
script.src = `${url}?${arrs.join("&")}`;
document.body.appendChild(script);
});
}
jsonp({
url: "http://localhost:3000/say",
params: { wd: "Iloveyou" },
callback: "show",
}).then((data) => {
console.log(data);
});
上面这段代码相当于向http://localhost:3000/say?wd=Iloveyou&callback=show这个地址请求数据,然后后台返回show('我不爱你'),最后会运行 show()这个函数,打印出'我不爱你'
// server.js
let express = require("express");
let app = express();
app.get("/say", function (req, res) {
let { wd, callback } = req.query;
console.log(wd); // Iloveyou
console.log(callback); // show
res.end(`${callback}('我不爱你')`);
});
app.listen(3000);
- jQuery 的 jsonp 形式
JSONP 都是 GET 和异步请求的,不存在其他的请求方式和同步请求,且 jQuery 默认就会给 JSONP 的请求清除缓存。
$.ajax({
url:"http://crossdomain.com/jsonServerResponse",
dataType:"jsonp",
type:"get",//可以省略
jsonpCallback:"show",//->自定义传递给服务器的函数名,而不是使用jQuery自动生成的,可省略
jsonp:"callback",//->把传递函数名的那个形参callback,可省略
success:function (data){
console.log(data);}
});
2.cors
CORS 需要浏览器和后端同时支持。IE 8 和 9 需要通过 XDomainRequest 来实现。
浏览器会自动进行 CORS 通信,实现 CORS 通信的关键是后端。只要后端实现了 CORS,就实现了跨域。
服务端设置 Access-Control-Allow-Origin 就可以开启 CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
虽然设置 CORS 和前端没什么关系,但是通过这种方式解决跨域问题的话,会在发送请求时出现两种情况,分别为简单请求和复杂请求。
- 简单请求
只要同时满足以下两大条件,就属于简单请求
条件 1:使用下列方法之一:
- GET
- HEAD
- POST
条件 2:Content-Type 的值仅限于下列三者之一:
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
请求中的任意 XMLHttpRequestUpload 对象均没有注册任何事件监听器;
XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问。
2. 复杂请求
不符合以上条件的请求就肯定是复杂请求了。 复杂请求的 CORS 请求,会在正式通信之前,增加一次 HTTP 查询请求,称为"预检"请求,该请求是 option 方法的,通过该请求来知道服务端是否允许跨域请求。
我们用PUT向后台请求时,属于复杂请求,后台需做如下配置:
// 允许哪个方法访问我
res.setHeader('Access-Control-Allow-Methods', 'PUT')
// 预检的存活时间
res.setHeader('Access-Control-Max-Age', 6)
// OPTIONS请求不做任何处理
if (req.method === 'OPTIONS') {
res.end()
}
// 定义后台返回的内容
app.put('/getData', function(req, res) {
console.log(req.headers)
res.end('我不爱你')
})
接下来我们看下一个完整复杂请求的例子,并且介绍下 CORS 请求相关的字段
// index.html
let xhr = new XMLHttpRequest()
document.cookie = 'name=xiamen' // cookie不能跨域
xhr.withCredentials = true // 前端设置是否带cookie
xhr.open('PUT', 'http://localhost:4000/getData', true)
xhr.setRequestHeader('name', 'xiamen')
xhr.onreadystatechange = function() {
if (xhr.readyState === 4) {
if ((xhr.status >= 200 && xhr.status < 300) || xhr.status === 304) {
console.log(xhr.response)
//得到响应头,后台需设置Access-Control-Expose-Headers
console.log(xhr.getResponseHeader('name'))
}
}
}
xhr.send()
//server1.js
let express = require('express');
let app = express();
app.use(express.static(__dirname));
app.listen(3000);
//server2.js
let express = require('express')
let app = express()
let whitList = ['http://localhost:3000'] //设置白名单
app.use(function(req, res, next) {
let origin = req.headers.origin
if (whitList.includes(origin)) {
// 设置哪个源可以访问我
res.setHeader('Access-Control-Allow-Origin', origin)
// 允许携带哪个头访问我
res.setHeader('Access-Control-Allow-Headers', 'name')
// 允许哪个方法访问我
res.setHeader('Access-Control-Allow-Methods', 'PUT')
// 允许携带cookie
res.setHeader('Access-Control-Allow-Credentials', true)
// 预检的存活时间
res.setHeader('Access-Control-Max-Age', 6)
// 允许返回的头
res.setHeader('Access-Control-Expose-Headers', 'name')
if (req.method === 'OPTIONS') {
res.end() // OPTIONS请求不做任何处理
}
}
next()
})
app.put('/getData', function(req, res) {
console.log(req.headers)
res.setHeader('name', 'jw') //返回一个响应头,后台需设置
res.end('我不爱你')
})
app.get('/getData', function(req, res) {
console.log(req.headers)
res.end('我不爱你')
})
app.use(express.static(__dirname))
app.listen(4000)
上述代码由http://localhost:3000/index.html向http://localhost:4000/跨域请求,正如我们上面所说的,后端是实现 CORS 通信的关键。
3.postMessage
postMessage 是 HTML5 XMLHttpRequest Level 2 中的 API,且是为数不多可以跨域操作的 window 属性之一,它可用于解决以下方面的问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的 iframe 消息传递
- 上面三个场景的跨域数据传递
postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
otherWindow.postMessage(message, targetOrigin, [transfer]);
- message: 将要发送到其他 window 的数据。
- targetOrigin:通过窗口的 origin 属性来指定哪些窗口能接收到消息事件,其值可以是字符串"*"(表示无限制)或者一个 URI。在发送消息的时候,如果目标窗口的协议、主机地址或端口这三者的任意一项不匹配 targetOrigin 提供的值,那么消息就不会被发送;只有三者完全匹配,消息才会被发送。
- transfer(可选):是一串和 message 同时传递的 Transferable 对象. 这些对象的所有权将被转移给消息的接收方,而发送一方将不再保有所有权。
接下来我们看个例子: http://localhost:3000/a.html页面向http://localhost:4000/b.html传递“我爱你”,然后后者传回"我不爱你"。
// a.html
<iframe src="http://localhost:4000/b.html" frameborder="0" id="frame" onload="load()"></iframe> //等它加载完触发一个事件
//内嵌在http://localhost:3000/a.html
<script>
function load() {
let frame = document.getElementById('frame')
frame.contentWindow.postMessage('我爱你', 'http://localhost:4000') //发送数据
window.onmessage = function(e) { //接受返回数据
console.log(e.data) //我不爱你
}
}
</script>
// b.html
window.onmessage = function(e) {
console.log(e.data) //我爱你
e.source.postMessage('我不爱你', e.origin)
}
4.websocket
Websocket 是 HTML5 的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。WebSocket 和 HTTP 都是应用层协议,都基于 TCP 协议。但是 WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据。同时,WebSocket 在建立连接时需要借助 HTTP 协议,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了。
原生 WebSocket API 使用起来不太方便,我们使用Socket.io,它很好地封装了 webSocket 接口,提供了更简单、灵活的接口,也对不支持 webSocket 的浏览器提供了向下兼容。
我们先来看个例子:本地文件 socket.html 向localhost:3000发生数据和接受数据
// socket.html
<script>
let socket = new WebSocket('ws://localhost:3000');
socket.onopen = function () {
socket.send('我爱你');//向服务器发送数据
}
socket.onmessage = function (e) {
console.log(e.data);//接收服务器返回的数据
}
</script>
// server.js
let express = require('express');
let app = express();
let WebSocket = require('ws');//记得安装ws
let wss = new WebSocket.Server({port:3000});
wss.on('connection',function(ws) {
ws.on('message', function (data) {
console.log(data);
ws.send('我不爱你')
});
})
5. Node 中间件代理(两次跨域)
实现原理:同源策略是浏览器需要遵循的标准,而如果是服务器向服务器请求就无需遵循同源策略。 代理服务器,需要做以下几个步骤:
接受客户端请求 。
将请求 转发给服务器。
拿到服务器 响应 数据。
将 响应 转发给客户端。
我们先来看个例子:本地文件 index.html 文件,通过代理服务器http://localhost:3000向目标服务器http://localhost:4000请求数据。
// index.html(http://127.0.0.1:5500)
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script>
$.ajax({
url: 'http://localhost:3000',
type: 'post',
data: { name: 'xiamen', password: '123456' },
contentType: 'application/json;charset=utf-8',
success: function(result) {
console.log(result) // {"title":"fontend","password":"123456"}
},
error: function(msg) {
console.log(msg)
}
})
</script>
// server1.js 代理服务器(http://localhost:3000)
const http = require('http')
// 第一步:接受客户端请求
const server = http.createServer((request, response) => {
// 代理服务器,直接和浏览器直接交互,需要设置CORS 的首部字段
response.writeHead(200, {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': '*',
'Access-Control-Allow-Headers': 'Content-Type'
})
// 第二步:将请求转发给服务器
const proxyRequest = http
.request(
{
host: '127.0.0.1',
port: 4000,
url: '/',
method: request.method,
headers: request.headers
},
serverResponse => {
// 第三步:收到服务器的响应
var body = ''
serverResponse.on('data', chunk => {
body += chunk
})
serverResponse.on('end', () => {
console.log('The data is ' + body)
// 第四步:将响应结果转发给浏览器
response.end(body)
})
}
)
.end()
})
server.listen(3000, () => {
console.log('The proxyServer is running at http://localhost:3000')
})
// server2.js(http://localhost:4000)
const http = require('http')
const data = { title: 'fontend', password: '123456' }
const server = http.createServer((request, response) => {
if (request.url === '/') {
response.end(JSON.stringify(data))
}
})
server.listen(4000, () => {
console.log('The server is running at http://localhost:4000')
})
上述代码经过两次跨域,值得注意的是浏览器向代理服务器发送请求,也遵循同源策略,最后在 index.html 文件打印出{"title":"fontend","password":"123456"}
6.nginx 反向代理
实现原理类似于 Node 中间件代理,需要你搭建一个中转 nginx 服务器,用于转发请求。
使用 nginx 反向代理实现跨域,是最简单的跨域方式。只需要修改 nginx 的配置即可解决跨域问题,支持所有浏览器,支持 session,不需要修改任何代码,并且不会影响服务器性能。
实现思路:通过 nginx 配置一个代理服务器(域名与 domain1 相同,端口不同)做跳板机,反向代理访问 domain2 接口,并且可以顺便修改 cookie 中 domain 信息,方便当前域 cookie 写入,实现跨域登录。
先下载nginx,然后将 nginx 目录下的 nginx.conf 修改如下:
// proxy服务器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名
index index.html index.htm;
# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用
add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*
add_header Access-Control-Allow-Credentials true;
}
}
最后通过命令行nginx -s reload启动 nginx
// index.html
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问nginx中的代理服务器
xhr.open('get', 'http://www.domain1.com:81/?user=admin', true);
xhr.send();
// server.js
var http = require('http');
var server = http.createServer();
var qs = require('querystring');
server.on('request', function(req, res) {
var params = qs.parse(req.url.substring(2));
// 向前台写cookie
res.writeHead(200, {
'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:脚本无法读取
});
res.write(JSON.stringify(params));
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
7.window.name + iframe
window.name 属性的独特之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
其中 a.html 和 b.html 是同域的,都是http://localhost:3000;而 c.html 是http://localhost:4000
// a.html(http://localhost:3000/b.html)
<iframe src="http://localhost:4000/c.html" frameborder="0" onload="load()" id="iframe"></iframe>
<script>
let first = true
// onload事件会触发2次,第1次加载跨域页,并留存数据于window.name
function load() {
if(first){
// 第1次onload(跨域页)成功后,切换到同域代理页面
let iframe = document.getElementById('iframe');
iframe.src = 'http://localhost:3000/b.html';
first = false;
}else{
// 第2次onload(同域b.html页)成功后,读取同域window.name中数据
console.log(iframe.contentWindow.name);
}
}
</script>
b.html 为中间代理页,与 a.html 同域,内容为空。
// c.html(http://localhost:4000/c.html)
<script>
window.name = '我不爱你'
</script>
总结:通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window.name 从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
8.location.hash + iframe
实现原理: a.html 欲与 c.html 跨域相互通信,通过中间页 b.html 来实现。 三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js 访问来通信。
具体实现步骤:一开始 a.html 给 c.html 传一个 hash 值,然后 c.html 收到 hash 值后,再把 hash 值传递给 b.html,最后 b.html 将结果放到 a.html 的 hash 值中。 同样的,a.html 和 b.html 是同域的,都是http://localhost:3000;而 c.html 是http://localhost:4000
// a.html
<iframe src="http://localhost:4000/c.html#iloveyou"></iframe>
<script>
window.onhashchange = function () { //检测hash的变化
console.log(location.hash);
}
</script>
// b.html
<script>
window.parent.parent.location.hash = location.hash
//b.html将结果放到a.html的hash值中,b.html可通过parent.parent访问a.html页面
</script>
// c.html
console.log(location.hash);
let iframe = document.createElement('iframe');
iframe.src = 'http://localhost:3000/b.html#idontloveyou';
document.body.appendChild(iframe);
9.document.domain + iframe
该方式只能用于二级域名相同的情况下,比如 a.test.com 和 b.test.com 适用于该方式。 只需要给页面添加 document.domain ='test.com' 表示二级域名都相同就可以实现跨域。
实现原理:两个页面都通过 js 强制设置 document.domain 为基础主域,就实现了同域。
我们看个例子:页面a.zf1.cn:3000/a.html获取页面b.zf1.cn:3000/b.html中 a 的值
// a.html
<body>
helloa
<iframe src="http://b.zf1.cn:3000/b.html" frameborder="0" onload="load()" id="frame"></iframe>
<script>
document.domain = 'zf1.cn'
function load() {
console.log(frame.contentWindow.a);
}
</script>
</body>
// b.html
<body>
hellob
<script>
document.domain = 'zf1.cn'
var a = 100;
</script>
</body>
总结
- CORS 支持所有类型的 HTTP 请求,是跨域 HTTP 请求的根本解决方案
- JSONP 只支持 GET 请求,JSONP 的优势在于支持老式浏览器,以及可以向不支持 CORS 的网站请求数据。
- 不管是 Node 中间件代理还是 nginx 反向代理,主要是通过同源策略对服务器不加限制。
- 日常工作中,用得比较多的跨域方案是 cors 和 nginx 反向代理
xss 和 csrf
- XSS:
XSS 是指跨站脚本攻击。攻击者利用站点的漏洞,在表单提交时,在表单内容中加入一些恶意脚本,当其他正常用户浏览页面,而页面中刚好出现攻击者的恶意脚本时,脚本被执行,从而使得页面遭到破坏,或者用户信息被窃取。
要防范 XSS 攻击,需要在服务器端过滤脚本代码,将一些危险的元素和属性去掉或对元素进行 HTML 实体编码。
- CSRF:
CSRF 是跨站请求伪造,是一种挟制用户在当前已登录的 Web 应用上执行非本意的操作的攻击方法
它首先引导用户访问一个危险网站,当用户访问网站后,网站会发送请求到被攻击的站点,这次请求会携带用户的 cookie 发送,因此就利用了用户的身份信息完成攻击。
其中 Web A 为存在 CSRF 漏洞的网站,Web B 为攻击者构建的恶意网站,User C 为 Web A 网站的合法用户。
CSRF 攻击攻击原理及过程如下:
1.用户 C 打开浏览器,访问受信任网站 A,输入用户名和密码请求登录网站 A;
2.在用户信息通过验证后,网站 A 产生 Cookie 信息并返回给浏览器,此时用户登录网站 A 成功,可以正常发送请求到网站 A;
3.用户未退出网站 A 之前,在同一浏览器中,打开一个 TAB 页访问网站 B;
4.网站 B 接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点 A;
5.浏览器在接收到这些攻击性代码后,根据网站 B 的请求,在用户不知情的情况下携带 Cookie 信息,向网站 A 发出请求。网站 A 并不知道该请求其实是由 B 发起的,所以会根据用户 C 的 Cookie 信息以 C 的权限处理该请求,导致来自网站 B 的恶意代码被执行。
两个条件:
C 用户访问站点 A 并产生了 cookie
C 用户没有退出 A 同时访问了 B
以下情况都是 CSRF 攻击的潜在风险:
你不能保证你登录了一个网站后,不再打开一个 tab 页面并访问另外的网站。
你不能保证你关闭浏览器了后,你本地的 Cookie 立刻过期,你上次的会话已经结束。(事实上,关闭浏览器不能结束一个会话,但大多数人都会错误的认为关闭浏览器就等于退出登录/结束会话了…)
上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。
防御 CSRF 攻击有多种手段:
- 不使用 cookie
- 为表单添加校验的 token 校验
- cookie 中使用 sameSite 字段
- 服务器检查 referer 字段
浏览器是如何渲染 UI 的?浏览器渲染过程(dom/cssom/render tree/layout)
- 浏览器获取 HTML 文件,然后对文件进行解析,形成 DOM Tree
- 与此同时,进行 CSS 解析,生成 Style Rules
- 接着将 DOM Tree 与 Style Rules 合成为 Render Tree
- 接着进入布局(Layout)阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标
- 随后调用 GPU 进行绘制(Paint),遍历 Render Tree 的节点,并将元素呈现出来
浏览器如何解析 css 选择器?
浏览器会『从右往左』解析 CSS 选择器。
我们知道 DOM Tree 与 Style Rules 合成为 Render Tree,实际上是需要将Style Rules附着到 DOM Tree 上,因此需要根据选择器提供的信息对 DOM Tree 进行遍历,才能将样式附着到对应的 DOM 元素上。
以下这段 css 为例
.mod-nav h3 span {
font-size: 16px;
}
我们对应的 DOM Tree 如下
若从左向右的匹配,过程是:
- 从 .mod-nav 开始,遍历子节点 header 和子节点 div
- 然后各自向子节点遍历。在右侧 div 的分支中
- 最后遍历到叶子节点 a ,发现不符合规则,需要回溯到 ul 节点,再遍历下一个 li-a,一颗 DOM 树的节点动不动上千,这种效率很低。
如果从右至左的匹配:
- 先找到所有的最右节点 span,对于每一个 span,向上寻找节点 h3
- 由 h3 再向上寻找 class=mod-nav 的节点
- 最后找到根元素 html 则结束这个分支的遍历。
后者匹配性能更好,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点);而从左向右的匹配规则的性能都浪费在了失败的查找上面。
DOM Tree 是如何构建的?
- 转码: 浏览器将接收到的二进制数据按照指定编码格式转化为 HTML 字符串
- 生成 Tokens: 之后开始 parser,浏览器会将 HTML 字符串解析成 Tokens
- 构建 Nodes: 对 Node 添加特定的属性,通过指针确定 Node 的父、子、兄弟关系和所属 treeScope
- 生成 DOM Tree: 通过 node 包含的指针确定的关系构建出 DOM Tree
浏览器重绘与重排的区别?
- 重排: 部分渲染树(或者整个渲染树)需要重新分析并且节点尺寸需要重新计算,表现为重新生成布局,重新排列元素
- 重绘: 由于节点的几何属性发生改变或者由于样式发生改变,例如改变元素背景色时,屏幕上的部分内容需要更新,表现为某些元素的外观被改变
单单改变元素的外观,肯定不会引起网页重新生成布局,但当浏览器完成重排之后,将会重新绘制受到此次重排影响的部分
重排和重绘代价是高昂的,它们会破坏用户体验,并且让 UI 展示非常迟缓,而相比之下重排的性能影响更大,在两者无法避免的情况下,一般我们宁可选择代价更小的重绘。
『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』。
如何触发重排和重绘?
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新 DOM 节点
- 通过 display: none 隐藏一个 DOM 节点-触发重排和重绘
- 通过 visibility: hidden 隐藏一个 DOM 节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的 DOM 节点添加动画
- 添加一个样式表,调整样式属性
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
如何避免重绘或者重排?
集中改变样式
我们往往通过改变 class 的方式来集中改变样式
// 判断是否是黑色系样式
const theme = isDark ? "dark" : "light";
// 根据判断来设置不同的class
ele.setAttribute("className", theme);
使用 DocumentFragment
我们可以通过 createDocumentFragment 创建一个游离于 DOM 树之外的节点,然后在此节点上批量操作,最后插入 DOM 树中,因此只触发一次重排
var fragment = document.createDocumentFragment();
for (let i = 0; i < 10; i++) {
let node = document.createElement("p");
node.innerHTML = i;
fragment.appendChild(node);
}
document.body.appendChild(fragment);
提升为合成层
将元素提升为合成层有以下优点:
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性:
#target {
will-change: transform;
}
如何实现跨域?
跨域是个比较古老的命题了,历史上跨域的实现手段有很多,我们现在主要介绍三种比较主流的跨域方案,其余的方案我们就不深入讨论了,因为使用场景很少,也没必要记这么多奇技淫巧。
最经典的跨域方案 jsonp
jsonp 本质上是一个 Hack,它利用<script>标签不受同源策略限制的特性进行跨域操作。
jsonp 优点:
- 实现简单
- 兼容性非常好
jsonp 的缺点:
- 只支持 get 请求(因为
<script>标签只能 get) - 有安全性问题,容易遭受 xss 攻击
- 需要服务端配合 jsonp 进行一定程度的改造
jsonp 的实现:
function JSONP({ url, params, callbackKey, callback }) {
// 在参数里制定 callback 的名字
params = params || {};
params[callbackKey] = "jsonpCallback";
// 预留 callback
window.jsonpCallback = callback;
// 拼接参数字符串
const paramKeys = Object.keys(params);
const paramString = paramKeys.map((key) => `${key}=${params[key]}`).join("&");
// 插入 DOM 元素
const script = document.createElement("script");
script.setAttribute("src", `${url}?${paramString}`);
document.body.appendChild(script);
}
JSONP({
url: "http://s.weibo.com/ajax/jsonp/suggestion",
params: {
key: "test",
},
callbackKey: "_cb",
callback(result) {
console.log(result.data);
},
});
最流行的跨域方案 cors
cors 是目前主流的跨域解决方案,跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的 Web 应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
如果你用 express,可以这样在后端设置
//CORS middleware
var allowCrossDomain = function(req, res, next) {
res.header('Access-Control-Allow-Origin', 'http://example.com');
res.header('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE');
res.header('Access-Control-Allow-Headers', 'Content-Type');
next();
}
//...
app.configure(function() {
app.use(express.bodyParser());
app.use(express.cookieParser());
app.use(express.session({ secret: 'cool beans' }));
app.use(express.methodOverride());
app.use(allowCrossDomain);
app.use(app.router);
app.use(express.static(__dirname + '/public'));
});
在生产环境中建议用成熟的开源中间件解决问题。
最方便的跨域方案 Nginx
nginx 是一款极其强大的 web 服务器,其优点就是轻量级、启动快、高并发。
现在的新项目中 nginx 几乎是首选,我们用 node 或者 java 开发的服务通常都需要经过 nginx 的反向代理。
反向代理的原理很简单,即所有客户端的请求都必须先经过 nginx 的处理,nginx 作为代理服务器再讲请求转发给 node 或者 java 服务,这样就规避了同源策略。
#进程, 可更具cpu数量调整
worker_processes 1;
events {
#连接数
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#连接超时时间,服务器会在这个时间过后关闭连接。
keepalive_timeout 10;
# gizp压缩
gzip on;
# 直接请求nginx也是会报跨域错误的这里设置允许跨域
# 如果代理地址已经允许跨域则不需要这些, 否则报错(虽然这样nginx跨域就没意义了)
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
# srever模块配置是http模块中的一个子模块,用来定义一个虚拟访问主机
server {
listen 80;
server_name localhost;
# 根路径指到index.html
location / {
root html;
index index.html index.htm;
}
# localhost/api 的请求会被转发到192.168.0.103:8080
location /api {
rewrite ^/b/(.*)$ /$1 break; # 去除本地接口/api前缀, 否则会出现404
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://192.168.0.103:8080; # 转发地址
}
# 重定向错误页面到/50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
其它跨域方案
- HTML5 XMLHttpRequest 有一个 API,postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
- WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了,因此可以跨域。
- window.name + iframe:window.name 属性值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值,我们可以利用这个特点进行跨域。
- location.hash + iframe:a.html 欲与 c.html 跨域相互通信,通过中间页 b.html 来实现。 三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js 访问来通信。
- document.domain + iframe: 该方式只能用于二级域名相同的情况下,比如 a.test.com 和 b.test.com 适用于该方式,我们只需要给页面添加 document.domain ='test.com' 表示二级域名都相同就可以实现跨域,两个页面都通过 js 强制设置 document.domain 为基础主域,就实现了同域。
chrome devtool 如何查看内存情况
哪些情况会导致内存泄漏,settimeout 为什么会造成内存泄露,如何防止?
1 意外使用全局变量
全局变量总是可以从全局访问,并且永远不会被垃圾收集。在非严格模式下,一些错误会导致变量从局部范围泄漏到全局范围:
给未声明的变量赋值,使用指向全局对象的 this
2 闭包
函数范围内的变量将在函数退出调用堆栈后被清除,如果函数外没有任何引用指向它们。尽管函数已经完成执行,并且它的执行上下文和变量环境早已消失,闭包仍将保持变量的引用和存在。
3 定时器
让 setTimeout 或 setInterval 在回调中引用某个对象是防止对象被垃圾收集的最常见方法。如果我们在代码中设置循环计时器(我们可以让 setTimeout 像 setInterval 一样工作,也就是说让它不停循环),只要回调函数是可调用的,从计时器的回调中对对象的引用将保持活动状态。
4 事件监听器 (event handlers)
事件监听器会防止在其范围内的所有变量被垃圾收集。添加后,事件监听器将保持有效,直到:
使用 removeEventListener()显式删除相关的 DOM 元素被移除。
5 缓存
如果我们继续将内存添加到缓存中,而不删除未使用的对象,并且没有一些限制大小的逻辑,那么缓存可以无限增长。
6 DOM 元素
如果一个 DOM 节点被 JavaScript 直接引用,即使在该节点从 DOM 树中移除了,也会阻止它被垃圾收集。
https://baijiahao.baidu.com/s?id=1668458579784282002&wfr=spider&for=pc
浏览器每一帧都会干些什么?

根据上图可知:浏览器一帧会经过下面这几个过程:
- 接受输入事件
- 执行事件回调
- 开始一帧
- 执行 RAF (RequestAnimationFrame)
- 页面布局,样式计算
- 绘制渲染
- 执行 RIC (RequestIdelCallback)
第七步的 RIC 事件不是每一帧结束都会执行,只有在一帧的 16.6ms 中做完了前面 6 件事儿且还有剩余时间,才会执行。如果一帧执行结束后还有时间执行 RIC 事件,那么下一帧需要在事件执行结束才能继续渲染,所以 RIC 执行不要超过 30ms,如果长时间不将控制权交还给浏览器,会影响下一帧的渲染,导致页面出现卡顿和事件响应不及时。
浏览器的主要组成部分是什么?
- 用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
- 呈现引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器。用于解析和执行 JavaScript 代码。
- 数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
图:浏览器的主要组件。
值得注意的是,和大多数浏览器不同,Chrome 浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
操作系统
线程和进程的区别
进程:
操作系统中最核心的概念就是进程,进程是对正在运行中的程序的一个抽象,是系统进行资源分配和调度的基本单位
操作系统的其他所有内容都是围绕着进程展开的,负责执行这些任务的是CPU

进程是一种抽象的概念,从来没有统一的标准定义看,一般由程序、数据集合和进程控制块三部分组成:
- 程序用于描述进程要完成的功能,是控制进程执行的指令集
- 数据集合是程序在执行时所需要的数据和工作区
- 程序控制块,包含进程的描述信息和控制信息,是进程存在的唯一标志
线程:
「线程」(thread)是操作系统能够进行「运算调度」的最小单位,其是进程中的一个执行任务(控制单元),负责当前进程中程序的执行
一个进程至少有一个线程,一个进程可以运行多个线程,这些线程共享同一块内存,线程之间可以共享对象、资源,如果有冲突或需要协同,还可以随时沟通以解决冲突或保持同步
举个例子,假设你经营着一家物业管理公司。最初,业务量很小,事事都需要你亲力亲为。给老张家修完暖气管道,立马再去老李家换电灯泡——这叫单线程,所有的工作都得顺序执行
后来业务拓展了,你雇佣了几个工人,这样,你的物业公司就可以同时为多户人家提供服务了——这叫多线程,你是主线程

但实际上,并不是线程越多,进程的工作效率越高,这是因为在一个进程内,不管你创建了多少线程,它们总是被限定在一颗CPU内,或者多核CPU的一个核内
这意味着,多线程在宏观上是并行的,在微观上则是分时切换串行的,多线程编程无法充分发挥多核计算资源的优势
这导致使用多线程做任务并行处理时,线程数量超过一定数值后,线程越多速度反倒越慢的原因
区别:
- 「本质区别」:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 「在开销方面」:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
- 「所处环境」:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过 CPU 调度,在每个时间片中只有一个线程执行)
- 「内存分配方面」:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了 CPU 外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
- 「包含关系」:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
举个例子:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A 车厢换到 B 车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
协程是什么(语言层面实现的并发),Go/nodeJs 怎样去实现协程(Go 使用 go 关键字、node 可以使用 Generator 实现、我理解 react16 的异步渲染也是协程的实现)
概念
协程,是一个比线程更轻量级的存在,协程完全由程序控制(也就是在用户态执行)
- 协程不被操作系统内核所管理
- 协程能极大的提升性能,不会像线程切换那样消耗资源
子程序,又称为“函数”。
- 在所有语言中都是层级调用的,A 调用 B,B 调用 C,C 执行完毕返回,B 执行完毕返回,最终 A 执行完毕
- 由此可见,子程序调用是通过栈实现的,一个线程就是执行一个子程序。
线程(执行一个函数)和协程的区别和联系
- 函数总是一个入口,一个返回,调用顺序是明确的(一个线程就是执行一个函数)
- 而协程的调用和函数不同,协程在函数内部是可以中断的,可以转而执行别的函数,在适当的时候再返回来接着执行。
def A(){
print 1
print 2
print 3
}
def B(){
print 'x'
print 'y'
print 'z'
}
比如上面代码如果是协程执行,在执行 A 的过程中,可以中断去执行 B,在执行 B 的时候亦然。结果可能是: 1 x y 2 3 z
同样上面的代码如果是线程执行,只能执行完 A 再执行 B,或者执行完 B 再执行 A,结果只可能是 2 种:1 2 3 x y z 或者 x y z 1 2 3
协程和多线程的优势?为什么有了多线程还要引入协程?
极高的执行效率:
- 因为函数(子程序)不是线程切换,而是由程序自身控制的,因此没有线程切换的开销;
- 和多线程比,线程数量越多,协程的性能优势越明显
不需要多线程的锁机制:
- 因为只有一个线程,不存在同时写变量的冲突,在协程中控制共享资源不加锁,只需要判断状态就行了,因此执行效率比多线程高很多。
性能优化
性能优化手段
宏观层面:
1、技术选型不一定非得框架,也许原生 js 和轻量化插件更合适。
2、从 Network 网络请求瀑布流分析,减少请求次数和每次请求时间
3、使用 webpack-bundle-analyzer 分析打包完的代码体积,去除无用或者过大的模块,减少 bundle 体积大小
4、使用 chrome Performance 分析性能,判断 FCP/LCP 是否是否过长,请求并发的顺序等
5、monitor:首先打开 F12,随后按快捷键 Ctrl + Shift + P,然后输入性能监视器/monitor。。上面会显示 cpu 使用率、js 堆大小等指标
6、profiler:首先打开 F12,随后按快捷键 Ctrl + Shift + P,然后输入性能剖析器/profiler。会有一份性能分析报告。
7、Recorder 顾名思义---记录员,他可以记录下用户和网页的交互(意念艾特了下公司的交互)。首先打开 F12,随后按快捷键 Ctrl + Shift + P,然后输入 Recorder。点击结束之后可以结束录制,我们可以回访我们的操作,还可以对我们的操作进行分析。分析中包括了屏幕截图,内存,网页指标,妥妥的精工利器。
8、获取各个阶段的响应时间,我们所要用到的接口是PerformanceNavigationTiming接口。
PerformanceNavigationTiming 提供了用于存储和检索有关浏览器文档事件的指标的方法和属性。 例如,此接口可用于确定加载或卸载文档需要多少时间。
function showNavigationDetails() {
const [entry] = performance.getEntriesByType("navigation");
console.table(entry.toJSON());
}
使用这个函数,我们就可以获取各个阶段的响应时间,
navigationStart 加载起始时间
redirectStart 重定向开始时间(如果发生了HTTP重定向,每次重定向都和当前文档同域的话,就返回开始重定向的fetchStart的值。其他情况,则返回0)
redirectEnd 重定向结束时间(如果发生了HTTP重定向,每次重定向都和当前文档同域的话,就返回最后一次重定向接受完数据的时间。其他情况则返回0)
fetchStart 浏览器发起资源请求时,如果有缓存,则返回读取缓存的开始时间
domainLookupStart 查询DNS的开始时间。如果请求没有发起DNS请求,如keep-alive,缓存等,则返回fetchStart
domainLookupEnd 查询DNS的结束时间。如果没有发起DNS请求,同上
connectStart 开始建立TCP请求的时间。如果请求是keep-alive,缓存等,则返回domainLookupEnd
(secureConnectionStart) 如果在进行TLS或SSL,则返回握手时间
connectEnd 完成TCP链接的时间。如果是keep-alive,缓存等,同connectStart
requestStart 发起请求的时间
responseStart 服务器开始响应的时间
domLoading 从图中看是开始渲染dom的时间,具体未知
domInteractive 未知
domContentLoadedEventStart 开始触发DomContentLoadedEvent事件的时间
domContentLoadedEventEnd DomContentLoadedEvent事件结束的时间
domComplete 从图中看是dom渲染完成时间,具体未知
loadEventStart 触发load的时间,如没有则返回0
loadEventEnd load事件执行完的时间,如没有则返回0
unloadEventStart unload事件触发的时间
unloadEventEnd unload事件执行完的时间
关于我们的 Web 性能,我们会用到的时间参数:
DNS 解析时间: domainLookupEnd - domainLookupStart TCP 建立连接时间: connectEnd - connectStart 白屏时间: responseStart - navigationStart dom 渲染完成时间: domContentLoadedEventEnd - navigationStart 页面 onload 时间: loadEventEnd - navigationStart
根据这些时间参数,我们就可以判断哪一阶段对性能有影响。
9、抓包,利用抓包工具进行对页面信息对抓取
10.性能分析工具:Pingdom、Load Impact、WebPage Test、Octa Gate Site Timer、Free Speed Test
优化手段
1、 tree shaking 清除我们项目中的一些无用代码
2、 split chunks 分包,把异步加载的页面和组件变成了一个个 chunk,也就是被打包成独立的 bundle
3、拆包,把公用的一些如框架 react 相关的代码拆出来放到 cdn 上。
4、gzip,服务端配置 gzip 压缩后可大大缩减资源大小。
5、图片压缩,比如阿里云 oss 可以按需求指定需要的尺寸
6、图片分割,如果页面中有一张效果图,比如真机渲染图,UI 手拿着刀不让你压缩。这时候不妨考虑一下分割图片。建议单张土图片的大小不要超过 100k,我们在分割完图片后,通过布局再拼接在一起。可以图片加载效率
7、sprite 雪碧图,现在不常用了,因为 http2 的多路复用已经可以减少很多资源请求的开销了
8、CDN,静态资源度建议放在 CDN 上,可以加快资源加载的速度
9、懒加载,懒加载也叫延迟加载,指的是在长网页中延迟加载图像,是一种非常好的优化网页性能的方式。
10、iconfont,使用字体图标来替换图标,减少请求次数。
11、逻辑后移,把紧急的主题逻辑往前放,先请求页面主功能接口
12、一些逻辑的算法复杂度优化
13、组件渲染,组建拆分不能太碎,而且要避免外层组件引起内层组件不必要的渲染
14、node middleware,使用 node middleware 合并请求。减少请求次数。这种方式也是非常实用的。
15、web worker,把一些耗时逻辑放到 webworker 里面去计算
16、缓存,缓存的主要手段有:浏览器缓存、CDN、反向代理、本地缓存、分布式缓存、数据库缓存。
17、GPU 渲染,可以用transform: translateZ(0) 来开启 GPU 加速 。
18、进行 Ajax 请求的时候,可以选择尽量使用 get 方法,这样可以使用客户端的缓存,提高请求速度。
19、资源预加载)是非常好的一种性能优化方法,可以大大降低页面加载时间,给用户更加流畅的用户体验。实现 Resource Hints 的方法有很多种,可分为基于 link 标签的 DNS-prefetch、subresource、preload、 prefetch、preconnect、prerender,和本地存储 localStorage。
20、SSR,渲染过程在服务器端完成,最终的渲染结果 HTML 页面通过 HTTP 协议发送给客户端,又被认为是‘同构'或‘通用',如果你的项目有大量的 detail 页面,相互特别频繁,建议选择服务端渲染。
21、UNPKG 是一个提供 npm 包进行 CDN 加速的站点,因此,可以将一些比较固定了依赖写入 html 模版中,从而提高网页的性能。首先,需要将这些依赖声明为 external,以便 webpack 打包时不从 node_modules 中加载这些资源
22、域名发散与收敛,域名收敛:就是将静态资源放在一个域名下,减少 DNS 解析的开销。域名发散:是将静态资源放在多个子域名下,就可以多线程下载,提高并行度,使客户端加载静态资源更加迅速。域名发散:是将静态资源放在多个子域名下,就可以多线程下载,提高并行度,使客户端加载静态资源更加迅速。
23、SPYD,SPDY 协议能够完成多路复用的加密全双工通道,显著提高非 wifi 环境下的网络体验。
其他:例如将样式表放在顶部,将脚本放在底部,减少重绘,按需加载,模块化等。方法很多,对症下药才是关键
前端怎样实现异常监控,上报数据需要哪些字段,数据怎样防止不会丢失
前端有哪些异常
| 异常 | 频率 |
|---|---|
| JavaScript 异常(语法错误、代码错误) | 经常 |
| 静态资源加载异常(img、js、css) | 偶尔 |
| Ajax 请求异常 | 偶尔 |
| promise 异常 | 较少 |
| iframe 异常 | 较少 |
如何捕获异常
try-catch
try-catch 只能捕获同步运行错误,对语法和异步错误却捕获不到。
1、同步运行错误
try {
kill;
} catch (err) {
console.error("try: ", err);
}
结果:try: ReferenceError: kill is not defined
2、无法捕获语法错误
try {
let name = '1;
} catch(err) {
console.error('try: ', err);
}
结果:Unterminated string constant
编译器能够阻止运行语法错误。
3、无法捕获异步错误
try {
setTimeout(() => {
undefined.map((v) => v);
}, 1000);
} catch (err) {
console.error("try: ", err);
}
结果:Uncaught TypeError: Cannot read property 'map' of undefined
window.onerror
当 JavaScript 运行时错误(包括语法错误)发生时,window 会触发一个 ErrorEvent 接口的 error 事件,并执行 window.onerror() 若该函数返回 true,则阻止执行默认事件处理函数。
1、同步运行错误
/**
* @param {String} message 错误信息
* @param {String} source 出错文件
* @param {Number} lineno 行号
* @param {Number} colno 列号
* @param {Object} error error对象
*/
window.onerror = (message, source, lineno, colno, error) => {
console.error("捕获异常:", message, source, lineno, colno, error);
return true;
};
kill;
结果:捕获异常: Uncaught ReferenceError: kill is not defined
2、无法捕获语法错误
/**
* @param {String} message 错误信息
* @param {String} source 出错文件
* @param {Number} lineno 行号
* @param {Number} colno 列号
* @param {Object} error error对象
*/
window.onerror = (message, source, lineno, colno, error) => {
console.error('捕获异常:', message, source, lineno, colno, error);
return true;
};
let name = '1;
结果:Unterminated string constant
编译器能够阻止运行语法错误。
3、异步错误
/**
* @param {String} message 错误信息
* @param {String} source 出错文件
* @param {Number} lineno 行号
* @param {Number} colno 列号
* @param {Object} error error对象
*/
window.onerror = (message, source, lineno, colno, error) => {
console.error("捕获异常:", message, source, lineno, colno, error);
return true;
};
setTimeout(() => {
undefined.map((v) => v);
}, 1000);
结果:`捕获异常: Uncaught TypeError: Cannot read property 'map' of undefined``
window.addEventListener('error')
当一项资源(如 <img> 或 <script> )加载失败,加载资源的元素会触发一个 Event 接口的 error 事件,并执行该元素上的 onerror() 处理函数。这些 error 事件不会向上冒泡到 window,不过(至少在 Firefox 中)能被单一的 window.addEventListener 捕获。
<script>
window.addEventListener('error', (err) => {
console.error('捕获异常:', err);
}, true);
</script>
<img src="./test.jpg" />
结果:捕获异常:Event {isTrusted: true, type: "error", target: img, currentTarget: Window, eventPhase: 1, …}
window.addEventListener('unhandledrejection')
当 Promise 被 reject 且没有 reject 处理器的时候,会触发 unhandledrejection 事件;这可能发生在 window 下,但也可能发生在 Worker 中。 这对于调试回退错误处理非常有用。
window.addEventListener("unhandledrejection", (err) => {
err.preventDefault();
console.error("捕获异常:", err);
});
Promise.reject("promise");
结果:捕获异常:PromiseRejectionEvent {isTrusted: true, promise: Promise, reason: "promise", type: "unhandledrejection", target: Window, …}
Vue
Vue.config.errorHandler = (err, vm, info) => {
console.error("捕获异常:", err, vm, info);
};
React
React16,提供了一个内置函数 componentDidCatch ,使用它可以非常简单的获取到 React 下的错误信息。
componentDidCatch(error, info) {
console.error('捕获异常:', error, info);
}
但是,推荐ErrorBoundary
用户界面中的 JavaScript 错误不应破坏整个应用程序。为了为 React 用户解决此问题,React16 引入了“错误边界”的新概念。
新建 ErrorBoundary.jsx 组件:
import React from "react";
import { Result, Button } from "antd";
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false, info: "" };
}
static getDerivedStateFromError(error) {
return { hasError: true };
}
componentDidCatch(error, info) {
this.setState({
info: error + "",
});
}
render() {
if (this.state.hasError) {
// 你可以渲染任何自定义的降级 UI
return (
<Result
status="500"
title="500"
subTitle={this.state.info}
extra={<Button type="primary">Report feedback</Button>}
/>
);
}
return this.props.children;
}
}
export default ErrorBoundary;
使用:
<ErrorBoundary>
<App />
</ErrorBoundary>
注意
错误边界不会捕获以下方面的错误:
- 事件处理程序
- 异步代码(例如
setTimeout或requestAnimationFrame回调) - 服务器端渲染
- 在错误边界本身(而不是其子级)中引发的错误
iframe
由于浏览器设置的“同源策略”,无法非常优雅的处理 iframe 异常,除了基本属性(例如其宽度和高度)之外,无法从 iframe 获得很多信息。
<script>
document.getElementById("myiframe").onload = () => {
const self = document.getElementById('myiframe');
try {
(self.contentWindow || self.contentDocument).location.href;
} catch(err) {
console.log('捕获异常:' + err);
}
};
</script>
<iframe id="myiframe" src="https://nibuzhidao.com" frameBorder="0" />
Sentry
业界非常优秀的一款监控异常的产品,作者也是用的这款,文档齐全。
需要上报哪些信息
- 错误 id
- 用户 id
- 用户名
- 用户 IP
- 设备
- 错误信息
- 浏览器版本
- 系统版本
- 应用版本
- 机型
- 时间戳
- 异常级别(error、warning、info)
网页性能指标有哪些(FP/FCP/LCP)
文档流加载周期
1、DOMContentLoaded 是指页面元素加载完毕,但是一些资源比如图片还无法看到,但是这个时候页面是可以正常交互的,比如滚动,输入字符等。 jQuery 中经常使用的 $(document).ready() 其实监听的就是 DOMContentLoaded 事件。
2、load 是指页面上所有的资源(图片,音频,视频等)加载完成。jQuery 中 $(document).load() 监听的是 load 事件。
3、readystatechange
document有readyState属性来描述document的loading状态, readyState的改变会触发readystatechange事件.
- loading: 文档文在加载
- interactive: 文档结束加载并被解析, 但是图片, 样式, frame 之类的子资源仍在加载
- complete: 文档和子资源已经结束加载, 该状态表明将要触发 loading 事件.
因此, 我们同样可以使用该事件来判断 dom 的加载状态.
4、beforeunload
在浏览器窗口, 文档或器资源将要卸载时, 会触发beforeunload事件, 这个文档依然是可见的, 并且这个事件在这一刻是可以取消的.
5、unload
当文档或者一个资资源将要被卸载时, 在beforeunload,pagehide时间之后触发, 文档会处于一个特定状态:
- 所有资源仍存在
- 对于终端用户所有资源均不可见
- 界面交互无效
- 错误不会停止卸载文档的过程.
Performance API
Performance 接口可以获取到当前页面与性能相关的信息。
- Performance.timing
在 chrome 中查看 performance.timing 对象:
PerformanceTiming {
connectEnd: 1568364862807
connectStart: 1568364862530
domComplete: 1568364863751
domContentLoadedEventEnd: 1568364863699
domContentLoadedEventStart: 1568364863698
domInteractive: 1568364863694
domLoading: 1568364863438
domainLookupEnd: 1568364862529
domainLookupStart: 1568364862529
fetchStart: 1568364862529
loadEventEnd: 1568364863785
loadEventStart: 1568364863751
navigationStart: 1568364862499
redirectEnd: 0
redirectStart: 0
requestStart: 1568364862807
responseEnd: 1568364863437
responseStart: 1568364863434
secureConnectionStart: 1568364862530
unloadEventEnd: 0
unloadEventStart: 0
}
对应浏览器的状态如下:
左边红线代表了网络传输层的过程, 右边红线代表了服务器传输回字节后浏览的各种事件状态, 这个阶段包含了浏览器对文档的解析, DOM 树构建, 布局, 绘制等.
- navigationStart: 表示从上一个文档卸载结束时的 unix 时间戳,如果没有上一个文档,这个值将和 fetchStart 相等。
- unloadEventStart: 表示前一个网页(与当前页面同域)unload 的时间戳,如果无前一个网页 unload 或者前一个网页与当前页面不同域,则值为 0。
- unloadEventEnd: 返回前一个页面 unload 时间绑定的回掉函数执行完毕的时间戳。
- redirectStart: 第一个 HTTP 重定向发生时的时间。有跳转且是同域名内的重定向才算,否则值为 0。
- redirectEnd: 最后一个 HTTP 重定向完成时的时间。有跳转且是同域名内部的重定向才算,否则值为 0。
- fetchStart: 浏览器准备好使用 HTTP 请求抓取文档的时间,这发生在检查本地缓存之前。
- domainLookupStart/domainLookupEnd: DNS 域名查询开始/结束的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等
- connectStart: HTTP(TCP)开始/重新 建立连接的时间,如果是持久连接,则与 fetchStart 值相等。
- connectEnd: HTTP(TCP) 完成建立连接的时间(完成握手),如果是持久连接,则与 fetchStart 值相等。
- secureConnectionStart: HTTPS 连接开始的时间,如果不是安全连接,则值为 0。
- requestStart: HTTP 请求读取真实文档开始的时间(完成建立连接),包括从本地读取缓存。
- responseStart: HTTP 开始接收响应的时间(获取到第一个字节),包括从本地读取缓存。
- responseEnd: HTTP 响应全部接收完成的时间(获取到最后一个字节),包括从本地读取缓存。
- domLoading: 开始解析渲染 DOM 树的时间,此时 Document.readyState 变为 loading,并将抛出 readystatechange 相关事件。
- domInteractive: 完成解析 DOM 树的时间,Document.readyState 变为 interactive,并将抛出 readystatechange 相关事件,注意只是 DOM 树解析完成,这时候并没有开始加载网页内的资源。
- domContentLoadedEventStart: DOM 解析完成后,网页内资源加载开始的时间,在 DOMContentLoaded 事件抛出前发生。
- domContentLoadedEventEnd: DOM 解析完成后,网页内资源加载完成的时间(如 JS 脚本加载执行完毕)。
- domComplete: DOM 树解析完成,且资源也准备就绪的时间,Document.readyState 变为 complete,并将抛出 readystatechange 相关事件。
- loadEventStart: load 事件发送给文档,也即 load 回调函数开始执行的时间。
- loadEventEnd: load 事件的回调函数执行完毕的时间。
计算加载时间:
// 计算加载时间
function getPerformanceTiming() {
var t = performance.timing;
var times = {};
// 页面加载完成的时间,用户等待页面可用的时间
times.loadPage = t.loadEventEnd - t.navigationStart;
// 解析 DOM 树结构的时间
times.domReady = t.domComplete - t.responseEnd;
// 重定向的时间
times.redirect = t.redirectEnd - t.redirectStart;
// DNS 查询时间
times.lookupDomain = t.domainLookupEnd - t.domainLookupStart;
// 读取页面第一个字节的时间
times.ttfb = t.responseStart - t.navigationStart;
// 资源请求加载完成的时间
times.request = t.responseEnd - t.requestStart;
// 执行 onload 回调函数的时间
times.loadEvent = t.loadEventEnd - t.loadEventStart;
// DNS 缓存时间
times.appcache = t.domainLookupStart - t.fetchStart;
// 卸载页面的时间
times.unloadEvent = t.unloadEventEnd - t.unloadEventStart;
// TCP 建立连接完成握手的时间
times.connect = t.connectEnd - t.connectStart;
return times;
}
- Performance.navigation
- redirectCount: 0 // 页面经过了多少次重定向
- type: 0
- 0 表示正常进入页面;
- 1 表示通过 window.location.reload() 刷新页面;
- 2 表示通过浏览器前进后退进入页面;
- 255 表示其它方式
- Performance.memory
- jsHeapSizeLimit: 内存大小限制
- totalJSHeapSize: 可使用的内存
- usedJSHeapSize: JS 对象占用的内存
Core Web Vitals
Core Web Vitals是应用于所有的 web 页面的Web Vitals的子集, 他们将在所有谷歌提供的性能测试工具中进行显示, 每个Core Web Vitals代表用户体验的一个不同方面, 在该领域是可衡量的, 并反映了以用户为中心的关键结果的真实体验.
网页核心的性能指标是随着时间的推移而不断的演变的. 在 2020 年, 主要关注用户体验的三个方面: 加载, 交互性和视觉稳定性.
Largest Contentful Paint (LCP): 衡量加载体验, 为了提供良好的用户体验, LCP 应该在页面首次开始后的 2.5s 内发生.First Input Delay(FID): 衡量可交互性, 页面的 FID 应该小于 100msCumulative Layout Shift(CLS): 衡量视觉稳定性的指标, 页面的 CLS 应该小于 0.1
LCP: 最大内容元素渲染
衡量加载体验的指标.
最早我们使用load, DOMContentLoaded事件, 但是他们与实际上用户屏幕上的内容是不一定对应的.
之后我们尝试使用以用户为中心的更新性能指标, 例如First Content Paint(FCP), 它只能捕获加载体验的最开始. 如果页面开始是一个loading动画, 这个指标就不准确了.
后来, 业界开始建议使用First Meaningful Paint(FMP)和Speed Index(SI)(都可以在Lighthouse中获取到), 但这些指标非常复杂, 难以解释, 误报率较高.
Largest Contentful Paint (LCP)用于衡量标准报告视口内可见的最大内容元素的渲染时间. 为了提供良好的用户体验, 网站应该努力在开始加载页面的前 2.5s 内进行最大内容渲染.
关注的元素
LCP 不会计算所有的元素, 它只关注:
- img 元素
- images 中的 svg 元素
- video 元素
- 通过
url()函数加载背景图片的元素 - 包含文本节点或者其他内联文本元素子级的块级元素
优化
影响 LCP 较差的最常见原因是:
- 服务器响应时间慢
- 阻断渲染的 js 和 css
- 资源加载时间慢
- 客户端渲染
所以我们从上面的角度去改善 LCP.
具体的措施有:
- 缓存 HTML 离线页面, 缓存页面资源, 减少浏览器对资源的请求
- 减小资源组算渲染, 对 CSS/JS 进行压缩, 合并, 级联, 内联等
- 对图片进行优化, 转换格式为 JPG, webp 等, 降低图片大小, 加载请求的速度
- 对 HTML 重写, 压缩空格, 去除注释
- 使用 preconnet 尽快建立链接, 使用 dns-prefect 尽快进行 DNS 查找
- 使用 CDN 加载请求速度
- 使用 Gzip 压缩页面
- 使用 sw 缓存资源和请求等
FID: 首次可交互事件
First Contentful Paint(FCP)可以衡量网站加载速度, 但是绘制的速度只是一般部分, 同样重要的是用户尝试与这些像素进行交互的时候网站的反应速度.
FID(First Input Delay), 即记录用户和页面进行首次交互操作所花费的时间, FID 指标影响用户对页面交互性和响应性的第一影响. 为了提供良好的用户体验, 站点应该使首次输入延迟小于 100 毫秒
FID 发生在 FCP 和 TTI 之间, 应为这个阶段虽然页面已经显示出部分的内容, 但尚不具备完全的可交互性. 这个阶段的用户交互往往有比较大的延迟.
浏览器接收到用户输入操作的时候, 主线程正在忙于执行一个耗时比较长的任务, 只有当这个任务执行完成以后, 浏览器才能响应用户的输入操作. 他必须等待的时间就是此页面上该用户的 FID 值.
优化
一方面, 我们可以向上面一样, 减少 js 的执行时间:
- 缩小压缩 js 文件
- 延迟加载首屏不需要的 js
- 减少未使用的 polyfill
另一方面, 我们可以分解耗时任务:
- 使用 web worker 独立运行耗时任务.
CLS: 视觉稳定性
页面内容的意外移动是由于异步加载的资源或将 DOM 元素动态添加到现有内容上方的页面而发生的.
Cumulative Layout Shift (CLS), 会测量页面的整个生命周期中发生的每个意外的样式移动的所有单独布局更改得分的总合. 布局的移动可能发生在可见元素从当前一帧到下一帧改变位置的任何时候. 为了提供良好的用户体验, 网站应该努力让 cls 分数小于 0.1.
布局偏移分值, 用于计算元素移动的指标. 是目标元素的两个指标(影响分数, 距离分数)的乘积:
布局偏移分值 = 影响分数 * 距离分数
影响分数, 指的是前一帧和当前帧所有不稳定元素的可见区域的并集(站视口总面积的部分).
比如这里, 一个元素在上一帧中占据视口的一半, 在下一帧中下移 25%. 红色的曲线就是两个帧中元素的可见区域的并集. 这种情况下, 影响分值为0.75
距离分数, 是任何不稳定元素在框架中移动的最大距离/视口的最大尺寸:
在这个例子中, 最大视口尺寸是高度, 不稳定元素移动了视口高度的 25%, 这使得距离分数为 0.25.
因此, 在这个例子中, 最终的 CLS 得分为: 0.75 * 0.25 = 0.1875.
优化
1. 不要使用无尺寸元素
图片和视频元素需要始终包含width和height尺寸属性, 现代浏览器会根据width和height设置图片的默认宽高比. 或者直接使用aspect-radio也可以提前指定宽高比:
img {
aspect-ratio: attr(width) / attr(height);
}
对于响应式图片, 可以使用srcset定义图像, 使浏览器可以在图像之间进行选择, 以及每个图像的大小:
<img
width="1000"
height="1000"
src="puppy-1000.jpg"
srcset="puppy-1000.jpg 1000w,
puppy-2000.jpg 2000w,
puppy-3000.jpg 3000w"
alt="ConardLi"
/>
2. 其他操作
永远不要在现有内容之上插入内容, 除非是响应用户交互. 这能确保预期的布局变化
宁可转换动画, 也不要转换触发布局变化的属性的动画.
提前给广告位预留空间
警惕字体变化, 使用font-display告诉浏览器默认使用系统字体进行渲染, 当自定义字体下载完成之后在进行替换
@font-face {
font-family: 'Pacifico';
font-style: normal;
font-weight: 400;
src: local('Pacifico Regular'), local('Pacifico-Regular'), url(https://fonts.gstatic.com/xxx.woff2) format('woff2');
font-display: swap;
}
此外可以使用<link rel='preload'>提前加载字体文件.
获取参数
方式 1: Google 提供了web-vitals来让我们便捷的调用这三个参数
import { getCLS, getFID, getLCP } from "web-vitals";
getCLS(console.log, true);
getFID(console.log); // Does not take a `reportAllChanges` param.
getLCP(console.log, true);
其回到函数中提供了三个指标:
- name: 指标的名称
- id: 本地分析的 id
- delta: 当前值和上次获取值的差值
可以结合google analytics来上报指标:
import { getCLS, getFID, getLCP } from "web-vitals";
function sendToGoogleAnalytics({ name, delta, id }) {
ga("send", "event", {
eventCategory: "Web Vitals",
eventAction: name,
eventValue: Math.round(name === "CLS" ? delta * 1000 : delta),
eventLabel: id,
nonInteraction: true,
});
}
getCLS(sendToGoogleAnalytics);
getFID(sendToGoogleAnalytics);
getLCP(sendToGoogleAnalytics);
方式 2: 使用 Chrome 插件
如果你不想在程序中计算, 还可以使用Chrome插件web-vitals-extension来获取这些指标.
其他常见性能指标
FP: 首次绘制事件
FP(First Paint, 首次绘制时间), 是时间线上的第一个"时间点", 它代表浏览器第一次向屏幕传输像素的时间, 也就是页面在屏幕上首次发生视觉变化的时间.
也就是我们所说的白屏时间(浏览器从响应用户输入网址到浏览器开始显示内容的时间).
白屏时间 = 地址栏输入网址后回车 - 浏览器出现第一个元素
影响白屏时间的因素: 网络, 服务端性能, 前端页面结构设计
通常认为浏览器开始渲染<body>标签或者解析完<head>的时间是白屏结束的时间点. 如何获取白屏事件, 可以参考下面的代码:
<head>
...
<script>
// 通常在head标签尾部时,打个标记,这个通常会视为白屏时间
performance.mark("first paint time");
</script>
</head>
<body>
...
<script>
// get the first paint time
const fp = Math.ceil(performance.getEntriesByName('first paint time')[0].startTime);
</script>
</body>
FCP: 首次内容绘制事件
FCP(First Contentful Paint, 首次内容绘制), 代表浏览器第一次向屏幕绘制"内容".
只有首次绘制文本, 图片, 非白色的 canvas 或者 SVG 的时候才被算作 FCP.
也就是我们所说的首屏时间(浏览器从响应用户输入网络地址到首屏内容渲染完成的时间):
首屏时间 = 地址输入网址后回车 - 浏览器第一屏渲染完成
关于首屏时间是否包含图片加载, 通常有不同的说法, 但那无关紧要.
计算首屏时间常用的方法有:
- 首屏模块标签标记法
由于浏览器解析 HTML 是按照顺序解析的, 当解析到某个元素的时候, 认为首屏完成了, 就在次元素后面加入 script 计算首屏完成的时间.
// 首屏屏结束时间
window.firstPaint = Date.now();
// 首屏时间
console.log(firstPaint - performance.timing.navigationStart);
- 统计首屏内加载最慢的图片/iframe
通常首屏内容中加载最慢的就是图片或者 iframe 资源,因此可以理解为当图片或者 iframe 都加载出来了,首屏肯定已经完成了。
由于浏览器对每个页面的 TCP 连接数有限制,使得并不是所有图片都能立刻开始下载和显示。我们只需要监听首屏内所有的图片的 onload 事件,获取图片 onload 时间最大值,并用这个最大值减去 navigationStart 即可获得近似的首屏时间。
<body>
<div class="app-container">
<img src="a.png" onload="heroImageLoaded()" />
<img src="b.png" onload="heroImageLoaded()" />
<img src="c.png" onload="heroImageLoaded()" />
</div>
<script>
// 根据首屏中的核心元素确定首屏时间
performance.clearMarks("hero img displayed");
performance.mark("hero img displayed");
function heroImageLoaded() {
performance.clearMarks("hero img displayed");
performance.mark("hero img displayed");
}
</script>
... ...
<script>
// get the first screen loaded time
const fmp = Math.ceil(
performance.getEntriesByName("hero img displayed")[0].startTime
);
</script>
</body>
注意: FP 与 FCP 这两个指标之间的主要区别在于: FP 是当浏览器开始绘制内容到屏幕上的时候, 只要在视觉上开始发生变化, 无论是什么内容触发的视觉变化, 这一刻的时间点, 就叫做 FP.
相比之下, FCP 指的是浏览器首次绘制来自 DOM 的内容, 例如文本, 图片, SVG, CANVAS 等元素. 这个时间点叫做 FCP
FP 和 FCP 的时间点可能相同, 也可能是先 FP, 后 FCP.
FMP: 首次主要内容绘制事件
FirstMeaningfulPaint, 首次主要内容渲染时间, 目前没有标准化的定义方式. 实践中, 可以将页面评分最高的可见内容出现在屏幕上的时间作为 FCP 时间
统计方式: 我们可以使用Mutation Observer观察页面加载的前 30s 中页面节点的变化, 将新增/移除的节点加入/移除intersection Observer, 这样可以得到页面元素的可见时间点及元素与可视区域的交叉信息. 根据元素的类型进行权重取值, 然后按可见度, 交叉区域面积, 权重值之间的乘积作为元素评分. 根据上面得到的信息, 以时间点为 X 周, 该时间点可见元素的评分总和为 Y 周, 取最高点对应的最小事件为页面主要内容出现在屏幕上的时间点.
目前没有统一的逻辑, 阿里有一个标准为最高可见增量元素, 采用深度优先遍历, 详情可以参考这里
LT: 长任务
当一个任务执行时间超过50ms时消耗到的任务. 50ms 阈值是从 RAIL 模型总结出来的结论,这个是 google 研究用户感知得出的结论,类似永华的感知/耐心的阈值,超过这个阈值的任务,用户会感知到页面的卡顿.
计算
// Jartto's Demo
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// TODO...
console.log(entry);
}
});
observer.observe({ entryTypes: ["longtask"] });
TTI: 页面可交互时间
TTI(Time To Internative): 从页面开始到它的主要子资源加载到能够快速地响应用户输入的时间. (没有耗时长任务)
计算
我们可以通过domContentLoadedEventEnd进行一个粗略的估算:
TTI: domContentLoadedEventEnd - navigationStart,
如果你需要更精细的计算即如果, 可以通过Google提供的tti-polyfill来进行数据获取:
import ttiPolyfill from "tti-polyfill";
ttiPolyfill.getFirstConsistentlyInteractive(opts).then((tti) => {
// Use `tti` value in some way.
});
TBT: 页面阻塞总时长
TBT (Total Blocking Time) 页面阻塞总时长: TBT 汇总所有加载过程中阻塞用户操作的时长,在 FCP 和 TTI 之间任何 long task 中阻塞部分都会被汇总.
如何减少重绘和回流
减少对 dom 的操作:当需要进行多个 dom 的增删改查时,避免直接对单个 dom 进行操作
使元素脱离文档流:由于页面中有时候会有一部分元素是有持续性的动画效果的,所以会一直触发回流和重绘,此时可以使这些元素脱离文档流,以此减少页面回流和重绘的次数;使用浮动( float )、绝对定位( position: absolute )可以使元素脱离文档流;
避免访问或减少访问某些属性:浏览器的渲染队列机制会通过队列将会触发回流或重绘的操作进行存储,等到一定的时间或一定的数量时再执行这些操作;
但是某些操作会导致浏览器强制刷新队列,如:offsetTop、offsetLeft、offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight、getComputedStyle、getBoundingClientRect;
浏览器为了获取最新的页面信息,需要立即执行队列里的所有操作,如果频繁使用上述方法,就会频繁的触发回流和重绘;
所以需要尽量减少或避免使用上述方法 / 属性
避免对 css 进行单个修改:
will-change( 兼容性不好 ):
MDN:CSS 属性 will-change 为 web 开发者提供了一种告知浏览器该元素会有哪些变化的方法,这样浏览器可以在元素属性真正发生变化之前提前做好对应的优化准备工作。 这种优化可以将一部分复杂的计算工作提前准备好,使页面的反应更为快速灵敏。
注意事项:
- 不要将 will-change 应用到太多元素上,这样会消耗太多浏览器的资源,导致页面响应缓慢;就像物业原来只管理一栋楼,如果忽然变成管理十栋楼,那么就会导致管理不过来的情况;
- 避免将 will-change 直接写在 css 中,尽量在元素发生变化前去设置它;
怎样首屏优化
1、打包分析,去除无用的第三方包
2、路由懒加载,非首屏必须的可以用的时候加载
3、生产环境可以关掉 sourcemap
4、首屏一些没必要的 prefetch 和 preload 可以关掉
5、图片压缩
6、使用 CDN
7、抽离公共代码
8、开启 gzip 压缩
9、其他:增加 loading 动画、骨架屏、小图标换成 svg 等等
js 超过 Number 最大值的数怎么处理?
使用 bigint 库或者类型
转换成字符串
设计模式
设计原则
单一职责原则(Single Responsibility Principle) 一个类应该只有一个发生变化的原因。简而言之就是每个类只需要负责自己的那部分,类的复杂度就会降低。
开闭原则(Open Closed Principle)
- 一个软件实体,如类、模块和函数应该对扩展开放,对修改关闭
里氏替换原则(Liskov Substitution Principle) 所有引用基类的地方必须能透明地使用其子类的对象,也就是说子类对象可以替换其父类对象,而程序执行效果不变。
迪米特法则(Law of Demeter) 迪米特法则(Law of Demeter)又叫作最少知识原则(The Least Knowledge Principle),一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解,只和朋友通信,不和陌生人说话。
接口隔离原则(Interface Segregation Principle)
- 多个特定的客户端接口要好于一个通用性的总接口
依赖倒置原则(Dependence Inversion Principle) 1、上层模块不应该依赖底层模块,它们都应该依赖于抽象。 2、抽象不应该依赖于细节,细节应该依赖于抽象
代理模式
代理模式 为其他对象提供一种代理以控制对这个对象的访问,类似于生活中的中介。实际上 ES6 中 Proxy 就是一个代理模式的体现,可以通过代理对象来实现对象访问的控制。
适配器模式
两个不兼容的接口之间的桥梁,将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。简单理解就是通过适配器让 2 个接口可以兼容。
策略模式
定义 : 要实现某一个功能,有多种方案可以选择。我们定义策略,把它们一个个封装起来,并且使它们可以相互转换。
当你负责的模块,基本满足以下情况时
- 各判断条件下的策略相互独立且可复用
- 策略内部逻辑相对复杂
- 策略需要灵活组合
观察者模式
定义一个对象与其他对象之间的一种依赖关系,当对象发生某种变化的时候,依赖它的其它对象都会得到更新。
观察者模式优点可以看出可以 1.支持一对多关系。2.可以延迟执行事件。3.在 2 个对象之间解耦。在原生 js、nodejs、vue、及 react 中观察者模式都被广泛使用 。
发布订阅模式
发布-订阅是一种消息范式,消息的发布者,不会将消息直接发送给特定的订阅者,而是通过消息通道广播出去,然后呢,订阅者通过订阅获取到想要的消息。
当你负责的模块,基本满足以下情况时
- 各模块相互独立
- 存在一对多的依赖关系
- 依赖模块不稳定、依赖关系不稳定
- 各模块由不同的人员、团队开发
装饰器模式
使用一种更为灵活的方式来动态给一个对象/函数等添加额外信息。也就是在原本对象或者功能上来进行扩展功能或者属性。符合设计原则中的开闭原则,通过装饰器扩展功能可以尽可能保证内部的纯洁性,保证内部少的修改或者是不修改。
工厂模式
封装具体实例创建逻辑和过程,外部只需要根据不同条件返回不同的实例。
工厂模式在 js 这块的使用很多情况下可以通过构造函数及类来进行取代。它的优点是实现代码复用性,封装良好,抽象逻辑。缺点也很明显增加了代码的复杂程度。
单例模式
单例模式 (Singleton Pattern)又称为单体模式,保证一个类只有一个实例,并提供一个访问它的全局访问点。也就是说,第二次使用同一个类创建新对象的时候,应该得到与第一次创建的对象完全相同的对象。
桌面端
electron 原理和架构
Electron 是使用 JavaScript,HTML 和 CSS 构建跨平台的桌面应用程序的框架,可构建出兼容 Mac、Windows 和 Linux 三个平台的应用程序。
Electron 的跨端原理并不难理解:它通过集成浏览器内核,使用前端的技术来实现不同平台下的渲染,并结合了 Chromium 、Node.js 和用于调用系统本地功能的 API 三大板块。

Chromium为Electron提供强大的UI渲染能力,由于Chromium本身跨平台,因此无需考虑代码的兼容性。最重要的是,可以使用前端三板斧进行Electron开发。Chromium并不具备原生GUI的操作能力,因此Electron内部集成Node.js,编写UI的同时也能够调用操作系统的底层API,例如 path、fs、crypto 等模块。Native API为Electron提供原生系统的GUI支持,借此Electron可以调用原生应用程序接口。
总结起来,Chromium 负责页面 UI 渲染,Node.js 负责业务逻辑,Native API 则提供原生能力和跨平台。
Electron 架构参考了 Chromium 的多进程架构模式,即将主进程和渲染进程隔离,并且在 Chromium 多进程架构基础上做一定扩展。
Chromium 运行时由一个 Browser Process,以及一个或者多个 Renderer Process 构成。Renderer Process 负责渲染页面 Web ,Browser Process 负责管理各个 Renderer Process 以及其他功能(菜单栏、收藏夹等)
Electron 架构中仍然使用了 Chromium 的 Renderer Process 渲染界面,Renderer Process 可以有多个,互相独立不干扰。由于 Electron 为其集成了 Node 运行时,Renderer Process 可以调用 Node API。主要负责: 利用 HTML 和 CSS 渲染页面;利用 JavaScript 实现页面交互效果。

相较于 Chromium 架构,Electron 对 Browser 线程做了很多改动,将其更改名 Main Process,每个应用程序只能有一个主线程,主线程位于 Node.js 下运行,因此其可以调用系统底层功能。其主要负责:渲染进程的创建;系统底层功能及原生资源的调用;应用生命周期的控制(包裹启动、推出以及一些事件监听)

可以发现,主线程和渲染线程都集成了 Native API 和 Node.js,渲染线程还集成 Chromium 内核,成功实现跨端开发。
electron-store 原理
Electron 没有内置的方法来保存用户偏好和其他数据。electron-store 会为您处理,因此您可以专注于构建您的应用程序。数据保存在 app.getPath('userData') 中名为 config.json 的 JSON 文件中。
"use strict";
const path = require("path");
const { app, ipcMain, ipcRenderer, shell } = require("electron");
const Conf = require("conf");
let isInitialized = false;
// Set up the `ipcMain` handler for communication between renderer and main process.
const initDataListener = () => {
if (!ipcMain || !app) {
throw new Error(
"Electron Store: You need to call `.initRenderer()` from the main process."
);
}
const appData = {
defaultCwd: app.getPath("userData"),
appVersion: app.getVersion(),
};
if (isInitialized) {
return appData;
}
ipcMain.on("electron-store-get-data", (event) => {
event.returnValue = appData;
});
isInitialized = true;
return appData;
};
class ElectronStore extends Conf {
constructor(options) {
let defaultCwd;
let appVersion;
// If we are in the renderer process, we communicate with the main process
// to get the required data for the module otherwise, we pull from the main process.
if (ipcRenderer) {
const appData = ipcRenderer.sendSync("electron-store-get-data");
if (!appData) {
throw new Error(
"Electron Store: You need to call `.initRenderer()` from the main process."
);
}
({ defaultCwd, appVersion } = appData);
} else if (ipcMain && app) {
({ defaultCwd, appVersion } = initDataListener());
}
options = {
name: "config",
...options,
};
if (!options.projectVersion) {
options.projectVersion = appVersion;
}
if (options.cwd) {
options.cwd = path.isAbsolute(options.cwd)
? options.cwd
: path.join(defaultCwd, options.cwd);
} else {
options.cwd = defaultCwd;
}
options.configName = options.name;
delete options.name;
super(options);
}
static initRenderer() {
initDataListener();
}
openInEditor() {
shell.openPath(this.path);
}
}
module.exports = ElectronStore;
其中使用到了conf的包,conf 也就是实现了 set、get 等方法。
electron-builder、electron-forge、electron-packager 构建工具区别
electron-builder:一个完整的解决方案,用于为 macOS、Windows 和 Linux 打包和构建准备好分发的 Electron 应用程序,并提供开箱即用的“自动更新”支持。electron-builder 有比 electron-packager 有更丰富的的功能,支持更多的平台,同时也支持了自动更新。除了这几点之外,由 electron-builder 打出的包更为轻量,并且可以打包出不暴露源码的 setup 安装程序。
Electron-Forge,用于构建现代 Electron 应用程序的完整工具。它由 Samuel Attard 于 2016 年 10 月撰写。
Electron-Packager,通过 JS 或 CLI 使用操作系统特定的包(.app、.exe 等)自定义和打包您的 Electron 应用程序。它由 Mark Lee 于 2015 年 4 月撰写。
electron-builder 其和 electron-forge 的区别在于自由度,两者在能力上基本没什么差异了,从官方组织中的排序看,有意优先推荐 electron-forge 。
electron-updater 怎样实现自动更新
1、把每次打完包的latest.yml(或latest-mac.yml适用于 macOS,或latest-linux.yml适用于 Linux)上传到一个地址
2、updater 读取这个地址获取最新版本并开始下载
3、监听下载过程中的声明周期,下载完成后提示更新
import { autoUpdater } from "electron-updater";
import { ipcMain } from "electron";
const uploadUrl = "";
export function updateHandle(mainWindow) {
let message = {
error: "isError",
checking: "isChecking",
updateAva: "canUpdate",
updateNotAva: "isLatest",
};
const os = require("os");
autoUpdater.autoDownload = false;
//设置更新包的地址
autoUpdater.setFeedURL(uploadUrl);
//监听升级失败事件
autoUpdater.on("error", function (error) {
console.log(error, "error");
sendUpdateMessage(message.error, mainWindow, error);
});
//监听开始检测更新事件
autoUpdater.on("checking-for-update", function () {
sendUpdateMessage(message.checking, mainWindow);
});
//监听发现可用更新事件
autoUpdater.on("update-available", function (info) {
sendUpdateMessage(message.updateAva, mainWindow, info);
});
//监听没有可用更新事件
autoUpdater.on("update-not-available", function (info) {
sendUpdateMessage(message.updateNotAva, mainWindow, info);
});
// 更新下载进度事件
autoUpdater.on("download-progress", function (progressObj) {
mainWindow.webContents.send("downloadProgress", progressObj);
});
//监听下载完成事件
autoUpdater.on(
"update-downloaded",
function (
event,
releaseNotes,
releaseName,
releaseDate,
updateUrl,
quitAndUpdate
) {
ipcMain.on("isUpdateNow", (e, arg) => {
console.log(arguments);
console.log("开始更新");
//some code here to handle event
autoUpdater.quitAndInstall();
});
mainWindow.webContents.send("isUpdateNow");
}
);
//接收渲染进程消息,开始检查更新
ipcMain.on("checkForUpdate", () => {
//执行自动更新检查
autoUpdater.checkForUpdates();
});
ipcMain.on("downloadUpdate", () => {
// 下载
autoUpdater.downloadUpdate();
});
}
// 通过main进程发送事件给renderer进程,提示更新信息
export function sendUpdateMessage(text, mainWindow, extra) {
mainWindow.webContents.send("message", text, extra);
}
electron-updater 和 built-in autoUpdater 的区别
- 不需要专用的发布服务器。
- 代码签名验证不仅适用于 macOS,还适用于 Windows。
- 所有必需的元数据文件和工件都是自动生成和发布的。
- 所有平台都支持下载进度和分阶段部署。
- 开箱即用地支持不同的提供商(GitHub Releases、Amazon S3、DigitalOcean Spaces、Keygen和通用 HTTP(s) 服务器)。
- 你只需要 2 行代码就可以让它工作。
electron 主进程和渲染进程怎么通信
进程间通信 (IPC) 是在 Electron 中构建功能丰富的桌面应用程序的关键部分之一。 由于主进程和渲染器进程在 Electron 的进程模型具有不同的职责,因此 IPC 是执行许多常见任务的唯一方法,例如从 UI 调用原生 API 或从原生菜单触发 Web 内容的更改。
在 Electron 中,进程使用 ipcMain 和 ipcRenderer 模块,通过开发人员定义的“通道”传递消息来进行通信。 这些通道是 任意 (您可以随意命名它们)和 双向 (您可以在两个模块中使用相同的通道名称)的。
渲染器进程到主进程(单向)
要将单向 IPC 消息从渲染器进程发送到主进程,您可以使用 ipcRenderer.send API 发送消息,然后使用 ipcMain.on API 接收。
//main.js
//使用 ipcMain.on 监听事件
const { app, BrowserWindow, ipcMain } = require("electron");
const path = require("path");
function createWindow() {
const mainWindow = new BrowserWindow({
webPreferences: {
preload: path.join(__dirname, "preload.js"),
},
});
ipcMain.on("set-title", (event, title) => {
const webContents = event.sender;
const win = BrowserWindow.fromWebContents(webContents);
win.setTitle(title);
});
mainWindow.loadFile("index.html");
}
app.whenReady().then(() => {
createWindow();
app.on("activate", function () {
if (BrowserWindow.getAllWindows().length === 0) createWindow();
});
});
app.on("window-all-closed", function () {
if (process.platform !== "darwin") app.quit();
});
//preload.js
//通过预加载脚本暴露 ipcRenderer.send
const { contextBridge, ipcRenderer } = require("electron");
contextBridge.exposeInMainWorld("electronAPI", {
setTitle: (title) => ipcRenderer.send("set-title", title),
});
//renderer.js
const setButton = document.getElementById("btn");
const titleInput = document.getElementById("title");
setButton.addEventListener("click", () => {
const title = titleInput.value;
window.electronAPI.setTitle(title);
});
渲染器进程到主进程(双向)
双向 IPC 的一个常见应用是从渲染器进程代码调用主进程模块并等待结果。 这可以通过将 ipcRenderer.invoke 与 ipcMain.handle 搭配使用来完成。
//main.js
//使用 ipcMain.handle 监听事件
const { app, BrowserWindow, ipcMain, dialog } = require("electron");
const path = require("path");
async function handleFileOpen() {
const { canceled, filePaths } = await dialog.showOpenDialog();
if (canceled) {
return;
} else {
return filePaths[0];
}
}
function createWindow() {
const mainWindow = new BrowserWindow({
webPreferences: {
preload: path.join(__dirname, "preload.js"),
},
});
mainWindow.loadFile("index.html");
}
app.whenReady().then(() => {
ipcMain.handle("dialog:openFile", handleFileOpen);
createWindow();
app.on("activate", function () {
if (BrowserWindow.getAllWindows().length === 0) createWindow();
});
});
app.on("window-all-closed", function () {
if (process.platform !== "darwin") app.quit();
});
// preload.js
//通过预加载脚本暴露 ipcRenderer.invoke
const { contextBridge, ipcRenderer } = require("electron");
contextBridge.exposeInMainWorld("electronAPI", {
openFile: () => ipcRenderer.invoke("dialog:openFile"),
});
//renderer.js
const btn = document.getElementById("btn");
const filePathElement = document.getElementById("filePath");
btn.addEventListener("click", async () => {
const filePath = await window.electronAPI.openFile();
filePathElement.innerText = filePath;
});
ipcRenderer.invoke API 是在 Electron 7 中添加的,作为处理渲染器进程中双向 IPC 的一种开发人员友好的方式。 但这种 IPC 模式存在几种替代方法。
使用 ipcRenderer.send
//main.js
ipcMain.on("asynchronous-message", (event, arg) => {
console.log(arg); // 在 Node 控制台中打印“ping”
// 作用如同 `send`,但返回一个消息
// 到发送原始消息的渲染器
event.reply("asynchronous-reply", "pong");
});
//preload.js
// 您也可以使用 `contextBridge` API
// 将这段代码暴露给渲染器进程
const { ipcRenderer } = require("electron");
ipcRenderer.on("asynchronous-reply", (_event, arg) => {
console.log(arg); // 在 DevTools 控制台中打印“pong”
});
ipcRenderer.send("asynchronous-message", "ping");
使用 ipcRenderer.sendSync
//main.js
const { ipcMain } = require("electron");
ipcMain.on("synchronous-message", (event, arg) => {
console.log(arg); // 在 Node 控制台中打印“ping”
event.returnValue = "pong";
});
//preload.js
// 您也可以使用 `contextBridge` API
// 将这段代码暴露给渲染器进程
const { ipcRenderer } = require("electron");
const result = ipcRenderer.sendSync("synchronous-message", "ping");
console.log(result); // 在 DevTools 控制台中打印“pong”
主进程到渲染器进程
将消息从主进程发送到渲染器进程时,需要指定是哪一个渲染器接收消息。 消息需要通过其 WebContents 实例发送到渲染器进程。 此 WebContents 实例包含一个 send 方法,其使用方式与 ipcRenderer.send 相同。
//main.js
const { app, BrowserWindow, Menu, ipcMain } = require("electron");
const path = require("path");
function createWindow() {
const mainWindow = new BrowserWindow({
webPreferences: {
preload: path.join(__dirname, "preload.js"),
},
});
const menu = Menu.buildFromTemplate([
{
label: app.name,
submenu: [
{
click: () => mainWindow.webContents.send("update-counter", 1),
label: "Increment",
},
{
click: () => mainWindow.webContents.send("update-counter", -1),
label: "Decrement",
},
],
},
]);
Menu.setApplicationMenu(menu);
mainWindow.loadFile("index.html");
// Open the DevTools.
mainWindow.webContents.openDevTools();
}
app.whenReady().then(() => {
ipcMain.on("counter-value", (_event, value) => {
console.log(value); // will print value to Node console
});
createWindow();
app.on("activate", function () {
if (BrowserWindow.getAllWindows().length === 0) createWindow();
});
});
app.on("window-all-closed", function () {
if (process.platform !== "darwin") app.quit();
});
//preload.js
const { contextBridge, ipcRenderer } = require("electron");
contextBridge.exposeInMainWorld("electronAPI", {
handleCounter: (callback) => ipcRenderer.on("update-counter", callback),
});
//renderer.js
const counter = document.getElementById("counter");
window.electronAPI.handleCounter((event, value) => {
const oldValue = Number(counter.innerText);
const newValue = oldValue + value;
counter.innerText = newValue;
event.sender.send("counter-value", newValue);
});
渲染器进程到渲染器进程
没有直接的方法可以使用 ipcMain 和 ipcRenderer 模块在 Electron 中的渲染器进程之间发送消息。 为此,您有两种选择:
- 将主进程作为渲染器之间的消息代理。 这需要将消息从一个渲染器发送到主进程,然后主进程将消息转发到另一个渲染器。
- 从主进程将一个 MessagePort 传递到两个渲染器。 这将允许在初始设置后渲染器之间直接进行通信。
electron 中实现多窗口之间的通信方式
1、通过主进程当跳板
2、通过 MessageChannel
//renderer.js
// MessagePorts are created in pairs. 连接的一对消息端口
// 被称为通道。
const channel = new MessageChannel();
// port1 和 port2 之间唯一的不同是你如何使用它们。 消息
// 发送到port1 将被port2 接收,反之亦然。
const port1 = channel.port1;
const port2 = channel.port2;
// 允许在另一端还没有注册监听器的情况下就通过通道向其发送消息
// 消息将排队等待,直到一个监听器注册为止。
port2.postMessage({ answer: 42 });
// 这次我们通过 ipc 向主进程发送 port1 对象。 类似的,
// 我们也可以发送 MessagePorts 到其他 frames, 或发送到 Web Workers, 等.
ipcRenderer.postMessage("port", null, [port1]);
//main.js
// In the main process, we receive the port.
ipcMain.on("port", (event) => {
// 当我们在主进程中接收到 MessagePort 对象, 它就成为了
// MessagePortMain.
const port = event.ports[0];
// MessagePortMain 使用了 Node.js 风格的事件 API, 而不是
// web 风格的事件 API. 因此使用 .on('message', ...) 而不是 .onmessage = ...
port.on("message", (event) => {
// 收到的数据是: { answer: 42 }
const data = event.data;
});
// MessagePortMain 阻塞消息直到 .start() 方法被调用
port.start();
});
新技术
什么是 graphql,为什么需要?
GraphQL 是一款由 Facebook 主导开发的数据查询和操作语言,相对于 Restful 风格查询语言有更强的灵活性。它通过描述需要的数据结构和字段,可以快捷准确的获得数据,同时也减少了请求次数,可以将多个接口请求的数据合并为一个接口。
query和mutation 统称为schema。其实还有一个subscriptions在 2017 年被加入到规范(spec)中,让我们可以更轻松的实现推送功能。
优点
- 所见即所得:所写请求体即为最终数据结构
- 减少网络请求:复杂数据的获取也可以一次请求完成
- Schema 即文档:定义的 Schema 也规定了请求的规则
- 类型检查:严格的类型检查能够消除一定的认为失误
缺点
- 增加了服务端实现的复杂度:一些业务可能无法迁移使用 GraphQL,虽然可以使用中间件的方式将原业务的请求进行代理,这无疑也将增加复杂度和资源的消耗
前端微服务(qiankun)原理
single-spa 原理和用法
qiankun 怎样实现样式隔离
默认沙箱会隔离子应用之间,但是无法对主应用和子应用,或者多实例场景的子应用样式隔离。可以采用下面两种方法:
开启 strictStyleIsolation 严格样式隔离为每个子应用添加 shadowDOM,从而确保微应用的样式不会对全局造成影响。
还有 strictStyleIsolation 如果开启的话,qiankun 会改写子应用所添加的样式为所有样式规则增加一个特殊的选择器规则来限定其影响范围。
qiankun 怎样实现脚本隔离
脚本隔离的方式主要有两种,一种是快照拷贝的方式,一个是基于 proxy 的方式。乾坤会根据当前环境是否支持 proxy 来决定用那种方式。
snapshot 沙箱是遍历当前 windows 对象,保存到一个空对象上作为假的 window。
而 legacy 沙箱是把当前的 windows 做一层代理,生成一个 fakewindow。
proxy 沙箱是为每一个子应用的生成一个实例 proxy,优先作用到自己的 fakewindows 上,没有的属性才会透传到 windows。
snapshot 沙箱
在创建微应用的时候会实例化一个沙盒对象,它有两个方法,active 是在激活微应用的时候执行,而 inactive 是在离开微应用的时候执行。
整体的思路是在激活微应用时将当前的 window 对象拷贝存起来,然后从 modifyPropsMap 中恢复这个微应用上次修改的属性到 window 中。在离开微应用时会与原有的 window 对象做对比,将有修改的属性保存起来,以便再次进入这个微应用时进行数据恢复,然后把有修改的属性值恢复到以前的状态。
legacy 沙箱和 proxy 沙箱
微应用中的 script 内容都会加 with(global)来执行,这里 global 是全局对象,如果是 proxy 的隔离方式那么他就是下面新创建的 proxy 对象。我们知道 with 可以改变里面代码的作用域,也就是我们的微应用全局对象会变成下面的这个 proxy。当设置属性的时候会设置到 proxy 对象里,在读取属性时先从 proxy 里找,没找到再从原始的 window 中找。也就是你在微应用里修改全局对象的属性时不会在 window 中修改,而是在 proxy 对象中修改。因为不会破坏 window 对象,这样就会隔离各个应用之间的数据影响。
legacy 沙箱和 proxy 沙箱的主要区别是,legacy 沙箱只会有一个实例,而 proxy 沙箱会为每个子应用创建一个沙箱实例。
qiankun 和 EMP 以及其他微服务框架的区别
- 现有微前端解决方案:
- iframe
- Web Components
- ESM
- qiankun
- EMP
- 各解决方案的利弊:
iframe可以直接加载其他应用,但无法做到单页导致许多功能无法正常在主应用中展示。web Components及ESM是浏览器提供给开发者的能力,能在单页中实现微前端,不过后者需要做好代码隔离,并且他们都是浏览器的新特性,都存在兼容性问题,微前端方面的探索也不成熟,只能作为面向未来的微前端手段。qiankun基本上可以称为单页版的 iframe,具有沙箱隔离及资源预加载的特点,几乎无可挑剔。EMP作为最年轻微前端解决方案,也是吸收了许多 web 优秀特性才诞生的,它在实现微前端的基础上,扩充了跨应用状态共享、跨框架组件调用、远程拉取 ts 声明文件、动态更新微应用等能力。同时,细心的小伙伴应该已经发现,EMP能做到第三方依赖的共享,使代码尽可能地重复利用,减少加载的内容。
以下表格为各解决方案的总结:

qiankun 怎样实现沙箱
沙盒主要作用就是隔离微应用之间的脚本和样式影响,需要处理 style、link、script 类型的标签。对于处理的时机第一个是在首次加载的时候,第二个是在微应用运行中。在运行中的处理方案就是乾坤重写了下面这些原生的方法,这样就可以监听到新添加的节点,然后对 style、link、script 标签进行处理。
qiankun 怎样切换路由
监听 路由变化事件
window.addEventListener("hashchange", urlReroute);
window.addEventListener("popstate", urlReroute);
什么是 ShadowDOM
Web components 的一个重要属性是封装——可以将标记结构、样式和行为隐藏起来,并与页面上的其他代码相隔离,保证不同的部分不会混在一起,可使代码更加干净、整洁。其中,Shadow DOM 接口是关键所在,它可以将一个隐藏的、独立的 DOM 附加到一个元素上。本篇文章将会介绍 Shadow DOM 的基础使用。
Shadow DOM 允许将隐藏的 DOM 树附加到常规的 DOM 树中——它以 shadow root 节点为起始根节点,在这个根节点的下方,可以是任意元素,和普通的 DOM 元素一样。

你可以使用同样的方式来操作 Shadow DOM,就和操作常规 DOM 一样——例如添加子节点、设置属性,以及为节点添加自己的样式(例如通过 element.style 属性),或者为整个 Shadow DOM 添加样式(例如在 `` 元素内添加样式)。不同的是,Shadow DOM 内部的元素始终不会影响到它外部的元素(除了 :focus-within),这为封装提供了便利。
可以使用 Element.attachShadow() 方法来将一个 shadow root 附加到任何一个元素上。它接受一个配置对象作为参数,该对象有一个 mode 属性,值可以是 open 或者 closed:
let shadow = elementRef.attachShadow({mode: 'open'});
let shadow = elementRef.attachShadow({mode: 'closed'});
open 表示可以通过页面内的 JavaScript 方法来获取 Shadow DOM,例如使用 Element.shadowRoot 属性:
let myShadowDom = myCustomElem.shadowRoot;
如果你将一个 Shadow root 附加到一个 Custom element 上,并且将 mode 设置为 closed,那么就不可以从外部获取 Shadow DOM 了——myCustomElem.shadowRoot 将会返回 null。浏览器中的某些内置元素就是如此,例如<video>,包含了不可访问的 Shadow DOM。
Node*
libuv 原理
事件循环执行过程
setimmdite 和 nextTick 区别
cluster
buffer
异步 IO 模型
日志和负载均衡怎么做
nestjs 是什么,有什么用,和 express 和 koa 有什么区别
pm2 守护进程原理
node 开启子进程的方法,子进程之间如何通信?
nodejs 如何调试
koa 洋葱模型
node 怎样实现中间件?
koa bodyparse 是什么?
express 中间件原理
node.js 里流的理解,是什么,解决什么问题。
node.js 集群中用户的会话信息是怎么存储的。
锁机制的作用,node 和 Go 如何处理死锁
Go/node 实现并发怎么做
node 和 Go 的优缺点怎样理解
V8 内核
什么是 Node.js 中的 process?它有哪些方法和应用场景?
在 Node.js 中,process 是一个全局变量,它提供了与当前 Node.js 进程相关的信息和控制。process 对象是 EventEmitter 的一个实例,因此它可以使用 EventEmitter 的 API,例如注册事件监听器和触发事件。
process 对象的一些常用方法和属性:
- process.argv:返回一个数组,其中包含命令行参数。第一个元素是 Node.js 可执行文件的路径,第二个元素是正在执行的 JavaScript 文件的路径,后面的元素是命令行参数。
- process.env:返回一个包含当前 Shell 环境变量的对象。
- process.exit([code]):终止 Node.js 进程。如果指定了 code,那么进程将以 code 退出。
- process.cwd():返回当前工作目录的路径。
- process.chdir(directory):将 Node.js 进程的工作目录更改为 directory。
- process.pid:返回 Node.js 进程的进程 ID。
- process.nextTick(callback[, arg1][, arg2][, ...]):将 callback 添加到下一个 tick 队列。callback 会在当前操作完成后、事件循环继续之前调用。
- process.on(event, listener):注册事件监听器。常用的事件包括 "exit"、"uncaughtException"、"SIGINT" 等。
process 对象的应用场景:
- 监听进程退出事件,执行资源清理操作。
- 通过 process.argv 读取命令行参数。
- 通过 process.env 读取环境变量。
- 通过 process.cwd 和 process.chdir 修改 Node.js 进程的工作目录。
- 通过 process.pid 获取进程 ID。
- 通过 process.nextTick 将某个操作放到下一个 tick 队列中,以实现异步执行。
总之,process 对象提供了与 Node.js 进程相关的许多信息和控制,是 Node.js 编程中不可或缺的一部分。
正则
什么是贪婪模式和非贪婪模式
贪婪匹配就是在进行匹配时的行为模式是多多益善的而不是适可而止的。它们会尽可能地从一段文本的开头一直匹配到这段文本的末尾,而不是从这段文本的开头匹配到碰到第一个匹配时为止。
非贪婪模式是尽可能少的匹配字符。

什么是独占模式
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
如果你用 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯,这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容,匹配失败。如果是贪婪模式 a{1,3} 或非贪婪模式 a{1,3}? 都可以匹配上。

什么是前后查找
向前查找指定了一个必须匹配但不在结果中返回的模式。向前查找实际就是一个子表达式,而且从格式上看也确实如此。从语法上看,一个向前查找模式其实就是一个以?=开头的子表达式,需要匹配的文本跟在=的后面。
被匹配到的:并没有出现在最终的匹配结果里;我们用?=向正则表达式引擎表明:只要找到:就行了,不要把它包括在最终的匹配结果里——用术语来说,就是“不消费”它。
任何一个子表达式都可以转换为一个向前查找表达式,只要给它加上一个?=前缀即可。在同一个搜索模式里可以使用多个向前查找表达式,它们可以出现在模式里的任意位置(而不仅仅是出现在整个模式的开头——就像你们在上面看到的那样)。
向后查找操作符是?<=。
向前查找模式的长度是可变的,它们可以包含.和+之类的元字符,所以它们非常灵活。而向后查找模式只能是固定长度——这是一条几乎所有的正则表达式实现都遵守的限制.

什么是回溯引用
回溯引用指的是模式的后半部分引用在前半部分中定义的子表达式。回溯引用只能用来引用模式里的子表达式(用(和)括起来的正则表达式片段)。回溯引用匹配通常从 1 开始计数(\1、\2,等等)。在许多实现里,第 0 个匹配(\0)可以用来代表整个正则表达式。

常见正则匹配操作符
g在 JavaScript 里,可选的 g(意思是“global”,全局)标志将返回一个包含着所有匹配的结果数组。
iJavaScript 用户可以用 i 标志来强制执行一次不区分字母大小写的搜索。
.字符(英文句号)可以匹配任何一个单个的字符。.字符可以匹配任何单个的字符、字母、数字甚至是.字符本身。
\是一个元字符(metacharacter,表示“这个字符有特殊含义,而不是字符本身含义”)。相应的转义序列是两个连续的反斜杠字符\,相应的转义序列是两个连续的反斜杠字符\。
[]在正则表达式里,我们可以使用元字符[和]来定义一个字符集合。在使用[和]定义的字符集合里,这两个元字符之间的所有字符都是该集合的组成部分,字符集合的匹配结果是能够与该集合里的任意一个成员相匹配的文本。
-为了简化字符区间的定义,正则表达式提供了一个特殊的元字符——字符区间可以用-(连字符)来定义。[0-9]的功能与[0123456789]完全等价
^元字符来表明你想对一个字符集合进行取非匹配。效果将作用于给定字符集合里的所有字符或字符区间,而不是仅限于紧跟在^字符后面的那一个字符或字符区间。
+匹配一个或多个字符(至少一个;不匹配零个字符的情况)。在给一个字符集合加上+后缀的时候,必须把+放在这个字符集合的外面。[0-9]+
*的用法与+完全一样——只要把它放在一个字符(或一个字符集合)的后面,就可以匹配该字符(或字符集合)连续出现零次或多次的情况。
?只能匹配一个字符(或字符集合)的零次或一次出现,最多不超过一次
{}重复次数要用{和}字符来给出——把数值写在它们之间。{}语法还可以用来为重复匹配次数设定一个区间——也就是为重复匹配次数设定一个最小值和一个最大值。这种区间必须以{2, 4}这样的形式给出——{2, 4}的含义是最少重复 2 次、最多重复 4 次。{3, }表示至少重复 3 次,与之等价的说法是“必须重复 3 次或更多次”。
\b用来匹配一个单词的开始或结尾.如果你想表明不匹配一个单词边界,请使用\B
^是几个有着多种用途的元字符之一。只有当它出现在一个字符集合里(被放在[和]之间)并紧跟在左方括号[的后面时,它才能发挥“求非”作用。如果是在一个字符集合的外面并位于一个模式的开头,^将匹配字符串的开头。
$匹配一个字符串的结尾
(? m)用来启用分行匹配模式(multiline mode)的(? m)记号就是一个能够改变其他元字符行为的元字符序列。在使用时,(? m)必须出现在整个模式的最前面
()把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当作一个独立元素来使用。子表达式必须用(和)括起来。
|字符是正则表达式语言里的或操作符,





运维部署
ngnix 怎样配置代理
正向代理:代理的是客户端,相当于 A 想请求 B,但是因为某些原因限制无法直接请求 B,于是找了个中间商 C,把请求委托给 C,C 去请求 B。现实场景一般是 VPN,你访问不了国外网站,得先找个 VPN,让 VPN 帮你去访问
反向代理:代理的是服务端,相当于 A 想请求一件事,找到了委托上 C,C 从可选列表里面找到了 B 完成了请求。A 不认识 B,但认识中间人 C。显示场景是负载均衡,你请求一个服务,负责均衡帮你找一个空闲的服务去访问。
配置主要是修改 server 下的 location,设置 proxy_pass 配置反向代理。
正向代理
比如, 你买束花, 想要给隔壁工位的测试妹子小丽表白. 但是又怕被人家直面拒绝太没面子. 于是你把鲜花委托给平时和小丽一起的测试小伙伴小红. 让她帮忙把花送给小丽. 这就是一个简单的代理过程, 小红作为代理帮你把花送给了小丽, 当然这种情况在现实中并不推荐使用, 因为难以避免中间商赚差价 😂.
在上面的例子中, 你作为客户端(请求方), 想要向服务方(小丽)发起请求. 但是碍于面子你主动找到了第三方(小红)作为代理向服务方发送请求, 这种情况就是常说的正向代理. 正向代理在互联网中的使用主要是科学上网, 你想访问谷歌但是碍于防火墙你只能通过 vpn 服务器作为代理才能访问. 这个时候一般也要找值得信赖的 vpn 厂商, 避免中间商赚差价 😄.
反向代理
关于反向代理的例子, 那就比较多啦. 比如, 孤独的你躺在床上夜不能寐. 于是乎, 拿出手机, 点亮了屏幕, 拨通 10086, 中国移动就会随机分配一个当前处于空闲的客服 MM, 你可以和客服 MM 聊聊天, 问问她家住哪里, 有没有男朋友, 她的微信号, 她的手机号, 星座, 八字.......
在这个例子中, 中国移动就充当了反向代理的角色. 你只需要拨打 10086. 至于会不会分配到 MM 会分配到哪个 MM 在接通之前你都是不知道的. 反向代理在互联网中的使用主要是实现负载均衡. 当你访问某个网站的时候, 反向代理服务器会从当前网站的所有服务器中选择一个空闲的服务器为你响应. 用于均衡每台服务器的负载率.
举个正向代理的例子,我(客户端)没有绿码出不了门,但是朋友(****代理****)有,我(客户端)让朋友(****代理****)去超市买瓶水,而对于超市(服务器)来讲,他们感知不到我(客户端)的存在,这就是正向代理。
举个反向代理例子,我(客户端)让朋友(代理)去给我买瓶水,并没有说去哪里买,反正朋友(代理)买回来了,对于我(客户端)来讲,我(客户端)感知不到超市(服务器)的存在,这就是反向代理。
简单概括下就是,服务器代理被称为反向代理,客户端代理被称为正向代理。
配置示例:
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:8887;
add_header Access-Control-Allow-Origin *;
}
}
}
- proxy_pass,代表要代理的服务器端口
- add_header,了解过 CORS 的朋友应该知道,这个是配置响应头
- listen,代表监听的端口
docker 原理,使用方法,一些关键字的意思
Docker 是一种虚拟化技术,通过容器的方式,它的实现原理依赖 linux 的 Namespace、Control Group、UnionFS 这三种机制。
Namespace 做资源隔离,Control Group 做容器的资源限制,UnionFS 做文件系统的镜像存储、写时复制、镜像合并。
一般我们是通过 dockerfile 描述镜像构建的过程,然后通过 docker build 构建出镜像,上传到 registry。
镜像通过 docker run 就可以跑起来,对外提供服务。
用 dockerfile 做部署的最佳实践是分阶段构建,build 阶段单独生成一个镜像,然后把产物复制到另一个镜像,把这个镜像上传 registry。
这样镜像是最小的,传输速度、运行速度都比较快。
前端、node 的代码都可以用 docker 部署,前端代码的静态服务还要作为 CDN 的源站服务器,不过我们也不一定要自己部署,很可能直接用阿里云的 OSS 对象存储服务了。
理解了 Docker 的实现原理,知道了怎么写 dockerfile 还有 dockerfile 的分阶段构建,就可以应付大多数前端部署需求了。
Docker 提供了大量命令用于管理镜像、容器和服务,命令的统一使用格式为:docker [OPTIONS] COMMAND ,其中 OPTIONS 代表可选参数。需要注意的是 Docker 命令的执行一般都需要获取 root 权限,这是因为 Docker 的命令行工具 docker 与 docker daemon 是同一个二进制文件,docker daemon 负责接收并执行来自 docker 的命令,它的运行需要 root 权限。所有常用命令及其使用场景如下:
dockerfile 是 Docker 用来构建镜像的文本文件,包含自定义的指令和格式,可以通过 build 命令从 dockerfile 中构建镜像,命令格式为:docker build [OPTIONS] PATH | URL | - 。
FROM 指令用于指定基础镜像,因此所有的 dockerfile 都必须使用 FROM 指令开头。常用指令格式为:FROM <image>[:<tag>] [AS <name>]。
MAINTAINER 指令可以用来设置作者名称和邮箱,目前 MAINTAINER 指令被标识为废弃,官方推荐使用 LABEL 代替。
LABEL 指令可以用于指定镜像相关的元数据信息。格式为:LABEL <key>=<value> <key>=<value> <key>=<value> ... 。
ENV 指令用于声明环境变量,声明好的环境变量可以在后面的指令中引用,引用格式为 $variable_name 或 ${variable_name} 。常用格式有以下两种:
ENV <key> <value>:用于设置单个环境变量;ENV <key>=<value> ...:用于一次设置多个环境变量。
EXPOSE 用于指明容器对外暴露的端口号,格式为:EXPOSE <port> [<port>/<protocol>...] ,您可以指定端口是侦听 TCP 还是 UDP,如果未指定协议,则默认为 TCP。
WORKDIR 用于指明工作目录,它可以多次使用。如果指明的是相对路径,则它将相对于上一个 WORKDIR 指令的路径。
COPY 指令的常用格式为:COPY <src>... <dest>,用于将指定路径中的文件添加到新的镜像中,拷贝的目标路径可以不存在,程序会自动创建。
ADD 指令的常用格式为:COPY <src>... <dest>,作用与 COPY 指令类似,但功能更为强大,例如 Src 支持文件的网络地址,且如果 Src 指向的是压缩文件,ADD 在复制完成后还会自动进行解压。
RUN 指令会在前一条命令创建出的镜像基础上再创建一个容器,并在容器中运行命令,在命令结束后提交该容器为新的镜像。它支持以下两种格式:
RUN <command>(shell 格式)RUN ["executable", "param1", "param2"](exec 格式)
CMD 指令提供容器运行时的默认值,这些默认值可以是一条指令,也可以是一些参数。一个 dockerfile 中可以有多条 CMD 指令,但只有最后一条 CMD 指令有效。CMD 指令与 RUN 指令的命令格式相同,但作用不同:RUN 指令是在镜像的构建阶段用于产生新的镜像;而 CMD 指令则是在容器的启动阶段默认将 CMD 指令作为第一条执行的命令,如果用户在 docker run 时指定了新的命令参数,则会覆盖 CMD 指令中的命令。
ENTRYPOINT 指令 和 CMD 指令类似,都可以让容器在每次启动时执行相同的命令。但不同的是 CMD 后面可以是参数也可以是命令,而 ENTRYPOINT 只能是命令;另外 docker run 命令提供的运行参数可以覆盖 CMD,但不能覆盖 ENTRYPOINT ,这意味着 ENTRYPOINT 指令上的命令一定会被执行。如下 dockerfile 片段:
ENTRYPOINT ["/bin/echo", "Hello"]
CMD ["world"]
docker compose 原理和方法
docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。通过 Compose,可以使用 YML 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服务。
Compose 使用的三个步骤:
使用 Dockerfile 定义应用程序的环境。
使用 docker-compose.yml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。
最后,执行 docker-compose up 命令来启动并运行整个应用程序。
启动服务
docker-compose up -d
停止服务
docker-compose down
列出所有运行容器
docker-compose ps
查看服务日志
docker-compose logs
构建或者重新构建服务
docker-compose build
启动服务
docker-compose start
停止已运行的服务
docker-compose stop
重启服务
docker-compose restart
linux 常用的命令,grep,top 等
Linux ls 命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录)。
Linux rm 命令用于删除一个文件或者目录。
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
Linux mv 命令用来为文件或目录改名、或将文件或目录移入其它位置。
Linux touch 命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
which 指令会在环境变量\$PATH 设置的目录里查找符合条件的文件。
Linux cp 命令主要用于复制文件或目录。
Linux cd 命令用于切换当前工作目录至 dirName(目录参数)。
Linux pwd 命令用于显示工作目录。
Linux mkdir 命令用于建立名称为 dirName 之子目录。
Linux rmdir 命令删除空的目录
cat 命令用于连接文件并打印到标准输出设备上
执行 ping 指令会使用 ICMP 传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常
Linux telnet 命令主要用于远端登入。执行 telnet 指令开启终端机阶段作业,并登入远端主机,但是我更经常用它来查看某个远端主机端口是否可访问。telnet [主机名称或IP地址<通信端口>]
Linux grep 命令用于查找文件里符合条件的字符串.grep [文件或目录...]
Linux ps 命令用于显示当前进程 (process) 的状态
| 命令 : 管道命令,管道是一种通信机制,通常用于进程间的通信(也可通过 socket 进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
- 只能处理前一条指令的正确输出,不能处理错误输出
- 管道命令必须要能够接受来自前一个命令的数据成为 standard input 继续处理才行。
Linux kill 命令用于删除执行中的程序或工作。
Linux top 命令用于实时显示 process 的动态。
Linux clear 命令用于清除屏幕
Linux alias 命令用于设置指令的别名
Linux find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名
linux curl 是通过 url 语法在命令行下上传或下载文件的工具软件,它支持 http,https,ftp,ftps,telnet 等多种协议,常被用来抓取网页和监控 Web 服务器状态。
docker 和 k8s 有了解多少
Docker 是一个容器化平台,而 k8s 是 Docker 等容器平台的协调器。
Docker 是用于构建、分发、运行容器的平台和工具。
而 k8s 实际上是一个使用 Docker 容器进行编排的系统,主要围绕 pods 进行工作。Pods 是 k8s 生态中最小的调度单位,可以包含一个或多个容器。
手写实现*
手写防抖 debounce
手写节流 throttle
手写柯里化 currying
手写 new 操作符
手写 call
手写 apply
手写 bind
手写 promise.all
手写 promise.race
手写 promise.finally
手写 promise.allSeteled
手写 deepCopy
手写 es6 继承
手动实现一个 hook
手写一个 event bus
手动实现一个 instanceof
手动实现一个 sleep 函数
手写限制并发数量
手写括号匹配
手写红包算法(注意均衡分配和浮点数计算精度问题)
数组去重
将奇数排在前面,偶数排在后面。要求时间复杂度 O(n)。空间复杂度 O(1)(不能用 splice)
数组转树结构
解析出 URL 中所有的部分
实现一个 compare 函数,比较两个对象是否相同
螺旋矩阵
大数相加
找出出现次数最多的英语单词
节点倒序(将 ul.id=list,将 ul 节点下的 10000 个 li 节点倒序。考虑性能。)
实现一个函数计算 "1+12-31+100-93"
判断链表是否有环
手写 useReducer
手写 useDidMount
手写 useDidUpdate,模拟 componentDidUpdate
手写 usePrevious
爬楼梯
删除单向链表中的某个节点
柯里化
中划线转大写
千位分割
使用 es5 实现 es6 的 let 关键字
提供一个 vdom 对象,写一个 render 函数让它变成一个 DOM
其他
semver 规则
版本格式
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
- 主版本号(major):当你做了不兼容的 API 修改,
- 次版本号(minor):当你做了向下兼容的功能性新增,可以理解为 Feature 版本,
- 修订号(patch):当你做了向下兼容的问题修正,可以理解为 Bug fix 版本。
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
先行版本
当要发布大版本或者核心的 Feature时,但是又不能保证这个版本的功能 100% 正常。这个时候就需要通过发布先行版本。比较常见的先行版本包括:内测版、灰度版本了和 RC 版本。Semver 规范中使用 alpha、beta、rc(以前叫做 gama)来修饰即将要发布的版本。它们的含义是:
- alpha: 内部版本
- beta: 公测版本
- rc: 即 Release candiate,正式版本的候选版本
比如:1.0.0-alpha.0, 1.0.0-alpha.1, 1.0.0-beta.0, 1.0.0-rc.0, 1.0.p-rc.1 等版本。alpha, beta, rc 后需要带上次数信息。
版本发布准则
列举出比较实用的一些规则:
- 标准的版本号必须采用 XYZ 的格式,并且 X、Y 和 Z 为非负的整数,禁止在数字前方补零,版本发布需要严格递增。例如:1.9.1 -> 1.10.0 -> 1.11.0。
- 某个软件版本发行后,任何修改都必须以新版本发行。
- 1.0.0 的版本号用于界定公共 API。当你的软件发布到了正式环境,或者有稳定的 API 时,就可以发布 1.0.0 版本了。
- 版本的优先层级指的是不同版本在排序时如何比较。判断优先层级时,必须把版本依序拆分为主版本号、次版本号、修订号及先行版本号后进行比较。
npm 包依赖
当执行 npm install package -S 来安装三方包时,npm 会首先安装包的最新版本,然后将包名及版本号写入到 package.json 文件中。
比如,通过 npm 安装 react 时:
{
"dependencies": {
"react": "~16.2.0"
}
}
项目对包的依赖可以使用下面的 3 种方法来表示(假设当前版本号是 16.2.0):
兼容模块新发布的补丁版本:~16.2.0、16.2.x、16.2
兼容模块新发布的小版本、补丁版本:^16.2.0、16.x、16
兼容模块新发布的大版本、小版本、补丁版本:*、x
升级补丁版本号:npm version patch
升级小版本号:npm version minor
升级大版本号:npm version major
怎样实现私有化部署
1、配置化
为了摆脱对内部环境的依赖,我们需要对现有系统进行配置化改造,支持对涉及到的基础设施进行配置,这些配置可以手动写在配置文件里、可构建时生成、运行时动态修改。最终做到根据 N 份配置,即可产出针对 N 个公司的部署包。
2、模块化
抽离功能模块,通过『开关』、『配置』进行设置。那模块如何拆分和维护呢?拆分可考虑从『垂直』角度,比如『投放功能』、『个人中心』等;或者从『水平』角度,比如『登录』、『权限』等。
3、标准化
将打包构建流程标准化,可以依据配置来运行不同的构建流程
seo 的理解
SEO 是搜索引擎优化(Search Engine Optimization)的英文缩写,意指在了解搜索引擎自然排名机制的基础上,对网站进行内部及外部的调整优化,改进网站在搜索引擎中的关键词自然排名,获得更多的流量,从而达成网站销售以及品牌建设的预期目标.
SEO 的主要工作是通过了解各类搜索引擎如何抓取互联网页面,如何进行索引以及如何确定其对某一特定关键词的搜索结果排名等技术,来对网页进行相关的优化,使其提高搜索引擎排名,从而提高访问量,最终提升网站的销售能力或宣传能力的技术.增加网站曝光率,提高整站权重,让用户更容易搜索到你的网站,进而带来客观的流量.通过这一策略引流的优点是: 1. 低成本; 2. 持久性; 3. 不需要承担"无效点击"的风险.
这里简单写一点 SEO 的优化方向:
- 网站设计优化
- 网站主标题关键词优化,必须选择好关键词,一般以“一个核心词+三五个长尾词”组合成标题。
- 网站布局的优化。一般来说,企业产品网站,主要是 F 型布局,内容繁多的网站以“扁平结构”布局为主。
- 代码优化,就是板块、栏目代码,最好使用对应的简拼或者全拼。
- 网站内容优化
- 分析栏目关键词,有哪些长尾词,挖掘出来,做成表格的形式。然后,逐个分析长尾词都有哪些内容有关,形成二级长尾词。
- 根据挖掘的长尾词,分析用户需求,挖掘与之有关的内容,整理出文章,发布在网站上,一定确保高质量文章。
为什么说单页面的 SEO 不友好
因为单页面的情况下的页面中的很多内容都是根据匹配到的路由动态生成并展示出来的,而且很多页面内容是通过 ajax 异步获取的,网络抓取工具并不会等待异步请求完成后再行抓取页面内容,对于网络抓取工来说去准确模拟相关的行为获取复合数据是很困难的,它们更擅长对静态资源的抓取和分析.
如何解决单页面 SEO 不友好的问题
预渲染和 SSR(服务端渲染)
服务端渲染原理
服务端渲染 SSR (Server-Side Rendering),是指在服务端完成页面的 html 拼接处理, 然后再发送给浏览器,将不具有交互能力的 html 结构绑定事件和状态,在客户端展示为具有完整交互能力的应用程序。
适用场景
以下两种情况 SSR 可以提供很好的场景支持
- 需更好的支持 SEO 优势在于同步。搜索引擎爬虫是不会等待异步请求数据结束后再抓取信息的,如果 SEO 对应用程序至关重要,但你的页面又是异步请求数据,那 SSR 可以帮助你很好的解决这个问题。
- 需更快的到达时间 优势在于慢网络和运行缓慢的设备场景。传统 SPA 需完整的 JS 下载完成才可执行,而 SSR 服务器渲染标记在服务端渲染 html 后即可显示,用户会更快的看到首屏渲染页面。如果首屏渲染时间转化率对应用程序至关重要,那可以使用 SSR 来优化。
不适用场景
以下三种场景 SSR 使用需要慎重
- 同构资源的处理 劣势在于程序需要具有通用性。结合 Vue 的钩子来说,能在 SSR 中调用的生命周期只有 beforeCreate 和 created,这就导致在使用三方 API 时必须保证运行不报错。在三方库的引用时需要特殊处理使其支持服务端和客户端都可运行。
- 部署构建配置资源的支持 劣势在于运行环境单一。程序需处于 node.js server 运行环境。
- 服务器更多的缓存准备 劣势在于高流量场景需采用缓存策略。应用代码需在双端运行解析,cpu 性能消耗更大,负载均衡和多场景缓存处理比 SPA 做更多准备。
算法*
开放题*
Antd 栅格布局的实现
劫持所有的 a 标签,点击时不发生跳转,而是弹出提示框提示即将跳转到某个网址,点击确认则跳转,点击取消则无操作
两个 promise,分别实现串行和并行形式,只有两个 promise 都返回结果时打印 success,否则打印 fail
长列表的优化方案有哪些?如何设计一个虚拟列表
埋点是如何拦截和上报的
如何实现一个无埋点数据上报
使用 hash 路由时,怎么能再刷新后时候自动滚动到页面上次的锚点位置?
做过哪些性能优化方面的工作
实现一个多级菜单,菜单层级不定
如何监控和排查内存泄漏问题
模拟实现 Java 中的 sleep 函数
使用 var 模拟实现 es6 中的 let 和 const
实现一个数组的 splice 方法(说思路)
A 页面跳转到 B 页面,在 B 页面做的操作传输给 A 页面的方法
Sentry 是如何实现错误监控的
解析 Sentry 源码(二)| Sentry 如何处理错误数据在新窗口打开
将一个 GIF 绘制到 canvas 上是否可行?如果可行,说说你的实现方法。
如果让你搭建一个项目,你会使用哪些技术方案进行组合?
如何做技术选型?
手写实现一个图片懒加载
1、到指定高度加载图片
2、考虑重排和重绘
3、考虑性能
4、先加载缩略图,再加载完整的图
5、注意图片加载容错情况
编写一个函数,传入一个 promise 和数字 n,n(s)内 promise 没有返回结果,直接 reject
了解 SSR 吗
说一下深拷贝要注意的点
前端发展方向设想
如何设计一个类似于 elementui 这样的可以单包发布,也可以多包发布的框架
如果让你设计一个单测框架,你怎么设计?
如何实现模块懒加载?import 语法是如何做的
如何设计一个单点登录方案?
用过哪些设计模式?分别说说它们的使用场景和应用案例?你觉得使用设计模式给你带来了什么好处?
从 A 页面跳转到 B 页面,再返回 A 页面时,如何让 A 页面保持上一次的状态
了解 Vue3 和 React18 吗
Nginx 和 node 中间件代理的区别
Node 中间件主要是解决什么问题
说一下你做过的最有收获的项目。描述一下系统所承载的功能、目标以及这个系统能解决什么问题?
你怎么看待 Typescript 中大量存在 any 的现象?面对这样的场景你将有什么样的想法和行动?
移动端怎么做响应式布局
软技能*
有什么优点和缺点
未来职业规划
为什么选择我们公司
最近在关注什么新技术
怎样管理团队
怎么看待加班